This post is part of the second annual C# Advent. Check out the home page for up to 50 C# blog posts in December 2018!
In this post I describe a characteristic about GetHashCode() that was new to me until I was bitten by it recently - that calling GetHashCode() on a string gives a different value each time you run the program in .NET Core!
In this post I show the problem in action, and how the .NET Core GetHashCode() implementation differs from .NET Framework. I then look at why that's the case and why it's a good thing in general. Finally, if you need to ensure GetHashCode() gives the same value every time you run your program (spoiler: generally you don't), then I provide an alternative implementation you can use in place of the built-in GetHashCode().
tl;dr; I strongly suggest reading the whole post, but if you're just here for the deterministic
GetHashCode(), then see below. Just remember it's not safe to use in any situations vulnerable to hash-based attacks!
The behaviour: GetHashCode() generates a different random value for every program execution in .NET Core
The easiest way to understand the behaviour I'm describing is to see it in action. Take this very simple program that calls GetHashCode() on a string twice in succession
using System;
static class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!".GetHashCode());
Console.WriteLine("Hello World!".GetHashCode());
}
}
If you run this program on .NET Framework then every time you run the program you'll get the same value:
> dotnet run -c Release -f net471
-1989043627
-1989043627
> dotnet run -c Release -f net471
-1989043627
-1989043627
> dotnet run -c Release -f net471
-1989043627
-1989043627
In contrast, if you compile the same program for .NET Core, you get the same value for every call to GetHashCode() within the same program execution, but a different value for different program executions:
> dotnet run -c Release -f netcoreapp2.1
-1105880285
-1105880285
> dotnet run -c Release -f netcoreapp2.1
1569543669
1569543669
> dotnet run -c Release -f netcoreapp2.1
-1477343390
-1477343390
This took me totally by surprise, and was the source of a bug that I couldn't get my head around without this knowledge (I'll come to that later).
Since when was this a thing?!
I was gobsmacked when I discovered this behaviour, so I went rooting around in the docs and on GitHub. Sure enough, right there in the docs, this behaviour is well documented: (emphasis mine)
The hash code itself is not guaranteed to be stable. Hash codes for identical strings can differ across .NET implementations, across .NET versions, and across .NET platforms (such as 32-bit and 64-bit) for a single version of .NET. In some cases, they can even differ by application domain. This implies that two subsequent runs of the same program may return different hash codes.
In many ways, the interesting thing about this behaviour is that I've never run into it before. My first thought was that I must have depended on this behaviour in .NET Framework, but after a bit more consideration, I couldn't think of a single instance where this was the case. As it turns out, I've always used GetHashCode() in the manner for which it was designed. Who would have thought it!
The key point is that the hash codes are deterministic for a given program execution, that means the only time it'll be an issue is if you're saving the hash code outside of a process, and loading it into another one. That explains the subsequent comment in the documentation:
As a result, hash codes should never be used outside of the application domain in which they were created, they should never be used as key fields in a collection, and they should never be persisted.
When I discovered the behaviour I was trying to save the output of string.GetHashCode() to a file, and load the values in another process. This is clearly a no-no given the previous warning!
As a bit of an aside, it's actually possible to enable the randomised hash code behaviour in .NET Framework too. To do so, you enable the <UseRandomizedStringHashAlgorithm> element in the application's app.config:
<?xml version ="1.0"?>
<configuration>
<runtime>
<UseRandomizedStringHashAlgorithm enabled="1" />
</runtime>
</configuration>
This enables the same randomization code used by .NET Core to be used with .NET Framework. In fact, if you look at the .NET Framework 4.7.2 Reference Source for string.cs, you'll see that GetHashCode() looks like the following:
public override int GetHashCode() {
#if FEATURE_RANDOMIZED_STRING_HASHING
if(HashHelpers.s_UseRandomizedStringHashing)
{
return InternalMarvin32HashString(this, this.Length, 0);
}
#endif // FEATURE_RANDOMIZED_STRING_HASHING
// ...deterministic GetHashCode implementation
}
The call to InternalMarvin32HashString calls into native code to do the randomized hashing. The Marvin algorithm it uses is actually patented, but if you're interested you can see a C# version here (it's part of the Core CLR implementation). I believe the randomized hashing feature was introduced in .NET Framework 4.5 (but don't quote me on that!).
Once I'd figured out that randomized hashing was my concern, I naturally checked to see if it could be disabled. It turns out in .NET Core it's always enabled. But why?
Why is randomizing GetHashCode() a good thing?
The answer to this question was touched on by Stephen Toub in a comment on an issue I discovered while reading around my problem:
Q: Why .NET Core utilize randomized string hashing?
A: Security, prevention against DoS attacks, etc.
This piqued my interest - what were these DoS attacks, and how do they play into GetHashCode()?
As far as I can see, this harks back to a talk given at the end of 2011 at the 28th Chaos Communication Congress (28C3), in which a whole range of languages were shown to be susceptible to a technique known as "hash flooding". If you're interested in the details, I strongly recommend checking out the video of the talk which I was impressed to find on You Tube. It definitely went over my head in places, but I'll try and explain the crux of it here.
Hash tables and hash flooding
Disclaimer: I don't have a Computer Science degree, so I may well be a bit fast and loose with the correct terminology here. Hopefully this description of the vulnerability makes sense either way.
Hash tables are a data structure that allow you to store a value using a key. The hash table itself consists of many buckets. When you want to insert a value in a hash table you use a hash function to calculate which bucket the key corresponds to, and store the key-value pair in there.

In the best case, inserting a value into a hash table is an O(1) operation, i.e. it takes constant time. Ideally a hash function distributes the keys among the buckets evenly, such that each bucket has at most 1 value stored in it. If so, it doesn't matter how many values you store, it always takes the same amount of time to store a value. Even better, deleting and retrieving a value are also O(1).
Where things fall down is if two different keys hash to the same bucket. This is a relatively common occurrence: typical hash functions used with hash tables are designed to be fast, and to give a fixed output. They try to give a low probability of collisions, but they're not cryptographic hash functions (these provide stronger guarantees. See 7:28 in the YouTube video for more discussion of this).
When you get a hash collision in a hash table, typical implementations store the key-value pairs as a linked list inside the bucket. When you're inserting a new value and you get a collision, the hash table checks each of the elements to see if it already exists in the bucket. If not, then it adds the element to the end of the list.

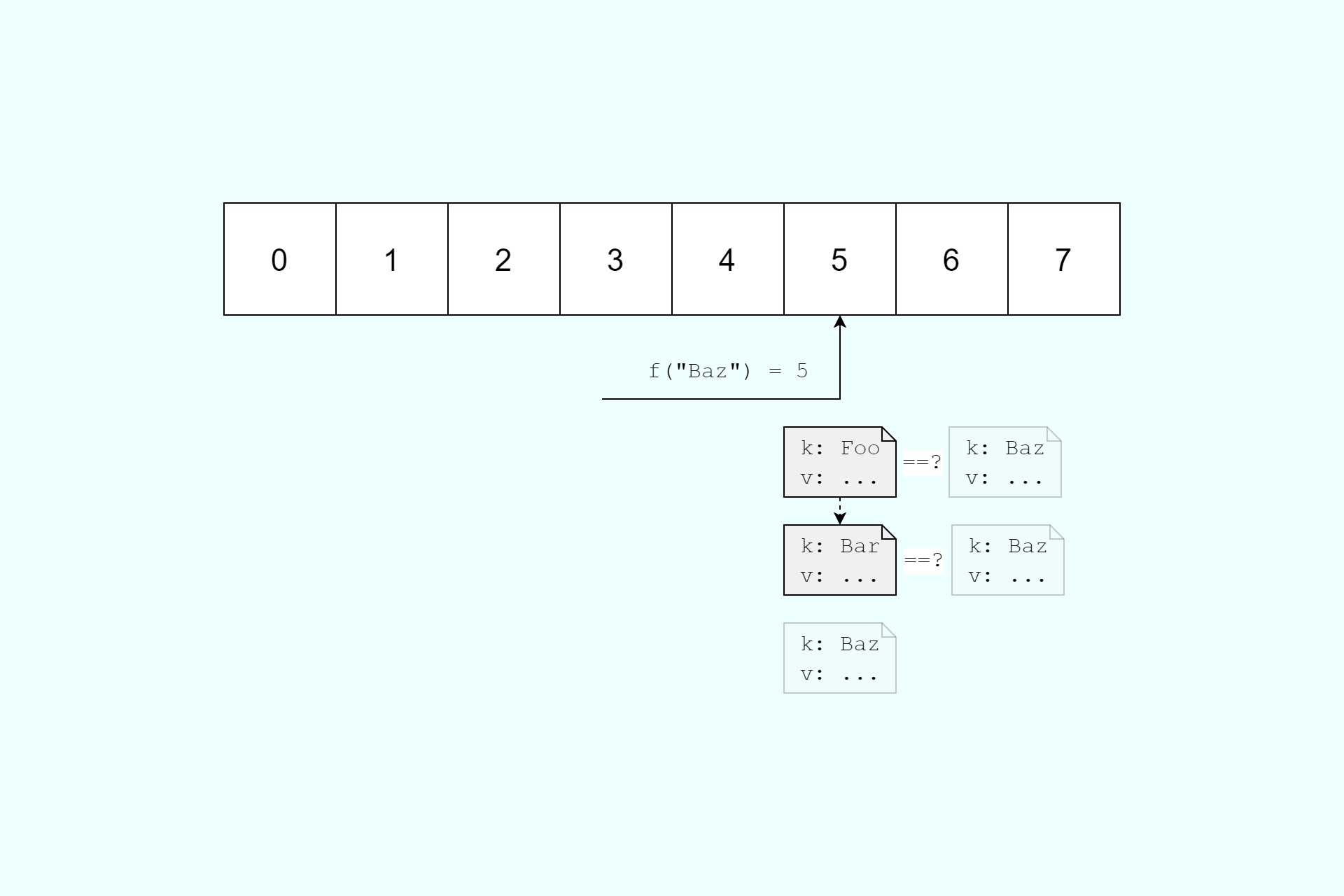
This is fine when you only get the occasional collision, but what if every lookup results in a collision. Imagine your hash table is asked to insert 10,000 elements, each of which has a different key, but which all hash to the same bucket.
The first element, Foo is inserted quickly, as there's no previous values in the bucket. The second element, Bar takes a little longer as it's first compared to the existing Foo element stored in the bucket's linked list, before being added to the end of the list. The third element Baz takes even longer, as it's compared to each of the previously hashed values before being added to the list.

Each individual insertion takes O(n) time, as it must be compared to every existing value in the linked list. If you can find values Foo, Bar, Baz etc. which all hash to the same value, then the time to insert those n elements is polynomial O(n²) time. That's a far cry from the O(1) assumed-best-case performance, and is the essence of the hash flooding attack.
Hash flooding and web applications
So that explains the attack itself, but why is it an issue? For two main reasons:
- A lot of applications use hash tables extensively, including web applications
- It's not very hard to find hash collisions if you're looking for them (see the YouTube video section on hash functions)
In their talk, Alexander Klink and Julian Wälde describe attacks on multiple web application frameworks, including ASP.NET (non-Core - this is 2011 remember!). Most web application frameworks (including ASP.NET) read an HTTP POST's parameters into a hash table. In ASP.NET, the parameters for a request are available as a NameValueCollection (a hash table) on HttpContext.Request.Form.
Using knowledge of the GetHashCode() implementation, it's possible to calculate (or identify using brute force) a wide array of values that will collide. From there you can craft a malicious HTTP POST. For example, if Foo, Bar, Baz all give the same GetHashCode() value, you can create a malicious post that uses all of these parameters in the body:
POST / HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 9999999
Foo=1&Bar=1&Baz=1.... + Lots more collisions
When the ASP.NET application tries to create the HttpContext object, it dutifully decomposes the body into a NameValueCollection, triggering the hash flooding attack due to the hash collisions.
For a bit of perspective here, when Alexander and Julian tested the attack with 4MB of post data (the limit at the time), it took the CPU ~11 hours to complete the hashing. 😱 O(n²) is a bitch…
Obviously there were built-in mitigations to this sort of runaway, even at the time; IIS would limit you to 90s of CPU time. But it shouldn't be hard to see the potential for denial of service attacks.
So there you have it. It seems Microsoft took this research and vulnerability very seriously (unlike the PhP folks by the sound of it!). They initially limited the number of parameters you can pass in a request, to reduce the impact of the issue. Subsequently they introduced the randomised GetHashCode() behaviour we've been discussing.
What if you need GetHashCode() to be deterministic across program executions?
Which brings me full circle to the problem. I wanted a deterministic GetHashCode() that would work across program executions. If you find yourself in a similar situation, you should maybe stop going down that line.
Do you really need it?
If the GetHashCode() result is going to be exposed to the outside world in a manner that leaves you open to hash flooding, you should probably rethink your approach. In particular, if user input is being added to a hash table (just like the Request.Form property), then you're vulnerable to the attack.
As well as the attack I've discussed here, I strongly suggest reading some of Eric Lippert's posts on GetHashCode(). They're old, but totally relevant. I wish I'd found them earlier in my investigation!
If you're really, really, sure you want a deterministic GetHashCode() for strings then you'll have to do your own thing.
A deterministic GetHashCode() implementation
In my case, I'm Pretty Sure™ that I'm ok to use a deterministic GetHashCode(). Essentially, I'm calculating the hash code for a whole bunch of strings "offline", and persisting these values to disk. In the application itself, I'm comparing a user provided string to the existing hash codes. I'm not inserting these values into a hash table, just comparing them to the already "full" hash table. so I think I'm good.
Please tell me if I'm wrong!
Coming up with a deterministic GetHashCode() implementation was an interesting dive into all sorts of code bases:
- The .NET Framework 4.7.1 reference source for
string.GetHashCode() - An unmerged PR that fixes a long-standing bug in the .NET Framework 64-bit version of
string.GetHashCode() - A simplified, non-randomised version of string.GetHashCode used in CoreFX. This explicitly calls out the implementation as vulnerable to hash-based attacks.
- A managed version of the 64-bit version of
string.GetHashCode()from Stack Overflow.
In the end, I settled on a version somewhere between all of them. I didn't want to use unsafe code in my little application (like the CoreFX version uses), so I created a managed version instead. The following hash function is what I finally settled on:
static int GetDeterministicHashCode(this string str)
{
unchecked
{
int hash1 = (5381 << 16) + 5381;
int hash2 = hash1;
for (int i = 0; i < str.Length; i += 2)
{
hash1 = ((hash1 << 5) + hash1) ^ str[i];
if (i == str.Length - 1)
break;
hash2 = ((hash2 << 5) + hash2) ^ str[i + 1];
}
return hash1 + (hash2 * 1566083941);
}
}
This implementation is very similar to the links provided above. I'm not going to try and explain it here. It does some maths y'all. One interesting point for those who haven't seen it before is the unchecked keyword. This disables overflow-checking for the integer arithmetic done inside the function. If the function was executed inside a checked context, and didn't use the unchecked keyword, you might get an OverflowException at runtime:
checked
{
var max = int.MaxValue;
var val = max + 1; // throws an OverflowException in checked context
}
We can now update our little test program to use the GetDeterministicHashCode() extension method:
using System;
static class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!".GetDeterministicHashCode());
Console.WriteLine("Hello World!".GetDeterministicHashCode());
}
}
And we get the same value for every execution of the program, even when running on .NET Core:
> dotnet run -c Release -f netcoreapp2.1
1726978645
1726978645
> dotnet run -c Release -f netcoreapp2.1
1726978645
1726978645
One thing I'm not 100% on is whether you'd get the same value on architectures other than 64-bit. If anyone knows the answer for sure I'd be very interested, otherwise I need to go and test some!
As I stated previously, generally speaking you shouldn't need to use this code. You should only use it in very specific circumstances where you know you aren't vulnerable to hash-based attacks.
If you're looking to implement
GetHashCode()for other types, take a look at Muhammad Rehan Saeed's post. He describes a helper struct for generating hash codes. He also discusses the built-inHashCodestruct in .NET Core 2.1.
Summary
This post was representative of my journey into understanding string.GetHashCode() and why different executions of a program will give a different hash code for the same string. Randomized hash codes is a security feature, designed to mitigate hash flooding. This type of attack uses knowledge of the underlying hash function to generate many collisions. Due to typical hash table design, this causes insert performance to drop from O(1) to O(n²), resulting in a denial of service attack.
In some circumstances, where your hash table will not be exposed to hash-based attacks like this, it may be desirable to have a stable/deterministic hash function. In this post I showed one such possible hash function, based on implementations in .NET Framework and CoreFX. This hash function ensures you get the same hash code for a given string, across program executions.
Use it wisely - with great power…