If you're coming from SQL Server, PostgreSQL can seem very pedantic about column names. In SQL Server, case sensitivity doesn't matter for column names, so if a column is named FirstName, then firstName, firstname, or even FIRSTNAME are all valid. Unfortunately, the only way to query that column in PostgreSQL, is using "FirstName" (including the quotes). Using quotes like this can get tiresome, so it's a common convention to use "snake_case" for columns and tables; that is, all-lowercase with _ to separate words e.g. first_name.
If you'd like a bit more background, or you're working with EF Core, I discuss this in greater depth in my previous post.
In the previous post, I described how you can customise EF Core's naming conventions to use snake_case. This ensures all tables, columns, and indexes are generated using snake_case, and that they map correctly to the EF Core entities. To do so, I created a simple ToSnakeCase() extension method that uses a regex to convert "camelCase" strings to "snake_case".
One of the comments on that post from Alex was interested in how to use this method to achieve the same result for Dapper commands:
I'm using Dapper in many parts of my application and i used to name my table in queryies using nameof(), for example: $"SELECT id FROM {nameof(EntityName)}".
That way, i could rename entitie's names without replacing each sql query ...
So the naive approach will be to replace it with "SELECT id FROM {nameof(EntityName).ToSnakeCase()}" but, each time the query is "build", the SnakeCase (and the regexp) will be processed, so it'll not be very good in term of performance. Did you know a better approach to this problem ?
Using the nameof() operator with Dapper
Dapper is a micro-ORM that provides various features for querying a database and mapping the results to C# objects. It's not as feature rich as something like EF Core, but it's much more lightweight, and so usually a lot faster. It uses a fundamentally different paradigm to most ORMs: EF Core lets you interact with a database without needing to know any SQL, whereas you use Dapper by writing hand-crafted SQL queries in your app.
Dapper provides a number of extension methods on IDbConnection that serve as the API surface. So say you wanted to query the details of a user with id=123 from a table in PostgreSQL. You could use something like the following:
IDbConnection connection;// get a connection instance from somewherevar sql ="SELECT id, first_name, last_name, email FROM users WHERE id = @id";var user = connection.Query<User>(sql,new{ id =123}).SingleOrDefault();
The ability to control exactly what SQL code runs on your database can be extremely useful, especially for performance sensitive code. However there are some obvious disadvantages when compared to a more fully featured ORM like EF Core.
One of the most obvious disadvantages is the possibility for typos in your SQL code. You could have typos in your column and table names, or you could have used the wrong syntax. That's largely just the price you pay for this sort of "lower-level" access, but there's a couple of things you can do to reduce the problem.
A common approach, as described in Alex's comment is to use string interpolation and the nameof() operator to inject a bit of type safety into your SQL statements. This works well when the column and tables names of your database correspond to property and class names in your program.
For example, imagine you have the following User type:
publicclassUser{publicint Id {get;set;}publicstring Email {get;set;}publicstring FirstName {get;set;}publicstring LastName {get;set;}}
If your column names match the property names of User (for example property Id corresponds to column name Id), then you could query the database using the following:
var id =123;var sql = $@"
SELECT {nameof(User.Id)}, {nameof(User.FirstName)}, {nameof(User.LastName)}
FROM {nameof(User)}
WHERE {nameof(User.Id)} = @{nameof(id)}";var user = connection.Query<User>(sql,new{ id }).SingleOrDefault();
That all works well as long as everything matches up between your classes and your database schema. But I started off this post by describing snake_case as a common convention of PostgreSQL. Unless you also name your C# properties and classes using snake_case (please don't) you'll need to use a different approach.
var id =123;var sql = $@"
SELECT {nameof(User.Id).ToSnakeCase()},
{nameof(User.FirstName).ToSnakeCase()},
{nameof(User.LastName).ToSnakeCase()}
FROM {nameof(User).ToSnakeCase()}
WHERE {nameof(User.Id).ToSnakeCase()} = @{nameof(id)}";var user = connection.Query<User>(sql,new{ id }).SingleOrDefault();
Unfortunately, calling a regex for every column in every query is pretty wasteful and unnecessary. Instead, I often like to create "schema" classes that just define the column and table names in a central location, reducing the opportunity for typos:
Each property of the User class has a corresponding getter-only static property in the UserSchema.Columns class that contains the associated column name. You can then use this schema class in your Dapper SQL queries without performance issues:
var id =123;var sql = $@"
SELECT {UserSchema.Columns.Id)},
{UserSchema.Columns.FirstName},
{UserSchema.Columns.LastName}
FROM {UserSchema.Table}
WHERE {UserSchema.Columns.Id} = @{nameof(id)}";var user = connection.Query<User>(sql,new{ id }).SingleOrDefault();
I've kind of dodged the question at this point - Alex was specifically looking for a way to avoid having to hard code the strings "first_name", "last_name" etc; all I've done is put them in a central location. But we can use this first step to achieve the end goal, by simply replacing those hard-coded strings with their nameof().ToSnakeCase() equivalents:
Because we used getter-only properties with an initialiser , the nameof().ToSnakeCase() expression is only executed once per column. No matter how many times you use the UserSchema.Columns.Id property in your SQL queries, you only take the regular expression hit once.
Personally, I feel like this strikes a good balance between convenience, performance, and safety. Clearly creating the *Schema tables involves some duplication compared to using hard-coded column names, but I like the strongly-typed feel to the SQL queries using this approach. And when your column and class names don't match directly, it provides a clear advantage over trying to use the User class directly with nameof().
Configuring Dapper to map snake_case results
The schema classes shown here are only one part of the solution to using snake_case column names with Dapper. The *Schema approach helps avoid typos in your SQL queries, but it doesn't help mapping the query results back to your objects.
By default, Dapper expects the columns returned by a query to match the property names of the type you're mapping to. For our User example, that means Dapper expects a column named FirstName, but the actual column name is first_name. Luckily, fixing this is a simple one-liner:
With this statement added to your application, you'll be able to query your PostgreSQL snake_case columns using the *Schema classes, and map them to your POCO classes.
Summary
This post was in response to a comment I received about using snake_case naming conventions with Dapper. The approach I often use to avoid typos in my SQL queries is to create static "schema" classes, that describe the shape of my tables. These classes can then be used in SQL queries with interpolated strings. The properties of the schema classes can use convenience methods such as nameof() and ToSnakeCase() as they are only executed once, instead of on every reference to a column.
If you're using this approach, don't forget to set Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true so you can map your query objects back to your POCO classes!
Virtually all web applications use some form of user analytics to determine which aspects of an application are popular and which are causing issues for users. Probably the most well known is Google Analytics but there are other similar services that offer additional options and features. One such service is Segment which can act as a funnel into other analytics engines such as Google Analytics, Mixpanel, or Salesforce.
In this post I show how you can add the Segment analytics.js library to your ASP.NET Core application, to provide analytics for your application.
I'm only looking at how to add client-side analytics to a server-side rendered ASP.NET Core application i.e. an MVC application using Razor. If you want to add analytics to an SPA app that uses Angular for example, see the Segment documentation.
Client-side vs. Server-side tracking
Segment supports two types of tracking: client-side and server-side. The difference should be fairly obvious:
Client-side tracking uses JavaScript to make calls to the Segment API, to track page views, sign-ins, page clicks etc.
Server-side tracking happens on the server. That means you can send data that's only available on the server, or that you wouldn't want to send to a client.
Whether you want server-side tracking, client-side tracking, or both, depends on your requirements. Segment has a good breakdown of the pros and cons of both approaches on their docs.
In this post I'm going to add client-side tracking using Segment to an ASP.NET Core application.
Once you have configured your account, you'll need to obtain an API key for your app. If you haven't already, create a new source by clicking Add Source on the Home screen. Select the JavaScript source, and enter all the required fields.
Once the source is configured, view the API keys for the source, and make a note of the Write key. This is the API key you will provide when calling the Segment API.
With the Segment side complete, we can move on to your application. Even though we're doing client-side tracking here, we need to do some work on the server.
Configuring the server-side components
Given I said I'm only looking at client-side tracking, you might be surprised to know you need any server-side components. However, if you're rendering your pages server side using Razor, you need a way of passing the API keys, and the user's ID to the JavaScript code. The easiest way is to write the values directly in the JavaScript rendered in your layout.
Adding the configuration
First thing's first, you need somewhere to store the API key. The simplest place would be to dump it in appsettings.json, but you shouldn't put values like API keys in there. The Segment key isn't really that sensitive (we'll be exposing it in JavaScript anyway) but out of principle, it just shouldn't be there.
Assuming you're using the default web host builder (or similar) this value will be added to your IConfiguration object. Create a strongly-typed settings object for good measure:
Now you've got the Segment API key available in your application, you can look at rendering the analytics.js JavaScript code.
Rendering the analytics code in Razor
The Segment JavaScript API is exposed as the analytics.js library. This library lets you send all sorts of analytics to Segment from a client, but at it's simplest you just need to do three things:
Load the analytics.js library
Initialise the library with your API key
Call page() to track a page view.
You can read about this and all the other options available in the quickstart guide in Segment's documentation. I'm going to create a partial view called _SegmentPartial.cshtml, for rendering the JavaScript snippet. You can add this partial to your application by adding the following to your _Layout.cshtml.
There's a couple of things to note here. We're injecting the API key using the strongly-typed SegmentSettings options object directly into the view, and then writing the key out using @apiKey. This will HTML encode the output, but given we know the apiKey is alphanumeric, this shouldn't be an issue.
This is a special case as we know the key is not coming form user input and contains a known set of safe values, but it's bad practice really. Generally speaking you should use one of the techniques discussed in the docs to inject values into JavaScript code.
If you reload your website, you should see the JavaScript snippet rendered to the page, and if you look in the debugger of your Segment Source you should see a tracking event for the page:
Associating page data with a user
You've now got basic page analytics, but what if you want to send more information. The analytics.js library lets you track a variety of different properties and events, but often one of the most important is tracking individual users. This is extremely powerful as it lets you track a user's flow through your application, and where they hit stumbling blocks for example.
User tracking and privacy is obviously a hot-topic at the moment, but I'm going to just avoid that for now. You should always take into consideration your user's expectation of privacy, especially with the recent GDPR legislation.
To associate multiple analytics.page() and analytics.track() calls with a specific user, you must first call analytics.identify() in your page. You should add this call just after the analytics.load() call and just before analytics.page() in our JavaScript snippet.
In order to track a user, you need a unique identifier. If a user is browsing anonymously, then Segment will assign an anonymous ID automatically; you don't need to do anything. However, if a user has logged in to your app, you can associate your Segment data with them by providing a unique ID.
In this example, I'm going to assume you're using a default ASP.NET Core Identity setup, so that when a user logs in to your app, a ClaimsPrincipal is set which contains two claims:
ClaimTypes.NameIdentifier: the unique identifier for the user
ClaimTypes.Name : the name of the user (often an email address)
For privacy/security reasons, you may not want to expose the unique id of your users to a third-party API (and the client browser). You can work around this by creating an additional unique GUID for each user, and adding an additional Claim to the ClaimsPrincipal on login. That's beyond the scope of this post, so I'll just use the two main claims for now.
The following Razor uses the User property on the page to check if the current user is authenticated. If they are, it extracts the id and email of the principal, and creates an anonymous "traits" object, with the details about the user we're going to send to Segment. Finally, after loading the snippet and assigning the API key, we call analytics.identify(), passing in the user id, and the serialized traits object.
@inject IOptions<SegmentSettings> Settings
@using System.Security.Claims
@using System.Text.Encodings.Web
@using System.Security.Claims
@{
var apiKey = Settings.Value.ApiKey
var isAuthenticated = User?.Identity?.IsAuthenticated ?? false;
if (isAuthenticated)
{
var id = User.Claims.First(x => x.Type == ClaimTypes.NameIdentifier).Value;
var name = User.Claims.First(x => x.Type == ClaimTypes.Name).Value;
var traits = new {username = name, email = name};
}
}
<scripttype="text/javascript">!function(){var analytics=window.analytics=window.analytics||[];if(!analytics.initialize)if(analytics.invoked)window.console&&console.error&&console.error("Segment snippet included twice.");else{analytics.invoked=!0;analytics.methods=["trackSubmit","trackClick","trackLink","trackForm","pageview","identify","reset","group","track","ready","alias","debug","page","once","off","on"];analytics.factory=function(t){returnfunction(){var e=Array.prototype.slice.call(arguments);e.unshift(t);analytics.push(e);return analytics}};for(var t=0;t<analytics.methods.length;t++){var e=analytics.methods[t];analytics[e]=analytics.factory(e)}analytics.load=function(t,e){var n=document.createElement("script");n.type="text/javascript";n.async=!0;n.src=("https:"===document.location.protocol?"https://":"http://")+"cdn.segment.com/analytics.js/v1/"+t+"/analytics.min.js";var o=document.getElementsByTagName("script")[0];o.parentNode.insertBefore(n,o);analytics._loadOptions=e};analytics.SNIPPET_VERSION="4.1.0";
analytics.load("@apiKey");
@if(isAuthenticated){
@:analytics.identify('@id', @Json.Serialize(traits));}
analytics.page();}}();</script>
Now if you login to your application, you should see an additional identify call in the Segment Debugger, containing the id and the additional traits. Actions taken by that user will be associated together, so you can easily follow the steps a user took before they ran into an issue for, example.
There's rather more logic in this partial than I like to see in a view so I suggest encapsulating this logic somewhere else, perhaps by converting it to a ViewComponent.
There's many more things you can do to provide analytics for your application, but I'll leave you to check out the excellent Segment documentation if you want to do more.
Summary
In this post I showed how you can use a Segment's analytics.js library to add client-side analytics to your ASP.NET Core application. Adding analytics is as simple as including a JavaScript snippet and providing an API key. I also showed how you can associate page actions with users by reading Claims from the ClaimsPrincipal and calling analytics.identify().
In this post I'll discuss a technique I use occasionally to ensure that an ASP.NET Core app is able to start correctly, as part of a continuous integration (CI) build pipeline. These "smoke tests" provide an initial indication that there may be something wrong with the build, which may not be caught by other tests.
How useful you find these test will vary depending on your individual app, your integration tests, your build pipeline, and your deployment process. This post is not meant to be prescriptive, it just describes one tool I use in some situations to prevent bad builds being published.
Building and testing ASP.NET Core apps in Docker
One of the selling points of ASP.NET core is the ability to build and run your applications on virtually any operating system. In my case, I typically build ASP.NET Core applications on Windows, and publish them as Docker containers to a private Docker registry as part of the CI build process. Once the application has been automatically tested, it is deployed to a Kubernetes cluster by the CI build system.
Different testing strategies
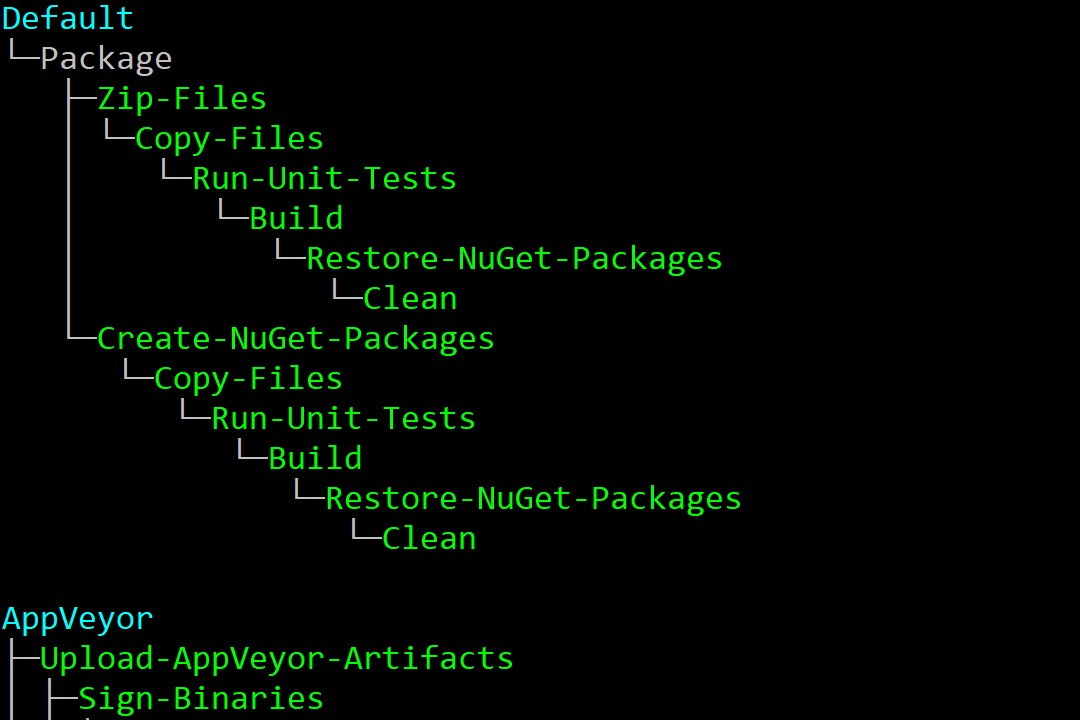
I've previously written several posts about building ASP.NET Core apps in Docker. I typically use Cake to build and publish my apps as described in this post. A key part of the build process is running unit tests, to verify that your app is working correctly. If any of the unit tests fail, the whole build process should automatically fail, and the deployment of your app should halt.
As well as unit tests, you can also write functional/integration tests for your application. ASP.NET Core 2.1 included the Microsoft.AspNetCore.Mvc.Testing NuGet package to help with functional testing of MVC apps, as described in the documentation. This package simplifies many aspects of functional testing that were non-obvious, and problematic (especially related to Razor compilation).
Functional tests are a great way to test whole "slices" of your application. Unlike unit tests, in which you're often testing a single class or method in isolation, functional tests focus on testing multiple components in combination. For example, you could use functional tests to confirm that when a protected Web API controller is invoked via an HTTP request, unauthenticated users receive a 401 Unauthorized response, while authenticated (and authorized) users receive a 200 Ok response.
Unfortunately, depending on the design of your application, functional tests could prove difficult to write. I find one of the biggest challenges is when an app requires a database. Depending on which libraries you are using in your app, providing a stub/mocked database can prove a challenge. EF Core has good support for using in-memory databases, which are perfect for this situation. If you're using Dapper however, the solution can be less clear, with no easy way (that I'm aware of!) to replace the underlying database layer.
Smoke tests for testing app startup
Given that integration testing is not always simple, I wanted a simple way to test that my apps would at least start. Unit tests are great, but pretty much by definition will not catch errors related to how your app is composed. For example, unit tests won't typically be able to tell if you have dependency injection configuration errors in your app.
The solution I settled on involves running the application in a docker container, as part of the CI build process, and calling a basic status/health check endpoint. The act of starting the application will potentially catch any basic configuration issues, while not requiring the presence of infrastructure elements (like the database).
Obviously, by design, this is not a complete test of the app. I'm trying to confirm that I've not made any mistakes that prevent the app running. If you are already running integration tests, then adding this smoke test probably isn't going to tell you a lot, but then it won't (shouldn't?) hurt!
Docker and Kubernetes both include the concept of a readiness/liveness probe for applications. The smoke-test approach essentially runs the readiness probe as part of the build process, instead of waiting for deploy time.
At this point I'll assume you already have the following configured:
An ASP.NET Core app, running in Docker
A CI build pipeline, which produces runnable Docker images of your app. The pipeline must also be capable or running Docker containers
A status/health check endpoint in your app that does not require additional infrastructure (i.e. a database)
Once you have all these in place, adding the smoke test as part of your CI build pipeline is relatively simple. In the next section I'll describe the script I use, and how to call it.
The smoke test Bash script
The complete Bash script for running smoke tests is shown below. I'll walk through the script in detail afterwards, as it's quite verbose, but a large amount of the script is boilerplate for setting variables and capturing errors etc, so try not to feel too overwhelmed!
#!/bin/bash# treat undefined variables as an error, and exit script immediately on errorset -eux
APP_NAME="$1"
APP_IMAGE="$2"
TEST_PATH="$3"
SMOKE_TEST_IMAGE="$APP_NAME-smoke-test"
TEST_PORT=80
MAX_WAIT_SECONDS=30
# kill any lingering test containers
docker kill$SMOKE_TEST_IMAGE||true
docker run -d --rm \
--name $SMOKE_TEST_IMAGE \
-e ASPNETCORE_ENVIRONMENT=Testing \
$APP_IMAGE# wait for the port to be available until nc -z $(docker inspect --format='{{.NetworkSettings.IPAddress}}' $SMOKE_TEST_IMAGE)$TEST_PORTdoecho"waiting for container to startup..."sleep 1.0
((MAX_WAIT_SECONDS--))#decrementif[$MAX_WAIT_SECONDS -le 0 ];thenecho"Docker smoke test failed, port $TEST_PORT not available"
docker kill$SMOKE_TEST_IMAGE||trueexit -1
fidone# hit the status endpoint (don't kill script on failure)set +e
docker exec -i $SMOKE_TEST_IMAGEwget http://localhost:$TEST_PORT$$TEST_PATH# capture the return code
result=$?# Reenable exit on errorset -e
# kill the test container
docker kill$SMOKE_TEST_IMAGEif[$result -ne 0 ];thenecho"Docker smoke test failed"elseecho"Docker smoke test passed"fiexit$result
To try and make it more manageable, I'll walk through the script, and describe the purpose of each section.
Walking through the script
The first section of the script is some standard boilerplate, and general configuration:
#!/bin/bash# treat undefined variables as an error, and exit script immediately on errorset -eux
APP_NAME="$1"
APP_IMAGE="$2"
TEST_PATH="$3"
SMOKE_TEST_IMAGE="$APP_NAME-smoke-test"
TEST_PORT=80
MAX_WAIT_SECONDS=30
# kill any lingering test containers
docker kill$SMOKE_TEST_IMAGE||true
In this first section we read the three arguments passed to the script (see Running the Bash script below) using "$1", "$2", and "$3", and assign those to variables. We also define two constants TEST_PORT and MAX_WAIT_SECONDS that we'll use later.
Note: If you're new to Bash, make sure you don't put a space next to = when setting a variable name. Writing BASE_IMAGE = "$1" (with spaces) will give you errors!
Finally, we docker kill any lingering smoke test containers on the build agent. This shouldn't be necessary, as we'll cleanup the containers at the end of the script too, but it can occasionally happen if you have an error in your Bash script that prevents the cleanup from happening.
In the next section, we run our app in a container:
docker run -d --rm - Docker will run the image in the background (-d). When the image exits (or is killed), the container will be removed (--rm).
--name $SMOKE_TEST_IMAGE - Use the variable $SMOKE_TEST_IMAGE as the name of the container. If the name of the app is testapp, then $SMOKE_TEST_IMAGE="testapp-smoke-test".
-e ASPNETCORE_ENVIRONMENT=Testing - I like to use a specific "Testing" environment for running smoke tests and integration tests, but you could alternatively use Development.
$APP_IMAGE - The Docker image of the app to run.
Note that I use the Testing (or Development) environment for the smoke test. You could run a smoke test for each environment that you're deploying to, to test the configuration in each of those environments. That would verify the app can startup in every environment. However I'm a little nervous about running apps using Production settings as part of testing, in case a bug (or feature) has inadvertent consequences. This is just a smoke test after all, it's not intended to be foolproof!
At this point, our app is running a container, on the CI server, listening on the default ports inside the container. However, as we haven't mapped any ports externally (using -p), there's no way for anything to call the app directly. This is intentional - we don't want the CI server randomly exposing the smoke test apps. Instead, we will use docker exec to probe the container shortly.
Before we try and exec into the container, we need to make sure it's started. In the following script we use docker inspect to look for evidence that the container is listening on our test port. If it isn't, the script sleeps for 1 second and tries again, until $MAX_WAIT_SECONDS seconds expires, at which point we accept that the smoke test failed, and exit the script.
until nc -z $(docker inspect --format='{{.NetworkSettings.IPAddress}}' $SMOKE_TEST_IMAGE)$TEST_PORTdoecho"waiting for container to startup..."sleep 1.0
((MAX_WAIT_SECONDS--))#decrementif[$MAX_WAIT_SECONDS -le 0 ];thenecho"Docker smoke test failed, port $TEST_PORT not available"
docker kill$SMOKE_TEST_IMAGE||trueexit -1
fidone
The next section of the script is where we test if the app health check endpoint is responding correctly using docker exec:
# hit the status endpoint (don't kill script on failure)set +e
docker exec -i $SMOKE_TEST_IMAGEwget http://localhost:$TEST_PORT$$TEST_PATH# capture the return code
result=$?
The first thing we do is set +e so that if the docker exec command fails, the script doesn't exit immediately. Instead, we capture the return code in the variable $result. The command we're running is a simple GET request for the provided test port and path. At runtime, variable replacement will mean this command looks something like;
As long as the app returns a 200 OK or other success response, the smoke test will pass.
You could also use curl instead of wget. I use wget as it's available by default in the tiny .NET Core alpine Docker images.
The final part of the script is some simple cleanup, reenabling exit on error, killing our running smoke test container, and returning the smoke test result stored in $result
# Reenable exit on errorset -e
# kill the test container
docker kill$SMOKE_TEST_IMAGEif[$result -ne 0 ];thenecho"Docker smoke test failed"elseecho"Docker smoke test passed"fiexit$result
To use this script, add it to your repository somewhere, and invoke it as part of your build process, as shown in the following section.
Running the Bash script
To run the smoke test, first save the script to docker_smoke_test.sh, and invoke it passing in the name of the app, the docker image to run, and the path to invoke. If you're not using the default port 80 for your app, then you could customise the script to also pass that in as an argument.
After running the script, you should see something like the following output from your CI logs:
+ APP_NAME=testapp
+ APP_IMAGE=my_private_repo/testapp:latest
+ TEST_PATH=/healthz
+ APP_TEST_PORT=80
+ MAX_WAIT_SECONDS=30
+ docker kill testapp-smoke-test
Error response from daemon: Cannot kill container testapp-smoke-test: No such container: testapp-smoke-test
+ true
+ docker run -d --rm --name testapp-smoke-test -e ASPNETCORE_ENVIRONMENT=Testing my_private_repo/testapp:latest
++ docker inspect '--format={{.NetworkSettings.IPAddress}}' testapp-smoke-test
+ nc -z 172.17.0.8 80
+ echo'waiting for container to startup...'
waiting for container to startup...
+ sleep 1.0
+ (( MAX_WAIT_SECONDS--))
+ '[' 29 -le 0 ']'
++ docker inspect '--format={{.NetworkSettings.IPAddress}}' testapp-smoke-test
+ nc -z 172.17.0.8 80
+ set +e
+ docker exec -i testapp-smoke-test wget http://localhost:80/healthz
Connecting to localhost:80 (127.0.0.1:80)
healthz 100% |*******************************| 6350 0:00:00 ETA
+ result=0
+ set -e
+ docker kill testapp-smoke-test
testapp-smoke-test
+ killOk=0
+ '[' 0 -ne 0 ']'
+ '[' 0 -ne 0 ']'
+ echo'Docker smoke test passed'
Docker smoke test passed
+ exit 0
The important point here is the "Docker smoke test passed" printed to the console and exit 0, indicating that the smoke test passed successfully.
If you want a bit less verbosity, use set -eu instead of set -eux at the top of your test script, and commands will no longer be echoed to the console as they're executed.
Summary
In this post I showed how you could use Docker to run a smoke test as part of your CI build process. You can use this test to check that your application can start up and can respond to a basic endpoint. This is far from a thorough test, and doesn't cover as much as functional/integration tests would, but it can be useful nonetheless.
I was recently standing up a new ASP.NET Core application running in Docker, and I was seeing some very strange behaviour. The application would start up without any problems when running locally on my Windows machine. But when I pushed it to the build server, the application would immediately fail, citing a "missing connection string" or something similar. I spent a good half an hour trying to figure out the issue, so this post is just in case someone else runs into the same problem!
In this post I'll cover the basic background of environments in ASP.NET Core, and describe how you would typically use environment-specific configuration. Finally, I'll describe the bug that I ran into and why it was an issue. If you just want to see the bug, feel fee to skip ahead.
tl;dr;IHostingEnvironment ignores the case of the current environment when you use the IsDevelopment() extension methods etc. However, if you are using environment-specific configuration files, appsettings.Development.json for example, then you must pay attention to case. Setting the environment to "development" instead of "Development" will result in your configuration files not loading on a case-sensitive OS like Linux.
ASP.NET Core environments
ASP.NET Core has the concept of environments, which represent the different locations your code might be running. You can determine the current environment at runtime, and use the value to change the behaviour of your app somehow. For example, in Startup.Configure(), it's common to configure your middleware pipeline differently if you're running in "Development" as opposed to "Production":
publicvoidConfigure(IApplicationBuilder app,IHostingEnvironment env){// Only added when running in Developmentif(env.IsDevelopment()){
app.UseDeveloperExceptionPage();}// Only added when running in Productionif(env.IsProduction()){
app.UseExceptionHandler("/Error");}
app.UseStaticFiles();
app.UseMvc();}
You can use IHostingEnvironment anywhere in your application where you want to check the current environment, and behave differently based on the value.
ASP.NET Core has knowledge of three environments by default, and provides extension methods for working with them:
"Development" - Identified using IHostingEnvironment.IsDevelopment()
"Staging" - Identified using IHostingEnvironment.IsStaging()
"Production" - Identified using IHostingEnvironment.IsProduction()
You can also see the value of the current environment by reading IHostingEnvironment.EnvironmentName directly, but it's highly recommended you use one of the extension methods. The extension methods take care to make a case-insensitive comparison between the EnvironmentName and the expected string (e.g. "Development").
While you can litter your code with imperative checks of the environment, a generally cleaner approach is to use environment-specific configuration, which I'll describe shortly.
ASP.NET Core configuration primer
The configuration system in ASP.NET Core is built up of layers of configuration values, compiled from multiple sources. You can load values from JSON files, XML files, environment variables, or you can create a custom provider to load values from pretty much anywhere.
You can build a configuration object by adding providers to an IConfigurationBuilder object. This typically happens in Program.cs, using the IWebHostBuilder.ConfigureAppConfiguration method. WebHost.CreateDefaultBuilder() calls this method behind the scenes in a typical ASP.NET Core 2.x app. Each provider added to the IConfigurationBuilder adds another layer of configuration. For example, the following code adds a JSON file (appsettings.json) and environment variables to the final configuration object:
IHostingEnvironment env;var builder =newConfigurationBuilder().SetBasePath(env.ContentRootPath)// the path where the json file should be loaded from.AddEnvironmentVariables();
The order of the configuration providers is important here; if any environment variable has the same name as a setting in the JSON file, it will overwrite the JSON setting. The final configuration will be a "flattened" view of the settings in all of the configuration sources.
I think of the flattening of configuration providers as similar to the flattening of layers in a Photoshop image. Each layer overwrites the values from the previous layers, except where it is transparent (i.e. where the layer doesn't have values).
For example, imagine you have the following appsettings.json configuration file;
The "flattening" of configuration providers is what allows you to have environment-specific configuration. Take the common case where you want to use a different setting in local development compared to production. There are a number of ways you could achieve this, for example:
Overwrite default values e.g. only set an environment variable for the setting in Production.
Use different configuration provider settings e.g. Load settings from Azure Key Vault in production, and User Secrets for local development.
Load additional configuration providers e.g. load an additional environment-specific JSON file
Those last two points are essentially the same thing, but I wanted to call them out as different because they're typically used for two slightly different things, secrets vs. settings.
Secrets, such as API keys and connection strings shouldn't be stored inside your repository. For local development, sensitive values should be stored in User Secrets. In production, secrets should be retrieved from a provider such as Azure Key Vault.
In contrast, settings are not sensitive values, they just represent something you might want to configure differently between environments. For example, maybe you want to use more caching in production, or write log files to different locations.
The typical WebHost.CreateDefaultBuilder() method uses all three approaches: overwriting, different providers, and additional providers. The configuration method for the default builder is shown below:
ConfigureAppConfiguration((hostingContext, config)=>{var env = hostingContext.HostingEnvironment;
config.AddJsonFile("appsettings.json", optional:true, reloadOnChange:true).AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional:true, reloadOnChange:true);// optional extra providerif(env.IsDevelopment())// different providers in dev{var appAssembly = Assembly.Load(newAssemblyName(env.ApplicationName));if(appAssembly !=null){
config.AddUserSecrets(appAssembly, optional:true);}}
config.AddEnvironmentVariables();// overwrites previous valuesif(args !=null){
config.AddCommandLine(args);}});
The default builder configures up to 5 configuration providers by default:
A JSON file called appsettings.json
An environment-specific JSON file called appsettings.ENVIRONMENT.json where ENVIRONMENT is the name of the current environment
User Secrets, if in the Development environment
Environment variables
Command line arguments (if any arguments were passed)
For the rest of this post I'm going to focus on the environment-specific JSON file, as that's what caused the issue I encountered.
The problem: environment-specific configuration not loading
As part of a new .NET Core app I was building, I was running a "smoke test" on the Docker container produced, as described in my last post. This involves running the Docker container on the build server, and checking that the container starts up correctly. The idea is to double check that the initial configuration that occurs on app start up is correct. One such check is that any strongly typed settings validation runs successfully.
This approach of starting the app as part of the CI process won't necessarily be a good (or useful) approach for all apps. I added it to the CI process of several apps as an incredibly basic "sanity check" but I'm not 100% convinced by my approach yet!
When I ran the smoke test for the first time in a new app, the settings validation for a third-party API URL failed. This was very odd, as I had tested the application locally. When running smoke tests, I typically set the Hosting Environment of the app to Development, (or sometimes a testing-specific environment, Testing). Inside the appsettings.Development.json file, I could see the offending configuration value:
But for some reason, when the application was running in Docker for the smoke tests, the value wasn't being bound correctly. In the next section, I'll briefly describe some of the things I thought of and looked into.
Troubleshooting
I tried debugging locally, adding and removing the file, and changing the setting value. I was trying to confirm that the file was definitely being loaded correctly, and the setting wasn't coming from somewhere else when running locally. Everything was correct.
I checked that there were no unexpected environment variables overwriting the value when the app was running in Docker for the smoke test. There weren't.
I looked inside the Docker container itself, and double checked that the appsettings.Development.json file existed, and was in the right place. Everything looked OK.
Finally, I checked that I was actually running in the environment I expected - Development. Looking at the logs from the container when the smoke test ran I could see that the Hosting environment was correct according to the app:
Hosting environment: Development
Content root path: /app/
Now listening on: https://localhost:80
Application started. Press Ctrl+C to shut down.
At this point, I was somewhat stumped, I had run out of ideas. I made a coffee.
When I sat down and opened the smoke test script file, the answer hit me immediately…
Linux file-system case-sensitivity
The smoke test script I was using is very similar to the script from my last post. The command I was using to run my new app for the smoke test is shown below:
The problem is the statement where I set the environment variable to define the hosting environment using
ASPNETCORE_ENVIRONMENT=development
This sets the environment to development which is not the same as Development. ASP.NET Core itself is careful to not differentiate between environments based on case - the IHostingEnvironment extension methods like IsDevelopment() are all case insensitive. As long as you use these extension methods and don't use IHostingEnvironment.EnvironmentName directly, you'll be fine.
However, the one place where it's very common to use EnvironmentName directly is in your app configuration. Earlier I described the common approach to environment-specific configuration: adding an extra appsettings.json file:
var env = hostingContext.HostingEnvironment;
config.AddJsonFile("appsettings.json").AddJsonFile($"appsettings.{env.EnvironmentName}.json");
As you can see, we're directly using EnvironmentName to calculate the environment-specific JSON configuration file. In my smoke test script, EnvironmentName="development", so the app was looking for the appsettings.development.json file. The file was actually called appsettings.Development.json.
On Windows, this case difference doesn't matter - ASP.NET Core respects the conventions of the host OS, so it loads the file. Even if you set the environment to DeVelOpMeNt, you'd be fine. Linux, however, is case sensitive, so it won't find the file.
The simple fix was to set the environment with the standard title-casing:
With that small change, the app was able to start, and the smoke test succeeded.
Summary
Always be consistent with your environment names. The case may not matter if you're running on Windows, but it definitely will if your app is ever run on Linux. The ASP.NET Core framework itself is careful to ignore case when determining the current environment, but you can't trust the underlying operating system to do the same!
This post looks at the GetService<T>() and GetRequiredService<T>() methods of the default/built-in ASP.NET Core DI container, provided in Microsoft.Extensions.DependencyInjection. I'll describe the differences between them and which one you should use.
tl;drGetService() returns null if a service does not exist, GetRequiredService() throws an exception instead. If you're using a third-party container, use GetRequiredService where possible - in the event of an exception, the third party container may be able to provide diagnostics so you can work out why an expected service wasn't registered.
The heart of the container - the IServiceProvider interface
At the heart of the ASP.NET Core dependency injection abstraction is the IServiceProvider interface. This interface is actually part of the base class library, in the System namespace. The interface itself is very simple:
Once you've registered all your classes with the DI container (using IServiceCollection), pretty much all a DI container needs to do is allow you to retrieve an instance of an object using GetService().
Of course, you typically shouldn't be using the IServiceProvider directly in your code at all. Instead, you should be using standard constructor injection, and letting the framework worry about using IServiceProvider behind the scenes.
Using the IServiceProvider directly is an example of the service locator pattern This is generally considered an anti-pattern, as it hides a class' dependencies.
Comparing GetService<T>() and GetRequiredService<T>()
Seeing as we're not using .NET 1.0 anymore, if you want to retrieve a service from the IServiceProvider, you've probably used the generic GetService<T>() extension method, instead of the GetService(Type) interface method. But you may have also noticed the similar GetRequiredService<T>() extension method - the question is, what's the difference between them, and which should you use?
Before we look at any code, let's discuss the expected behaviour of the methods. First of all, from the documentation of the GetService() method:
GetService() returns a service object of type serviceType. -or- null if there is no service object of type serviceType.
Contrast that to the documentation for GetRequiredService():
GetRequiredService() returns a service object of type serviceType. Throws an InvalidOperationException if there is no service of type serviceType.
So both methods behave the same when an instance of the requested serviceType is available. The difference is in their behaviour when the serviceType has not been registered:
GetService - returns null if the service is not registered
GetRequiredService - throws an Exception if the service is not registered
Now we've cleared that up, lets look at some code.
I've removed some of the precondition checks from the code in this post; if you want to see the full code, check it out on GitHub.
publicstaticclassServiceProviderServiceExtensions{publicstatic T GetService<T>(thisIServiceProvider provider){return(T)provider.GetService(typeof(T));}publicstatic T GetRequiredService<T>(thisIServiceProvider provider){return(T)provider.GetRequiredService(typeof(T));}}
Both methods are virtually the same - the generic extension methods delegate to the non-generic versions of GetService() and GetRequiredService(). They're simply a convenience so you don't need to use the more wordy typeof() and typecast in your own code.
The non-generic version of GetService() is part of the IServiceProvider interface, but the non-generic GetRequiredService() implementation is an extension method in the same class:
publicstaticclassServiceProviderServiceExtensions{publicstaticobjectGetRequiredService(thisIServiceProvider provider,Type serviceType){var requiredServiceSupportingProvider = provider as ISupportRequiredService;if(requiredServiceSupportingProvider !=null){return requiredServiceSupportingProvider.GetRequiredService(serviceType);}var service = provider.GetService(serviceType);if(service ==null){thrownewInvalidOperationException(Resources.FormatNoServiceRegistered(serviceType));}return service;}}
The first step in in the method is to check whether the provided IServiceProvideralso implements ISupportRequiredService. This interface provides an underlying non-generic GetRequiredService implementation, so if the service provider implements it, GetRequiredService() is called directly.
The ASP.NET Core built-in DI container does not implement ISupportRequiredService - only third-party containers implement GetRequiredService().
If the IServiceProvider does not implement ISupportRequiredService, then the required exception-throwing behaviour is implemented as you might expect: GetService() is called, and an exception is thrown if it returns null.
Reduces duplication. If a service is not available, with GetRequiredService() an exception is thrown immediately. If you use GetService() instead, then you ned to check for null in the calling code, and often will need to throw an exception anyway. That null-checking code will need to be duplicated everywhere.
Fails fast. If you forget to check for null when using GetService() then you could end up with a NullReferenceException some time later. Figuring out what caused the exception is always going to be more work than having an InvalidOperationException that explicitly tells you.
Allows advanced diagnostics for third-party containers. One of the big benefits of StructureMap and some other third-party containers are their ability to provide detailed exception messages as to why a service was not found. If you're using GetRequiredService(), the third-party container itself generates the exception, and so can provide additional container-specific information. Just returning null (with GetService()) gives you no further insight. This was the main reason for the introduction of GetRequiredService().
I've seen a couple of arguments against GetRequiredService(), but I don't think either of them hold up to scrutiny:
"I'm not using a third-party container". If you're using the built-in container (which doesn't implement ISupportRequiredService) then you won't benefit from any additional diagnostics by using GetRequiredService(). However, I'd argue the first two advantages still stand, and make GetRequiredService worth using. Plus if you add a third-party container later, you're already using the best practice.
"I have optional services, that are only sometimes registered with the DI container.". This is probably the only valid reason to use GetService(). If you have code that should only run if a given service is registered then you may need to use GetService(). However, I've also seen it used where a fallback service is used if GetService() returns null. In my opinion, this is rarely a good pattern for application code. Orchestration of fallbacks should be something that happens as part of your DI container configuration, not where the service is consumed.
So there you have it - GetService() vs. GetRequiredService(). Before I dug into it further, I was somewhat arbitrary in when I chose one over the other, but now I'll make sure I always use GetRequiredService() as a matter of course.
Summary
GetService() is the only method on IServiceProvider, the central interface in the ASP.NET Core DI abstractions. Third-party containers can also implement an optional interface ISupportRequiredService which provides the GetRequiredService() method. These methods behave the same when a requested serviceType is available. If the service is not available (i.e. it wasn't registered), GetService() returns null, whereas GetRequiredService() throws an InvalidOperationException.
The main benefit of GetRequiredService() over GetService() is that it allows third-party containers to provide additional diagnostic information when a requested service is not available. For that reason, it's always best to use GetRequiredService() when using a third-party container. Personally, I will use it everywhere, even if I'm only using the built-in DI container.
In this post I describe how to register a concrete class with multiple public interfaces in the Microsoft.Extensions.DependencyInjection container used in ASP.NET Core. With this approach you'll be able to retrieve the concrete class using any of the interfaces it implements. For example, if you have the following class:
then you'll be able to inject either ISomeInterface or ISomethingElse and you will receive the same MyTestClass instance.
Its important that you register the MyTestClass in a specific way to avoid unexpected lifetime issues, such as having two instances of a singleton!
In this post I give a brief overview of the DI container in ASP.NET Core and some of its limitations compared to third party containers. I'll then describe the concept of "forwarding" requests for multiple interfaces to a concrete type, and how you can achieve this with the ASP.NET Core DI container.
TL;DR The ASP.NET Core DI container doesn't natively support registering an implementation as multiple services (sometimes called "forwarding"). Instead, you have to manually delegate resolution of the service to a factory function, e.g services.AddSingleton<IFoo>(x=> x.GetRequiredService<Foo>())
Dependency Injection in ASP.NET Core
One of the key features of ASP.NET Core is its use of dependency injection (DI). The framework is designed around a "conforming container" abstraction that allows the framework itself to use a simple container, while also allowing you to plug in more feature-rich third-party containers.
To make the conforming container as simple as possible for third-party containers to implement, it exposes a very limited number of APIs. For a given service (e.g. IFoo), you can define the concrete class that implements it (e.g. Foo), and the lifetime it should have (e.g. Singleton). There are variations on this where you can directly provide an instance of the service, or you can provide a factory method, but that's about as complex as you can get.
In contrast, third-party DI containers in .NET often provide more advanced registration APIs. For example, many DI containers expose a "scan" API for configuration, in which you can search through all types in an assembly, and add them to your DI container. The following is an Autofac example:
var dataAccess = Assembly.GetExecutingAssembly();
builder.RegisterAssemblyTypes(dataAccess)// find all types in the assembly.Where(t => t.Name.EndsWith("Repository"))// filter the types.AsImplementedInterfaces()// register the service with all its public interfaces.SingleInstance();// register the services as singletons
In this example, Autofac will find all concrete classes in the assembly who's name ends with "Repository", and register them in the container against any public interfaces they implement. So for example, given the following classes and interfaces:
The previous Autofac code is equivalent to manually registering both classes with their respective interfaces in the ASP.NET Core container in Startup.ConfigureServices:
Lets write a quick test to see what happens if we register the class against both interfaces using the ASP.NET Core DI container:
[Fact]publicvoidWhenRegisteredAsSeparateSingleton_InstancesAreNotTheSame(){var services =newServiceCollection();
services.AddSingleton<IFoo,Foo>();
services.AddSingleton<IBar,Foo>();var provider = services.BuildServiceProvider();var foo1 = provider.GetService<IFoo>();// An instance of Foovar foo2 = provider.GetService<IBar>();// An instance of Foo
Assert.Same(foo1, foo2);// FAILS}
We registered Foo as a singleton for both IFoo and IBar, but the result might not be what you expect. We actually have two instances of our Foo "Singleton", one for each service it was registered as.
Forwarding requests for a service
The general pattern of having an implementation registered against multiple services is a common one. Most third-party DI containers have this concept built in. For example:
Autofac uses this behaviour by default - the previous test would have passed
Windsor has the concept of "forwarded types" which allows you to "forward" multiple services to a single implementation
StructureMap (now sunsetted) had a similar concept of "forwarded" types. As far as I can tell, it's successor, Lamar, doesn't yet, but I could be wrong on that one.
Given this requirement is quite common, it might seem odd that it's not possible with the ASP.NET Core DI container. The issue was raised (by David Fowler) over 2 years ago, but it was closed. Luckily there's a couple of conceptually simple, if somewhat inelegant, solutions.
1. Provide an instance of the service (Singleton only)
The simplest approach is to provide an instance of Foo when you're registering your services. Each registered service will return the exact instance you provided when requested, ensuring there is only ever a single instance.
There's one big caveat with this - you have to be able to instantiate Foo at configuration time, and you have to know and provide all of it's dependencies. This may work for you in some cases, but it's not very flexible.
Additionally, you can only use this approach for registering Singletons. If you want Foo to be a single instance per-request-scope (Scoped), then you're out of luck. Instead, you'll need to use the following technique.
2. Implement forwarding using factory methods
If we break down our requirements, then an alternative solution pops out:
We want our registered service (Foo) to have a specific lifetime (e.g. Singleton or Scoped)
When IFoo is requested, return the instance of Foo
When IBar is requested, also return the instance of Foo
From those three rules, we can write another test:
[Fact]publicvoidWhenRegisteredAsForwardedSingleton_InstancesAreTheSame(){var services =newServiceCollection();
services.AddSingleton<Foo>();// We must explicitly register Foo
services.AddSingleton<IFoo>(x => x.GetRequiredService<Foo>());// Forward requests to Foo
services.AddSingleton<IBar>(x => x.GetRequiredService<Foo>());// Forward requests to Foovar provider = services.BuildServiceProvider();var foo1 = provider.GetService<Foo>();// An instance of Foovar foo2 = provider.GetService<IFoo>();// An instance of Foovar foo3 = provider.GetService<IBar>();// An instance of Foo
Assert.Same(foo1, foo2);// PASSES
Assert.Same(foo1, foo3);// PASSES}
In order to "forward" requests for an interface to the concrete type you must do two things:
Explicitly register the concrete type using services.AddSingleton<Foo>()
Delegate requests for the interfaces to the concrete type by providing a factory function: services.AddSingleton<IFoo>(x => x.GetRequiredService<Foo>())
With this approach, you will have a true singleton instance of Foo, no matter which implemented service you request.
This approach to providing "forwarded" types was noted in the original issue, along with a caveat - it's not very efficient. The "service-locator style" GetService() invocation is generally best avoided where possible. However, I feel it's definitely the preferable course of action in this case.
Summary
In this post I described what happens if you register a concrete type as multiple services with the ASP.NET Core DI service. In particular, I showed how you could end up with multiple copies of Singleton objects, which could lead to subtle bugs. To get around this, you can either provide an instance of the service at registration time, or you can use factory methods to delegate resolution of the service. Using factory methods is not very efficient, but is generally the best approach.
In this post I describe how to use the open source library Scrutor by Kristian Hellang to add assembly scanning capabilities to the ASP.NET Core DI container. Scrutor is not a dependency injection (DI) container itself, instead it adds additional capabilities to the built-in container. The library has been going for over 2 years now - see this post for the original announcement and motivation for the library by Kristian.
This post ended up being pretty long, so, for your convenience, a table of contents:
ASP.NET Core uses dependency injection throughout the core of the framework. Consequently, the framework includes a simple DI container that provides the minimum capabilities required by the framework itself. This container can be found in the Microsoft.Extensions.DependencyInjection NuGet package.
There are also many third-party .NET DI libraries that provide many more capabilities and features. I wrote quite a while back about using StructureMap in ASP.NET Core (though if you're using StructureMap, you should probably take a look at Lamar instead), but there are many containers to choose from, for example:
These containers all provide different features and focuses: attribute-based configuration, convention based registration, property injection, performance… the list goes on.
A common feature is to provide automatic registration of services by scanning the types in the assembly, and looking for those that match a convention. This can greatly reduce the boilerplate configuration required in your Startup.ConfigureServices method.
For example, if your registrations at the moment look like this:
Scrutor is not a new DI container. Under the hood it uses the built-in ASP.NET Core DI container. This has both pros and cons for you as an app developer:
Pros:
It's simple to add to an existing ASP.NET Core application. You can easily add Scrutor to an app that's using the built in container. As the same underlying container is used, you can be confident there won't be any unexpected changes in service resolution.
You can use Scrutor with other DI containers. As Scrutor uses the built-in DI container, and as most third-party DI containers provide adapters for working with ASP.NET Core, you could potentially use both Scrutor and another container in a single application. I can't see that being a common scenario, but it might make migrating an app to use a third-party container easier than moving between two different third-party containers.
It's very likely to remain supported and working, even if the built-in DI container changes. Hopefully this won't be a concern, but if the ASP.NET Core team make breaking changes to the DI container, Scrutor seems less likely to be affected than third party containers, as it uses the built-in DI container directly, as opposed to providing an alternative container implementation.
Cons:
Reduced functionality. As it uses the built-in container, Scrutor will always be limited by the functionality of the built-in container. The built-in container is intentionally kept very simple, and is unlikely to gain significant extra features.
I'm sure there's more cons, but the reduced functionality is a really big one! If you're used to one of the more full-featured DI containers, then you'll likely want to stick with those. On the other hand, if you're currently only using the built-in container, Scrutor is worth a look to see if it can simplify your code.
To install Scrutor, run dotnet add package Scrutor from the .NET CLI, or Install-Package Scrutor from the Package Manager Console. In the next section, I'll show some of the assembly scanning primitives you can use with Scrutor.
Assembly scanning with Scrutor
The Scrutor API consists of two extension methods on IServiceCollection: Scan() and Decorate(). In this post I'm just going to be looking at the Scan method, and some of the options it provides.
The Scan method takes a single argument: a configuration action in which you define four things:
A selector - which implementations (concrete classes) to register
A registration strategy - how to handle duplicate services or implementations
The services - which services (i.e. interfaces) each implementation should be registered as
The lifetime - what lifetime to use for the registrations
For example a Scan method which looks in the calling assembly, and adds all concrete classes as transient services would look like the following:
services.Scan(scan => scan
.FromCallingAssembly()// 1. Find the concrete classes.AddClasses()// to register.UsingRegistrationStrategy(RegistrationStrategy.Skip)// 2. Define how to handle duplicates.AsSelf()// 2. Specify which services they are registered as.WithTransientLifetime());// 3. Set the lifetime for the services
So we have something concrete to discuss, lets imagine we have the following services and implementations in an assembly:
The previous Scan() code would register Service1, Service2, Service and Foo as themselves, equivalent to the following statements using the built in container:
In the next section I'll look at some of the options available to you for point 1 - choosing which implementations to register.
Selecting and filtering the implementations to register
The very first configuration step in the end assembly scan is to define which concrete classes you want to register in your application. Scrutor provides a lot of different ways to search for types, focussing primarily on scanning assemblies for types, and filtering the list. In this section I describe the various options available.
If you've ever used the assembly scanning capabilities of other DI containers like StructureMap or Autofac then this should feel quite familiar to you.
Specifying the types explicitly
The simplest type selector involves providing the types explicitly. For example, to register Service1 and Service2 as transient services:
There are three AddTypes<> methods available, with 1, 2, or 3 generic parameters available. You probably won't find you use this approach very often, but it can be handy now and again. In practice, you're more likely to use assembly scanning to find the types automatically.
Scanning an assembly for types
The real selling point for Scrutor is its methods to scan your assemblies, and automatically register the types it finds. Scrutor has several variations which allow you to pass in instances of Assembly to scan, to retrieve the list of Assembly instances based on your app's dependencies, or to use the calling or executing assembly. Personally I prefer the methods that allow you to pass a Type, and have Scrutor find all the classes in the assembly that contains the Type. For example:
The code above will find the assembly that contains IService and scan for all of the classes it contains. For the current version of Scrutor, 3.0.0 at the time of writing (named Third Essential Scarecrow 😂) , the following assembly scanning methods are available:
FromAssemblyOf<>, FromAssembliesOf - Scan the assemblies containing the provided Type or Types
FromCallingAssembly, FromExecutingAssembly, FromEntryAssembly - Scan the calling, executing, or entry assembly! See the Assembly static methods for details on the differences between them.
FromAssemblyDependencies - Scan all assemblies that the provided Assembly depends on
FromApplicationDependencies, FromDependencyContext - Scan runtime libraries. I don't really know anything about DependencyContexts so you're on your own with these ones!
Filtering the classes you find
Whichever assembly scanning approach you choose, you need to call AddClasses() afterwards, to select the concrete types to add to the container. This method has several overloads you can use to filter out which classes are selected:
AddClasses() - Add all public, non-abstract classes
AddClasses(publicOnly) - Add all non-abstract classes. Set publicOnly=false to add internal/private nested classes too
AddClass(predicate) - Run an arbitrary action to filter which classes include. This is very useful and used extensively, as shown below.
AddClasses(predicate, publicOnly) - A combination of the previous two methods.
The ability to run a predicate for every concrete class discovered is very useful. You can use this predicate in many different ways. For example, to only include classes which can be assigned to (i.e. implement) a specific interface, you could do:
Once you've defined your concrete class selector, you can optionally define your replacement strategy.
Handling duplicate services with a ReplacementStrategy
Scrutor lets you control how to handle the case where a service (e.g. IService) has already been registered in the DI container by specifying a ReplacementStrategy. There are currently five different replacement strategies you can use:
Append - Don't worry about duplicate registrations, add new registrations for existing services. This is the default behaviour if you don't specify a registration strategy.
Skip - If the service is already registered in the container, don't add a new registration.
Replace(ReplacementBehavior.ServiceType) - If the service is already registered in the container, remove all previous registrations for that service before creating a new registration.
Replace(ReplacementBehavior.ImplementationType) - If the implementation is already registered in the container, remove all previous registrations where the implementation matches the new registration, before creating a new registration.
Replace(ReplacementBehavior.All) - Apply both of the previous behaviours. If the service or the implementation have previously been registered, remove all of those registrations first.
To choose a replacement strategy, use the UsingRegistrationStrategy() method after specifying your type selector:
Getting your head around the difference between the Replacement strategies (the last three in particular) can be a little tricky, so I'll provide a quick example. Imagine the DI container already contains the following registrations:
What will be the final result with each of the replacement strategies? With Append, the answer is easy, you get everything:
services.AddTransient<ITransientService,TransientService>();// From previous registrations
services.AddScoped<IScopedService,ScopedService>();// From previous registrations
services.AddTransient<IFooSerice,TransientService>();
services.AddScoped<IScopedService,AnotherService>();
With Skip, the duplicate IScopedService is ignored, but we append the TransientService/IFooService pair:
services.AddTransient<ITransientService,TransientService>();// From previous registrations
services.AddScoped<IScopedService,ScopedService>();// From previous registrations
services.AddTransient<IFooSerice,TransientService>();
On to the trickier ones. Replace(ReplacementBehavior.ServiceType) replaces by service type (i.e. interface), so in this case the IScopedServiceScopedService registration would be replaced by AnotherService:
services.AddTransient<ITransientService,TransientService>();// From previous registrations
services.AddTransient<IFooSerice,TransientService>();
services.AddScoped<IScopedService,AnotherService>();// Replaces ScopedService
If you replace by implementation type, Replace(ReplacementBehavior.ImplementationType), then the TransientService registration is changed from an ITransientService to an IFooService. The duplicate IScopedService is appended:
services.AddScoped<IScopedService,ScopedService>();// From previous registrations
services.AddTransient<IFooSerice,TransientService>();// Changed from ITransientService to IFooService
services.AddScoped<IScopedService,AnotherService>();
Finally, if you use Replace(ReplacementBehavior.All), both of the previous registrations would be removed, and replaced by the new ones:
The replacement strategry is probably one of the hardest aspects to get your head araound. Where possible, I would try and avoid it by avoiding manually registering any classes which would also be discovered as part of a Scan.
Registering implementations as a service
We've discussed how to find the implementations to add, and an implementation strategry, but we still need to choose how the classes are registered in the container.
Scrutor provides many different options for how to register a given service. I'll walk through each of them in turn, show how to use it, and show what the equivalent "manual" registration would look like.
You call each method after AddClasses() if you're using the default registration strategy, or after UsingRegistrationStrategy() if not:
services.Scan(scan => scan
.FromAssemblyOf<IService>().AddClasses().AsSelf()// Specify how the to register the implementations/services.WithSingletonLifetime());
For the examples in this section, I'll assume Scrutor has found the following class as part of its assembly scanning:
publicclassTestService:ITestService, IService {}
Registering an implementation as itself
For classes that don't implement an interface, or which you wish to be directly available for injection, you can use the AsSelf() method. In our example, this is equivelent to the following manual registration:
services.AddSingleton<TestService>();
Registering services which match a standard naming convention
A pattern I see a lot is where each concrete class, Class, has an equivalent interface named IClass. You can register all the serclasses that match this pattern using the AsMatchingInterface() method. For our example, this is equivelent to the following:
Registering an implementation as all implemented interfaces
If a class implements more than one interface, sometimes you will want the class to be registered with all of those services. You can achieve this with Scrutor using AsImplementedInterfaces():
As I discussed in my last post, it's important to understand that these registrations could lead to bugs where you have two instances of the "singleton". If that's not what you want, read on!
Registering an implementation using forwarded services
I discussed in my previous post how registering an implementation more than once in the DI container could lead to multiple instances of "singleton" or "scoped" services. The ASP.NET Core DI container does not support "forwarded" service types, so you typically have to achieve it manually using an object factory. For example:
With Scrutor, you can now (as of 3.0.0) easily use this pattern by using the AsSelfWithInterfaces() method.
Registering an implementation as an arbitrary service
The final registration option is to specify a specific service, e.g. IMyService using the As<T>() function, e.g. As<IMyService>(). This registers all classes found as that service:
services.AddSingleton<IMyService,TestService>();
Note that if you try and register a concrete type with a service that it can't provide, you'll get an InvalidOperationException at runtime.
That covers all of the different registration options. You'll probably find you use a variety of different methods for the different services in your app (with the exception of the As<T>() function, which I haven't personally found a need for).
The final aspect to consider when registering services in DI containers is the lifetime. Luckily, as Srutor uses the built-in DI container, that's pretty self explanatory if you're familiar with I in ASP.NET Core.
Specifying the lifetime of the registered classes
Whenever you register a class in the ASP.NET Core DI container, you need to specify the lifetime of the service. Scrutor has methods that correspond to the three lifetimes in ASP.NET Core:
WithTransientLifetime() - Transient is the default lifetime if you don't specify one.
WithScopedLifetime() - Use the same service scoped to the lifetime of a request.
WithSingletonLifetime() - Use a single instance of the service for the lifetime of the app.
With all these pieces (scanning, filtering, registration strategy, registration type, and lifetime) you can automate registering your services with the DI container.
Scrutor also allows you to decorate your classes with [ServiceDescriptor] attributes to define how services should be registered, but as that seems like an abomination, I won't go into it here 😉.
A more important aspect is looking at how you can combine different rules for different classes together in the same Scan() method.
Chaining multiple selectors together
It's very unlikely that you'll want to register all the classes in your application using the same lifetime or registration strategy. Instead, it's far more likely that you'll want to register subsets of your app using the same strategy.
Scrutor's API allows you to chain together multiple scans of an assembly, specifying the rules for a subset of classes at a time. This feels very natural to me and allows you to write things like the following:
services.Scan(scan => scan
.FromAssemblyOf<CombinedService>().AddClasses(classes => classes.AssignableTo<ICombinedService>())// Filter classes.AsSelfWithInterfaces().WithSingletonLifetime().AddClasses(x=> x.AssignableTo(typeof(IOpenGeneric<>)))// Can close generic types.AsMatchingInterface().AddClasses(x=> x.InNamespaceOf<MyClass>()).UsingRegistrationStrategy(RegistrationStrategy.Replace())// Defaults to ReplacementBehavior.ServiceType.AsMatchingInterface().WithScopedLifetime().FromAssemblyOf<DatabaseContext>()// Can load from multiple assemblies within one Scan().AddClasses().AsImplementedInterfaces());
All in all, scrutor lets you achieve everything you could do manually with the ASP.NET Core DI container, but in a more succinct way. If you miss assembly scanning from third party DI containers, but want to stick with the but-in DI container for whatever reason, I strongly suggest checking out Scrutor.
A whole aspect I haven't discussed in this post is Decoration. I'll cover that in my next post, but in the mean time you can see examples of how to use it on the project Readme.
Summary
Scrutor adds assembly scanning capabilities to the Microsoft.Extensions.DependencyInjection DI container, used in ASP.NET Core. It is not a third-party DI container, but rather extends the built-in container by making it easier to register your services.
To register your services, call Scan() on the IServiceCollection in Startup.ConfigureServices. You must define four things:
A selector - how to find the types to register (typically by scanning an assembly)
A registration strategy - how to handle duplicate services (by default, Scrutor will add new registrations for duplicate services)
The services - which services (i.e. interfaces) each implementation should be registered as
The lifetime - what lifetime to use for the registrations (transient by default)
In my last post, I described how you can use Scrutor to add assembly scanning to the ASP.NET Core built-in DI container, without using a third-party library. Scrutor is not intended to replace fully-featured third-party containers like Autofac, Windsor, or StructureMap/Lamar. Instead, it's designed to add a few additional features to the container that's built-in to every ASP.NET Core application.
In this post, I'll look at the other feature of Scrutor - service decoration. I'll describe how you can use the feature to "decorate" or "wrap" an instance of a service with one that implements the same interface. This can be useful for adding extra functionality to a "base" implementation.
The decorator pattern
The Decorator design pattern is one of the original well-known Gang of Four design patterns. It allows you take an object with existing functionality, and layer extra behaviour on top. For example, in a recent post, Steve Smith discusses a classic example of adding caching functionality to an existing service.
In his example, Steve describes how he has an existing AuthorRepository class, and he wants to add a caching layer to it. Rather than editing the AuthorRepository directly, he shows how you can use the decorator / proxy pattern to add additional behaviour to the existing repository.
If you're not familiar with the decorator/proxy pattern, I strongly suggest reading Steve's post first.
In this post, I'm going to use a somewhat stripped-back version of Steve's example. We have an existing AuthorRepository, which implements IAuthorRepository. This service loads an Author from the AppDbContext (using EF Core for example):
This is our base service that we want to add caching to. Following Steve's example, we create a CachedAuthorRepository which also implements IAuthorRepository, but which also takes an IAuthorRepository as a constructor parameter. To satisfy the interface, the CachedAuthorRepository either loads the requested Author object from it's cache, or by calling the underlying IAuthorRepository.
This is slightly different to Steve's example. In his example, Steve injects the concrete AuthorRepository into the caching decorator class. In my example I'm injecting the interface IAuthorRepository instead. I'll explain why this matters in the next section.
Note This is a very simplistic version of a caching repository - don't use it for production. Steve's implementation makes use of an IMemoryCache instead, and considers cache expiry etc, so definitely have a look at his code if you're actually trying to implement this in your own project.
In your application, you would inject an instance of IAuthorRepository into your classes. The consuming class itself wouldn't know that it was using a CachedAuthorRepository rather than an AuthorRepository, but it wouldn't matter to the consuming class.
That's all the classes we need for now, the question is how do we register them with the DI container?
Manually creating decorators with the ASP.NET Core DI container
As I've discussed previously, the ASP.NET Core DI container is designed to provide only those features required by the core ASP.NET Core framework. Consequently, it does not provide advanced capabilities like assembly scanning, convention-based registration, diagnostics, or interception.
If you need these capabilities, the best approach is generally to use a supported third-party container. However, if for some reason you can't, or don't want to, then you can achieve some of the same things with a bit more work.
For example, imagine you want to decorate the AuthorRepository from the last section with the CachedAuthorRepository. That means when an IAuthorRepository is requested from the service provider, it should return a CachedAuthorRepository that has been injected with an AuthorRepository.
In Steve's example, he made sure that the CachedAuthorRepository required an AuthorRepository in the constructor, not an IAuthorRepository. This allowed him to more easily configure the CachedAuthorRepository as a decorator using the following pattern:
But what if you don't want your decorator to depend on the concrete AuthorRepository? Maybe you want CachedAuthorRepository to work with multiple IAuthorRepository implementations, rather than just the one (current) concrete implementation. One way to achieve this would be to still register the AuthorRepository directly with the DI container as before, but to manually create a CachedAuthorRepository when requested. For example:
This construction achieves the requirements - requests for IAuthorRepository will return a CachedAuthorRepository, and the CachedAuthorRepository constructor can use IAuthorRepository. The downside is that we had to manually create the CachedAuthorRepository using a factory function. This rarely seems right when you see it as part of DI configuration, and will need to be updated if you change the constructor of CachedAuthorRepository - something using a DI container is designed to avoid.
There are other ways around this which avoid having to use new. I'll describe them later when we look under the covers of Scrutor's Decorate command.
In the next section, I'll show how you can use Scrutor to achieve a similar thing, without having to new-up the CachedAuthorRepository instance, while still allowing CachedAuthorRepository to take IAuthorRepository as a constructor argument.
Using Scrutor to register decorators with the ASP.NET Core DI container
As well as assembly scanning, Scrutor includes a number of extension methods for adding Decorators to your classes. The simplest to use is the Decorate<,>() extension method. With this method you can register the CachedAuthorRepository as a decorator for IAuthorRepository:
When you use the Decorate<TService, TDecorator> method, Scrutor searches for any services which have been registered as the TService service. In our case, it finds the AuthorRepository which was registered as an IAuthorRepository.
Note Order matters with the Decorate method. Scrutor will only decorate services which are already registered with the container, so make sure you register your "inner" services first.
Scrutor then replaces the original service registrations with a factory function for the decorator TDecorator, as you'll see in the next section.
Using Scrutor to register Decorators has a number of advantages compared to the "native" approach shown in the previous section:
You're not calling the constructor directly. Any extra dependencies added to the constructor won't affect your DI registration code.
The AuthorRepository is registered "normally" as an IAuthorRepository. This is useful as you don't have to directly control the registration yourself - it could be a different component/library that registers the AuthorRepository component with the DI container.
The Decorate<,> method is explicit in its behaviour. In the "native" approach you have to read all the registration code to figure out what is being achieved. Decorate<,>() is much clearer.
There are a number of other Decorate overloads. I won't be focusing on them in this post, but in brief they are:
TryDecorate<TService, TDecorator>(). Decorate all registered instances of the TService with TDecorator. Useful if you don't know whether the service is registered or not.
Decorate(Type serviceType, Type decoratorType). Non-generic version of the Decorate<,> method. Useful if your service or decorator are open generics like IRepository<>.
Decorate(Func<TService, IServiceProvider, TService> decorator). Provide a Func<> to generate the decorator class given the decorated service. Can be useful if the DI container can't easily create an instance of the decorator.
Registering decorator classes in this way is very simple with Scrutor. If that's all you need, you can stop reading now. For those that like to peak behind the curtain, in the next section I describe how Scrutor goes about avoiding the new construction in its Decorate<,>() method.
Scrutor: Behind the curtain of the Decorate method
In this section, I'm going to highlight some of the code behind the Decorate<,> method of Scrutor, as it's interesting to see how Kristian achieves the same functionality I showed previously with the "native" approach.
This extension method ultimately passes a factory function Func<> which uses the non-generic Decorate() to the DecorateDescriptors method. The related TryDecorateDescriptors method is shown below:
privatestaticboolTryDecorateDescriptors(thisIServiceCollection services,Type serviceType, Func<ServiceDescriptor, ServiceDescriptor> decorator){if(!services.TryGetDescriptors(serviceType,outvar descriptors)){returnfalse;}foreach(var descriptor in descriptors){var index = services.IndexOf(descriptor);// To avoid reordering descriptors, in case a specific order is expected.
services.Insert(index,decorator(descriptor));
services.Remove(descriptor);}returntrue;}
This method first fetches the services descriptors of all the registered TServices.
ServiceDescriptor is the underlying registration type in the ASP.NET Core DI container. it contains a ServiceType, an ImplementationType (or ImplementationFactory), and a Lifetime. When you register a service with the .NET Core container, you're actually adding an instance of a ServiceDescriptor to a collection.
If the service to be decorated, TService, hasn't been registered, the method ends. If it has been registered, the TryDecorateDescriptors method generates a decorated descriptor by calling the decorator function provided as a parameter, and inserts it into the IServiceCollection, replacing each original, un-decorated, service registration.
We still haven't quite seen the magic of the non-generic Decorate() function yet (which was passed as the factory function in the Decorate<,>() method). This method is shown below, with several intermediate methods inlined. It is implemented as an extension method on a ServiceDescriptor, and takes a parameter decoratorType, which is the decorating type (e.g. CachedAuthorRepository from the earlier example).
The really interesting part of this method is the use of ActivatorUtilities.CreateInstance(). Given an IServiceProvider, this method lets you partially provide the constructor parameters for a Type, and lets the IServiceProvider "fill in the blanks".
For example, say you have the following decorator class:
In this example, the Decorator wraps the IRepository instance, but has an additional dependency on IService. Using the ActivatorUtilities.CreateInstance() method, you can fill the IService dependency automatically, while providing the explicit instance to use for the IRepository dependency. For example:
Even if you're not using Scrutor, you can make use of ActivatorUtilities.CreateInstance() in the Microsoft.Extensions.DependencyInjection.Abstractions library to create instances of your classes. You could even use this in place of the "native" approach I showed previously. Though if you're going that far, I'd suggest just using Scrutor instead! 🙂
Summary
In this post I described the Decorator pattern, and showed how you can recreate it "natively" using the ASP.NET Core DI container. I then showed a better approach using the Decorate<,>() method with Scrutor, and how this works under the hood. I strongly recommend you take a look at Scrutor if you want to augment the built-in DI container in your apps, but don't want to take the step to adding a third-party container.
I recently made my first pull request to the Cake project in which I added a command line option (--showtree) to display the tasks in a Cake script in a tree view.
Creating the tree view itself took me a couple of attempts to get right, and I'm bound to forget the trick for it, so in this post I'm going to show the code required to create a similar tree diagram in your own program.
Before we look at the tree itself, it's worth considering the data structure you need to build this tree. There's basically two requirements:
Enumerate all the "top-level" or "root" nodes, i.e. those nodes that are not a child of any other node
For each node, enumerate (and count) the immediate child nodes
Ideally, your data structure will look similar to the tree diagram you're building, but that's not required. As a simple example, we'll consider nodes like the following:
classNode{publicstring Name {get;set;}public ICollection<Node> Children {get;}=newList<Node>();}
We also have a function that returns an IEnumerable<> of the "top level" nodes. This function would create the node "graph" for you, and will depend on your specific application.
I've made a point of using both ICollection<> and IEnumerable<> here, as it highlights the difference in requirements between the list of top-level nodes, and the list of a node's children. We don't need care how many top-level nodes there are, we just need to be able to enumerate through them, hence using IEnumerable<>. On the other hand we _do_ need to be able to find the number of child nodes a given node has (you'll see why shortly), hence using ICollection<> which exposes Count.
Technically, we don't need to know how many child nodes a parent node has. We just need to be able to tell, while enumerating the child nodes, when we've reached the final node.
That's all there is on the data side, which should be pretty flexible. Depending on the data you're trying to display, these data structures may already be available to you, or you may need to build them up manually. For the Cake PR I had to do a bit of both - ScriptHost.Tasks lets you retrieve the children of any given task, but to find the top-level tasks I used an instance of CakeGraphBuilder instead.
Requirements for the display algorithm
As a brief reminder, the ascii structure we're trying to recreate is something like the following:
The corners and cross piece characters are part of "extended ASCII", commonly known as "box-drawing" or "line-drawing" characters. You could also use ordinary hyphens “-” and pipes “|”, but I think the box-drawing characters make the tree more readable. I used codes 179 “│” , 192 “└”, and 195 “├” from here.
When I first took a stab at drawing the ASCII art tree, I dove right in and started writing code without thinking to much about exactly what I needed to display. It didn't seem like it should be a hard problem to solve with a little recursion.
Unfortunately, the results weren't quite right - some vertical lines were missing, or there were extra ones where there shouldn't be. After floundering a couple of times, I took a step back, and thought about the characteristics of the diagram:
Top-level tasks should not be indented or prefixed
Child nodes are indented based on their depth from the top-level node
If a node is the last child it should have a corner (└) prefix, otherwise it should have a crosspiece prefix (├)
If any parent node was not the last child, a pipe (│) prefix is required in the correct position
That last point was the one that was scuppering my initial attempts; not only does every node need to know its own position in the tree (is it the last child, how far from the top-level node is it), it also needs to know the position of every parent node in the tree, so it knows whether to draw the pipe.
For example, consider the Validate-Zip-Files node in the desired output diagram above:
│ │ └─Validate-Zip-Files
In order to print the correct sequence of pipes and spaces (space, pipe, pipe), it needs to know that Package is a "last child", while Zip-Files and Generate-Hashes are not.
All of my initial attempts involved passing in knowledge about the previous nodes, something like the following for example (though even this isn't sufficient):
Although that latter approach works, it's not very efficient, and feels wrong.
The aha moment for me was realising the "tell don't ask" principle applies here. Previously, I was trying to provide enough details about the parents of a node to calculate what its indent should look like. Instead, the key was for the parent to calculate what a child's indent should be, and pass that down directly.
Drawing the tree by pre-calculating the indent
With this in mind, I came up with the following small program which prints an ASCII tree (obtained from the function CreateNodeList). Rather than break this down afterwards, I've commented the code itself to explain what's going on:
classProgram{// Constants for drawing lines and spacesprivateconststring _cross =" ├─";privateconststring _corner =" └─";privateconststring _vertical =" │ ";privateconststring _space =" ";publicstaticvoidMain(string[] args){// Get the list of nodes from somewhere (not shown)
List<Node> topLevelNodes =CreateNodeList();foreach(var node in topLevelNodes){// Print the top level nodes. We start with an empty indent.// Also, all "top nodes" are effectively the "last child" in// their respective sub-treesPrintNode(node, indent:"", isLast:true);}}privatestaticvoidPrintNode(Node node,string indent,bool isLast){// Print the provided pipes/spaces indent
Console.Write(indent);// Depending if this node is a last child, print the// corner or cross, and calculate the indent that will// be passed to its childrenif(isLast){
Console.Write(_corner);
indent += _space;}else{
Console.Write(_cross);
indent += _vertical;}
Console.WriteLine(node.Name);// Loop through the children recursively, passing in the// indent, and the isLast parametervar numberOfChildren = node.Children.Count;for(var i =0; i < numberOfChildren; i++){var child = node.Children[i];var isLast =(i ==(numberOfChildren -1));PrintNode(child, indent, isLast);}}privatestatic List<Node>CreateNodeList(){// Load/Create the nodes from somewhere}}
This function gets very close to the desired output with one very small flaw - it draws a corner prefix on all of the top-level/root nodes:
The extra └─ prefix on the top-level Default node is undesirable. There's a couple of ways to fix it.
Add an extra bool isTopLevelNode to the PrintNode() function
Use a different function when printing the top level nodes
I've chosen to go with the latter in the final code, shown below.
Drawing the tree with the correct top-level node prefix
The code below is the complete solution for printing the example I showed earlier. I've omitted the CreateNodeList() function as it's rather verbose. You can see a complete example on GitHub. Alternatively, see the original PR that inspired this post.
Compared to the solution in the previous section, this solution extracts the PrintChildNode() method from PrintNode. This allows us to only print the indent and cross/corner for child nodes, without having to pass additional parameters (e.g. isTopLevelNode) around.
classProgram{// Constants for drawing lines and spacesprivateconststring _cross =" ├─";privateconststring _corner =" └─";privateconststring _vertical =" │ ";privateconststring _space =" ";staticvoidMain(string[] args){// Get the list of nodes
List<Node> topLevelNodes =CreateNodeList();foreach(var node in topLevelNodes){PrintNode(node, indent:"");}}staticvoidPrintNode(Node node,string indent){
Console.WriteLine(node.Name);// Loop through the children recursively, passing in the// indent, and the isLast parametervar numberOfChildren = node.Children.Count;for(var i =0; i < numberOfChildren; i++){var child = node.Children[i];var isLast =(i ==(numberOfChildren -1));PrintChildNode(child, indent, isLast);}}staticvoidPrintChildNode(Node node,string indent,bool isLast){// Print the provided pipes/spaces indent
Console.Write(indent);// Depending if this node is a last child, print the// corner or cross, and calculate the indent that will// be passed to its childrenif(isLast){
Console.Write(_corner);
indent += _space;}else{
Console.Write(_cross);
indent += _vertical;}PrintNode(node, indent);}privatestatic List<Node>CreateNodeList(){// Load/Create the nodes from somewhere}}
In these examples I have the corner/cross pieces descending from the second character of the parent node. Depending on how horizontally compact you'd like your tree to look, it's easy to tweak the various indent constants by adding additional space characters.
Summary
In this post I described the requirements for drawing an ASCII-art tree using C#. I highlighted the fact that each node appears to need to know about the status of all its parent nodes - a fact that makes the initial solution non-obvious. I then showed a solution that calculates a child node's indent in the parent node, and explicitly passes the indent as a method parameter to the child.
In this post I show how I added Azure DevOps CI to one of the .NET Standard library I have on GitHub. I'll walk through the various steps I took to get CI/CD working for pull requests and the master branch of an open source library. All of my current libraries are built using AppVeyor,using Linux and Windows, but I wanted to give the new Azure Pipelines service a test, just to try it out.
I'm not going to go into Azure DevOps/Pipelines itself much in this post - if you've not heard already, Azure DevOps is the new name for Visual Studio Online (née Visual Studio Team Services). VSO has been split into multiple Azure DevOps services, you only have to use the specific features you need. In my case, I don't need code hosting (I'm using GitHub), issue tracking (GitHub), artefact hosting (nuget.org/MyGet), or exploratory testing. All I wanted to try was the CI/CD service.
One of the interesting features of Azure Pipelines is that they offer hosted builds for Windows, Linux, and Mac. That last one is the most interesting - AppVeyor allows both Windows and Linux builds, but adding Mac builds requires adding in Travis or something else. With Azure Pipelines you could potentially consolidate on a single CI system, which is quite appealing. It's also completely free for open source projects (just as AppVeyor and Travis are).
Note, I didn't go all-in with Azure Pipelines - I'm still using AppVeyor as the canonical CI server that pushes to NuGet feeds etc; I'm just building with two CI providers for now. But that's mostly due to laziness as I already have a process in place for pushing NuGet packages!
In this post I assume you already have a library you want to build on GitHub, and a build script in place for it, but that you don't have an Azure DevOps account. I'm only going to show up to the point where we have our library being built. I'm not going to look at how to publish NuGet packages, or how to do releases in general.
1. Create your Azure DevOps account
The first step is to head to the Azure pipelines website and click "Start free with pipelines"
You'll be prompted to sign in to your Microsoft account, or to create a new one, until eventually you'll be prompted to choose an organisation name, and where your project will be hosted. Organisation names are globally unique, so you may need to do a bit of hunting.
After a little wait…
You'll be presented with the Azure DevOps dashboard!
2. Create a new project
Azure DevOps uses the concept of projects for organising your work. You could have a single project that contains multiple repositories and build pipelines, or you could use separate projects for each. I decided the latter probably makes the most sense for me - one project per GitHub project.
Azure DevOps prompts you to enter a name for your project (I used the name of my GitHub project, NetEscapades.Configuration). As you're linking to a public GitHub project, you can leave the project public.
3. Create a new build pipeline
After clicking "Create project" you'll be taken to the build pipeline configuration page:
When you click "New pipeline" you'll be presented with a wizard for getting your build up and running. This makes it easy to connect your GitHub repository to the Azure DevOps project.
After selecting "GitHub", you'll have to authorise Azure DevOps to have access to your repositories. At this point, the easiest way is to just click the Authorize with OAuth button:
Grant the necessary permissions to the Azure pipelines app:
and choose the repository you want to build.
After selecting a repository, you're encouraged to choose a pre-built template for the build pipeline. You can choose anything at this point, it just changes the YAML that's generated, and we're going to change that anyway.
If you select the ASP.NET Core template, you'll be presented with a template like the one below:
Azure pipelines uses a YAML file azure-pipelines.yml in the root of your repository to control the build process. When you click "Save and run", Azure DevOps will commit the azure-pipelines.yml file to your repo (you can choose either to commit directly to master, or to a branch) and start your first build. I believe you can configure a build without using a YAML file, but I wouldn't recommend that. Much better to keep the build specification versioned in your source code repository.
4. Customise the build process
Before we take a look at the builds themselves, lets take a quick look at the azure-pipelines.yml file itself. Rather than show the initial example file, I'll show the version I'm currently using with my NetEscapades.Configuration project. I've added comments throughout to explain the format and what it means.
Tip: Remember, YAML is whitespace and case sensitive, so take care!
# Only trigger CI builds for the master branch, instead # of every branch. You'll automatically be configured to # build PRs, but you can't currently control that from the YAML directly# For details, see https://docs.microsoft.com/en-us/azure/devops/pipelines/build/triggerstrigger:- master
# We can run multiple jobs in parallel. For this project# I'm running Linux, Windows, and macOS jobs. For syntac details# see https://docs.microsoft.com/en-us/azure/devops/pipelines/process/phasesjobs:# Provide a name for the job-job: Linux
# The VM image to use for the hosted agent. For a list of possible agents# see https://docs.microsoft.com/en-us/azure/devops/pipelines/agents/hosted# You can see the software installed on each agent at the same link.pool:vmImage:'ubuntu-16.04'# The steps to run to execute the build. I'm using# Cake, and so I execute a bash script on Linx and macOSsteps:-bash: ./build.sh
# You can set environment variables for the build. These# aren't really necessary, but they're here as an exampleenv:COREHOST_TRACE:0DOTNET_SKIP_FIRST_TIME_EXPERIENCE:1DOTNET_CLI_TELEMETRY_OPTOUT:1# Run a build on macOS at the same time-job: macOS
pool:vmImage:'xcode9-macos10.13'steps:-bash: ./build.sh
env:COREHOST_TRACE:0DOTNET_SKIP_FIRST_TIME_EXPERIENCE:1DOTNET_CLI_TELEMETRY_OPTOUT:1# Run a build on Windows at the same time-job: Windows
pool:vmImage:'vs2017-win2017'# The Windows build involves running a powershell script# to execute the Cake build scriptsteps:-powershell: .\build.ps1
env:COREHOST_TRACE:0DOTNET_SKIP_FIRST_TIME_EXPERIENCE:1DOTNET_CLI_TELEMETRY_OPTOUT:1
In my case, the YAML file to get three parallel builds is pretty short, primarily due to the use of Cake for my build script. The ability to easily switch between various machines, whether local, or different CI systems, and just have to run a single build script is one of the big reasons I enjoy using a build system like Cake.
It's worth noting that you can't currently configure everything using the YAML file. One notable aspect was the ability to control under exactly which circumstances a build runs. For example, you can't yet control (from YAML) whether PRs are built by Azure DevOps. As it's common, this functionality is added automatically, but if you wish to disable or customise it, you have to play around in the UI (Builds > Edit > Triggers > Pull Request Validation).
5. Viewing your builds
When you click "Save And Run" after customising your build template, you'll be taken to your building project! Here you'll be able to see the various steps as your app progresses, and see the streaming build logs.
If you've configured multiple jobs to run in parallel, you'll be able to switch between them and see how the build is progressing. After the build is complete you can go back and look through logs, view the test results, add tags etc. Hopefully everything goes smoothly and you get lots of big green ticks!
Support when things go wrong
When I first went through this process, I had some issues getting my builds to pass. The Windows builds were working fine but the Linux builds were very unreliable, failing with a variety of different errors. I was surprised (and impressed) when out of the blue I got this message on my PR branch, offering to help troubleshoot the issue:
After a bit of head-scratching, some trial-and-error, and help from various people on the Azure Pipelines team, we established that there were some issues with some of the hosted agents. A day later, everything was fixed, and the builds were passing. Obviously it wasn't fun trying to figure out why my app wouldn't build, but I can't fault the customer service, especially on a free service!
Conclusion
That's as far as I went with Azure DevOps. My project is building on Windows, macOS and Linux with Azure DevOps, and Linux and Windows with AppVeyor, and AppVeyor is managing my NuGet package releases. The release management features of Azure DevOps look top notch too, but I don't have any reason to give them a try yet when I already have a working process.
Overall, I'm impressed with the service, the UI certainly looks nice, and is generally pretty easy to navigate around, even to a newcomer. Having said that there are a lot of knobs and buttons you could play with, and I don't have a clue what they do! I hope they continue to improve the power of the YAML files so I can just control everything in there, whether it's the build process or release management.
ASP.NET Core has used the Options pattern to configure strongly typed settings objects since before version 1.0. Since then, the feature has gained more features. For example ASP.NET Core 1.1 introduced IOptionsSnapshot which allows your strongly typed options to update when the underlying IConfigurationRoot changes (e.g. when you change your appsettings.json file)
In this post I discuss your options when you want to register multiple instances of a strongly-typed settings object in the dependency injection container. In particular, I show how to use named options to register each configured object with a different name.
I'll start by recapping on how you typically use the options pattern with strongly typed settings, the IOptions<T> interface, and the IOptionsSnapshot<T> interface. Then I'll dig into three possible ways to register multiple instances of strongly typed settings in the the DI container.
Using strongly typed settings
The options pattern allows the use of strongly typed settings by binding POCO objects to an IConfiguration object. I covered this process in a recent post, so I'll be relatively brief here.
We'll start with a strongly typed settings object that you can bind to configuration, and inject into your services:
The Configure method binds your configuration (loaded from appsettings.json, environment variables, user secrets etc) to the SlackApiSettings object. You can also configure an IOptions<> object using an overload of Configure() that takes an Action<> instead of a configuration section, so you can use configuration in code, e.g.
You can access the configured SlackApiSettings object by injecting the IOptions<SlackApiSettings> interface into your services:
publicclassSlackNotificationService{privatereadonlySlackApiSettings _settings;publicSlackNotificationService(IOptions<SlackApiSettings> options){
_settings = options.Value
}publicvoidSendNotification(string message){// use the settings to send a message}}
The configured strongly typed settings object is available on the IOptions<T>.Value property. Alternatively, you can inject an IOptionsSnapshot<T> instead.
Handling configuration changes with IOptionsSnapshot<T>
The example I've shown so far is probably the most typical usage (though it's also common to avoid taking a dependency on IOptions<T> in your services). Using IOptions<T> for strongly typed configuration assumes that your configuration is fixed for the lifetime of the app. The configuration values are calculated and bound to your POCO objects once; if you later change your appsettings.json file for example, the changes won't show up in your app.
Personally, I've found that to be fine in virtually all my apps. However, if you do need to support reloading of configuration, you can do so with the IOptionsSnapshot<T> interface. This interface is configured at the same time as the IOptions<T> interface, so you don't have to do anything extra to use it in your apps. Simply inject it into your services, and access the configured settings object on the IOptionsSnapshot<T>.Value property:
If you later change the value of your configuration, e.g. by editing your appsettings.json file, the IOptionsSnapshot<T> will update the strongly typed configuration on the next request, and you'll see the new values. Note that the configuration values essentially have a "Scoped" lifetime - you'll see the same configuration values in IOptionsSnapshot<T> for the lifetime of the request.
Not all configuration providers support configuration reloading. The file-based providers all do but the environment variables provider doesn't, for example.
Reloading configuration could be useful in some cases, but IOptionsSnapshot<T> also has another trick up its sleeve - named options. We'll get to them shortly, but first we'll look at a problem you may run into occasionally where you need to have multiple instances of a settings object.
Using multiple instances of a strongly-typed settings object
The typical use case I see for IOptions<T> is for finely-grained strongly-typed settings. The binding system makes it easy for you to inject small, focused POCO objects for each specific service.
But what if you want to configure multiple objects which all have the same properties. For example, consider the SlackApiSettings I've used so far. To post a message to Slack, you need a WebHook URL, and a display name. The SlackNotificationService uses these values to send a message to a specific channel in Slack when you call SendNotification(message).
What if you wanted to update the SlackNotificationService to allow you to send messages to multiple channels. For example:
I've added methods for three different channels here Dev, General, Public. The question is, how do we configure the WebHook URL and Display Name for each channel? To provide some context, I'll assume that we're binding our configuration to a single appsettings.json file that looks like this:
There's a few options available to us in how we configure the settings for SlackNotificationService; I'll step through three of them below.
1. Create a parent settings object
One way to provide the settings for each channel would be to extend the SlackApiSettings object to include properties for each channel's settings. For example:
I've created a nested ChannelSettings object, and used a separate instance for each channel, with a property for each on the top-level SlackApiSettings. Configuring these settings is simple, as I was careful to match the appsettings.json and the SlackApiSettings hierarchy:
The advantage of this approach is that it's easy to understand what's going on, and it provides strongly typed access to each channel's settings. The downside is that adding support for another channel involves editing the SlackApiSettings class, which may not be possible (or desirable) in some cases.
2. Create separate classes for each channel
An alternative approach is to treat each channel's settings as independent. We would configure and register each channel settings object separately, and inject them all into the SlackNotificationService. For example, we could start with an abstract ChannelSettings class:
The advantage of this approach is that it allows you to add extra ChannelSettings without editing existing classes. It also makes it possible to inject a subset of the channel settings if that's all that's required. However it also makes things rather more complex to configure and use, with each new channel requiring a new options object, a new call to Configure(), and modifying the constructor of the SlackNotificationService.
3. Use named options
Which brings us to the focal point of this post - named options. Named options are what they sound like - they're strongly-typed configuration options that have a unique name. This lets you retrieve them by name when you need to use them.
With named options, you can have multiple instances of strongly-typed settings which are configured independently. That means we can continue to use the original SlackApiSettings object we defined at the start of the post:
We configure each channel separately using the appropriate configuration section (e.g. "SlackApi:DevChannel"), but we also provide a name as the first parameter to the Configure<T> call. This name allows us to retrieve the specific configuration from our consuming services.
To use these named options, you must inject IOptionsSnapshot<T>, notIOptions<T> into the SlackNotificationService. This gives you access to the IOptionsSnapshot<T>.Get(name) method, that you can use to retrieve the individual options.
The big advantage of this approach is that you don't need to create any new classes or methods to add a new channel, you just need to configure a new named SlackApiSettings options object. The constructor of SlackNotifictionService is untouched as well. On the disadvantage side, it's not clear from the SlackNotificationService constructor exactly which settings objects it's dependent on. Also, you're now truly dependent on the scoped IOptionsSnapshot<T> interface, so there's not an easy way to remove the IOptions<> dependency as I've described previously.
Which approach works best for you will depend on your requirements and your general preferences. Option 1 is the simplest in many ways, and if you don't expect any extra instances of the options object to be added then it may be a good choice. Option 2 is handy if additional instances might be added later, but you control when they're added (and so can update the consumer service as required). Option 3 is particularly useful when you don't have control over when new options are added. For example, the ASP.NET Core framework itself uses named options for authentication options, where new authentication handlers can be used that the core framework has no knowledge of.
Summary
In this post I provided a recap on how to use strongly typed settings with the Options pattern in ASP.NET Core. I then discussed a requirement to register multiple instances of strongly typed settings in the ASP.NET Core DI container. I described three possible ways to achieve this: creating a parent settings object, creating separate derived classes for each setting, or using named options. Named options can be retrieved using the IOptionsSnapshot<T> interface, using the Get(name) method.
The configuration system in ASP.NET Core allows you to load key-value pairs from a wide variety of sources such as JSON files, Environment Variables, or Azure KeyVault. The recommended way to consume those key-value pairs is to use strongly-typed classes using the Options pattern.
In this post I look at some of the problems you can run into with strong-typed settings. In particular, I show how you can run into lifetime issues and captive dependencies if your configuration depends on other services, via the IConfigureOptions<> mechanism.
I start by providing a brief overview of strongly-typed configuration in ASP.NET Core and the difference between IOptions<> and IOptionsSnapshot<>. I then describe how you can inject services when building your strongly-typed settings using IConfigureOptions<>. Finally, I look at what happens if you try to use Scoped services with IConfigureOptions<>, the problems you can run into, and how to work around them.
tl;dr; If you need to use Scoped services inside IConfigureOptions<>, create a new scope using IServiceProvider.CreateScope() and resolve the service directly. Be aware that the service lives in its own scope, separate from the main scope associated with the request.
Strongly-typed settings in ASP.NET Core
The most common approach to using strongly-typed settings in ASP.NET Core is to bind you key-value pair configuration values to a POCO object T in the ConfigureServices() method of Startup. Alternatively, you can provide a configuration Action<T> for your settings class T. When an instance of your settings class T is requested, ASP.NET Core will apply each of the configuration steps in turn:
publicvoidConfigureServices(IServiceCollection services){// Bind MySettings to configuration section "MyConfig"
services.Configure<MySettings>(Configuration.GetSection("MyConfig"));// Configure MySettings using an Action<>
services.Configure<MySettings>(options =>{
options.MyValue ="Some value"});}
To access the configured MySettings object in your classes, you inject an instance of IOptions<MySettings> or IOptionsSnapshot<MySettings> into the constructor of the class that depends on them. The configured settings object itself is available on the Value property:
publicclassValuesController{privatereadonlyMySettings _settings;publicValuesController(IOptions<MySettings> settings){
_settings = settings.Value;//access the settings}[HttpGet]publicstringGet()=> _settings.MyValue;}
It's important to note that order matters when configuring options. When you inject an IOptions<MySettings> or IOptionsSnapshot<MySettings> in your app, each configuration method runs sequentially. So for the ConfigureServices() method shown previously, the MySettings object would first be bound to the MyConfig configuration section, and then the Action<> would be executed, overwriting the value of MyValue.
The difference between IOptions<> and IOptionsSnapshot<>
In the previous example I showed an example of injecting an IOptions<T> instance into a controller. The other way of accessing your settings is to inject an IOptionsSnapshot<T>. As well as providing access to the configured strongly-typed options <T>, this interface provides several additional features compared to IOptions<T>:
Access to named options.
Changes to the underlying IConfiguration object are honoured.
Has a Scoped lifecycle (IOption<>s have a Singleton lifecycle).
Named options
I discussed named options in my previous post. Named options allow you to register multiple instances of a strongly-typed settings class (e.g. MySettings), each with a different string name, for example:
You can then use IOptionsSnapshot<T> to retrieve these named options using the Get() method:
publicValuesController(IOptionsSnapshot<MySettings> settings){var aliceSettings = settings.Get("Alice");// get the Alice settingsvar bobSettings = settings.Get("Bob");// get the Bob settingsvar mySettings = settings.Value;// get the default, unnamed, settings}
Reloading strongly typed configuration with IOptionsSnapshot
One of the most common uses of IOptionSnapshot<> is to enable automatic configuration reloading, without having to restart the application. Some configuration providers, most notably the file-providers that load settings from JSON files etc, will automatically update the underlying key-value pairs that make up and IConfiguration object when the configuration file changes.
The MySettingssettings object associated with an IOptions<MySettings> instance won't change when you update the underlying configuration file. The values are fixed the first time you access the IOptions<T>.Value property.
IOptionsSnapshot<T> works differently. IOptionsSnapshot<T> re-runs the configuration steps for your strongly-typed settings objects once per request when the instance is requested. So if a configuration file changes (and hence the underlying IConfiguration changes), the properties of the IOptionsSnapshot.Value instance will reflect those changes on the next request.
I discussed reloading of configuration values in more detail in a previous post.
Related to this, the IOptionsSnapshot<T> has a Scoped lifecycle, so for a single request you will use the same IOptionsSnapshot<T> instance throughout your application. That means the strongly-typed configuration objects (e.g. MySettings) are constant within a given request, but may vary between requests.
Note: As the strongly-typed settings are re-built with every request, and the binding relies on reflection under the hood, you should bear performance in mind. There is currently an open issue on GitHub to investigate performance.
I'll come back to the different lifecycles for IOptions<> and IOptionsSnapshot<> later, as well as the implications. First, I'll describe another common question around strongly-typed settings - how can you use additional services to configure them?
Using services during options configuration
Configuring strongly-typed options with the Configure<>() extension method is very common. However, sometimes you need additional services to configure your strongly-typed settings. For example, imagine that configuring your MySettings class requires loading values from the database using EF Core, or performing some complex operation that is encapsulated in a CalculatorService. You can't access services you've registered in ConfigureServices() from inside ConfigureServices() itself, so you can't use the Configure<>() method directly:
publicvoidConfigureServices(IServiceCollection services){// register our helper service
services.AddSingleton<CalculatorService>();// Want to set MySettings based on values from the CalculatorService
services.Configure<MySettings>(settings =>{// No easy/safe way of accessing CalculatorService here!});}
Instead of calling Configure<MySettings>, you can create a simple class to handle the configuration for you. This class should implement IConfigureOptions<MySettings> and can use dependency injection to inject dependencies that you registered in ConfigureServices:
All that remains is to register the IConfigureOptions<> instance (and its dependencies) in Startup.ConfigureServices():
publicvoidConfigureServices(IServiceCollection services){// You can combine Configure with IConfigureOptions
services.Configure<MySettings>(Configuration.GetSection("MyConfig"));// Register the IConfigureOptions instance
services.AddSingleton<IConfigureOptions<MySettings>, ConfigureMySettingsOptions>();// Add the dependencies
services.AddSingleton<CalculatorService>();}
When you inject an instance of IOptions<MySettings> into your controller, the MySettings instance will be configured based on the configuration section "MyConfig", followed by the configuration applied in ConfigureMySettingsOptions using the CalculatorService.
Using IConfigureOptions<T> makes it trivial to use other services and dependencies when configuring strongly-typed options. Where things get tricky is if you need to use scoped dependencies, like an EF Core DbContext.
A slight detour: scoped dependencies in the ASP.NET Core DI container
In order to understand the issue of using scoped dependencies in IConfigureOptions<> we need to take a short detour to look at how the DI container resolves instances of services. For now I'm only going to think about Singleton and Scoped services, and will leave out Transient services.
Every ASP.NET Core application has a "root" IServiceProvider. This is used to resolve Singleton services.
In addition to the root IServiceProvider it's also possible to create a new scope. A scope (implemented as IServiceScope) has its own IServiceProvider. You can resolve Scoped services from the scoped IServiceProvider; when the scope is disposed, all disposable services created by the container will also be disposed.
In ASP.NET Core, a new scope is created for each request. That means all the Scoped services for a given request are resolved from the same container, so the same instance of a Scoped service is used everywhere for a given request. At the end of the request, the scope is disposed, along with all the resolved services. Each request gets a new scope, so the Scoped services are isolated from one another.
In addition to the automatic scopes created each request, it's possible to create a new scope manually, using IServiceProvider.CreateScope(). You can use this to safely resolve Scoped services outside the context of a request, for example after you've configured your application, but before you call IWebHost.Run(). This can be useful when you need to do things like run EF Core migrations, for example.
But why would you need to create a scope outside the context of a request? Couldn't you just resolve the necessary dependencies directly from the root IServiceProvider?
While that's technically possible, doing so is essentially a memory leak, as the Scoped services are not disposed, and effectively become Singletons! This is sometimes called a "captive dependency". By default, the ASP.NET Core framework checks for this error when running in the Development environment, and throws an InvalidOperationException at runtime. In Production the guard rails are off, and you'll likely just get buggy behaviour.
Which brings us to the problem at hand - using Scoped services with IConfigureOptions<T> when you are configuring strongly-typed settings.
Scoped dependencies and IConfigureOptions: Here be dragons
Lets consider a relatively common scenario: I want to load some of the configuration for my strongly-typed MySettings object from a database using EF Core. As we're using EF Core, we'll need to use the DbContext, which is a Scoped service. To simplify things slightly further for this demo, we'll imagine that the logic for loading from the database is encapsulated in a service, ValueService:
publicclassValueService{privatereadonlyGuid _val = Guid.NewGuid();// Return a fixed Guid for the lifetime of the servicepublicGuidGetValue()=> _val;}
We'll imagine that the GetValue() method fetches some configuration from the database, and we want to set that value on a MySettings object. In our app, we might be using IOptions<> or IOptionsSnapshot<>, we're not sure yet.
As we need to use the ValueService to configure the strongly-typed settings MySettings, we know we'll need to use an IConfigureOptions<> implementation, which we'll call ConfigureMySettingsOptions. Initially, we have two questions:
What lifecycle should we use to register the ConfigureMySettingsOptions instance?
How should we resolve the Scoped ValueService inside the ConfigureMySettingsOptions instance?
I'll explore the various possibilities in the following sections, showing basic implementations, and the implications of choosing each one.
For demonstration purposes, I'll create a simple Controller that returns the value set for IOptions<MySettings>:
publicclassValuesController{privatereadonly IOptions<MySettings> _settings;publicValuesController(IOptions<MySettings> settings){
_settings = settings;}[HttpGet]publicstringGet(){return $"The value is: {_settings.Value.MyValue}";}}
1. Registering IConfigureOptions<> as Scoped, and injecting Scoped services
The first option, and probably the easiest option on the face of it, is to inject the Scoped ValueService directly into the ConfigureMySettingsOptions instance:
Warning Don't use this code! It causes a captive dependency / InvalidOperationException!
publicclassConfigureMySettings:IConfigureOptions<MySettings>{// Directly inject the Scoped serviceprivatereadonlyValueService _service;publicConfigureMySettings(ValueService service){
_service = service;}publicvoidConfigure(MySettings options){// Use the scoped service to set the value
options.MyValue = _service.GetValue();}}
As we're injecting a Scoped service into ConfigureMySettingsOptions we must register ConfigureMySettingsOptions as a Scoped service - we can't register it as a Singleton service as we'd have a captive dependency issue:
Unfortunately, if we call our test ValuesController, we still get an InvalidOperationException, despite our best efforts:
System.InvalidOperationException: Cannot consume scoped service'Microsoft.Extensions.Options.IConfigureOptions`1[MySettings]' from singleton 'Microsoft.Extensions.Options.IOptions`1[MySettings]'.
The problem is that IOptions<> instances are registered as Singletons and take all of the registered IConfigureOptions<> instances as dependencies. As we've registered our IConfigureOptions<> as a Scoped service, we have a captive dependency problem, so in the Development environment, ASP.NET Core throws an Exception to warn us. Back to the drawing board.
2. Registering IConfigureOptions<> as Scoped, injecting Scoped services, and using IOptionsSnapshot<>
One workaround to the captive dependency issue is to avoid using the Singleton IOptions<T> altogether. As I discussed earlier, IOptionsSnapshot<T> is registered as a Scoped service, rather than a Singleton. If we change our ValuesController to use IOptionsSnapshot<> instead:
publicclassValuesController{privatereadonly IOptionsSnapshot<MySettings> _settings;publicValuesController(IOptionsSnapshot<MySettings> settings){
_settings = settings;}[HttpGet]publicstringGet(){return $"The value is: '{_settings.Value.MyValue}'";}}
then running the application doesn't cause a captive dependency, and we can hit the API multiple times:
>curl http://localhost:5000/api/Values
The value is: 'eadf7bc2-250a-43b8-94b4-31a276533c68'>curl http://localhost:5000/api/Values
The value is: '5daf0dda-a9b7-40e6-b4b8-2ed69559a4d9'
One point to note is that the value of MySettings.MyValue changes with every request. That's because we're re-building the MySettings object each request, and fetching a new Scoped instance of ValueService with each request.
Depending on your app, the approach of injecting Scoped services directly into IConfigureOptions<> and using IOptionsSnapshot<>might be ok. Especially if you were going to use IOptionsSnapshot<> anyway to track configuration changes.
Personally, I don't think that's a great idea - it would just take someone who's unfamiliar with the restriction to use IOptions<>, and they'll get unexpected InvalidOperaionExceptions, or worse, captive dependencies in a Production environment!
This solution is even more unattractive if you don't actually need the change-tracking features ofIOptionsSnapshot (and associated performance impact). In that case, you'll want to look behind door number 3…
3. Creating a new scope in IConfigureOptions
The alternative to directly injecting a ValueService into ConfigureMySettingsOptions is to manually create a new scope, and to resolve the ValueService instance directly from the IServiceProvider:
publicclassConfigureMySettings:IConfigureOptions<MySettings>{// Inject the IoC providerprivatereadonlyIServiceProvider _provider;publicConfigureMySettings(IServiceProvider provider){
_provider = provider;}publicvoidConfigure(MySettings options){// Create a new scopeusing(var scope = _provider.CreateScope()){// Resolve the Scoped servicevar service = scope.ServiceProvider.GetService<ValueService>();
options.MyValue = service.GetValue();}}}
Inject the "root" IServiceProvider into the constructor of your IConfigureOptions<> class, and call CreateScope() inside the Configure() method. This allows you to resolve the Scoped service, even though ConfigureMySettingsOptions is registered as a Singleton (or Transient):
Now you can inject IOptions<MySettings> into your ValuesController without fear of captive dependencies. On the first request to ValuesController, ConfigureMySettings.Configure() is invoked which creates a new scope, resolves the scoped service, sets the value of MyScopedValue, and then disposes the scope (thanks to the using statement). On subsequent requests, the same MySettings object is returned, so it always has the same value:
>curl http://localhost:5000/api/Values
The value is: '5380796b-75e3-4b21-8b96-74afedccda28'>curl http://localhost:5000/api/Values
The value is: '5380796b-75e3-4b21-8b96-74afedccda28'
In contrast, if you inject IOptionsSnapshot<MySettings> into ValuesController, MySettings is re-bound every request, and ConfigureMySettings.Configure() is invoked on every request. That gives you a new value every time:
>curl http://localhost:5000/api/Values
The value is: 'b4bb050a-0f53-44a3-a3fc-9451136e78db'>curl http://localhost:5000/api/Values
The value is: 'a3675eab-8f9a-4472-b0af-bc2f34c65bdb'
Generally speaking, this gives you the best of both worlds - you can use both IOptions<> and IOptionsSnapshot<> as appropriate, and you don't have any captive dependency issues. There's just one caveat to watch out for…
Watch your scopes
You registered ValueService as a Scoped service, so ASP.NET Core uses the same instance of ValueService to satisfy all requests for a ValueServicewithin a given scope. In almost all cases, that means all instances of a Scoped service for a given request are the same.
However…
Our solution to the captive dependency problem was to create a new scope. Even when we're building a Scoped object, e.g. an instance of IOptionsSnapshot<>, we always create a new Scope inside ConfigureMySettingsOptions. Consequently, you will have two different instances of ValueService for a given request:
The ValueService instance associated with the scope we created in ConfigureMySettingsOptions.
The ValueService instance associated with the request's scope.
One way to visualise the issue is to inject ValueService directly into the controller, and compare its GetValue() with the value set on MySettings.MyValue:
For each request, the value of _service.GetValue() is different to MySettings.MyValue, because the ValueService used to set MySettings.MyValue was a different instance that the one used in the rest of the request:
Generally, I don't think so. Strongly-typed settings are typically that, just settings and configuration. I think it would be unusual to be in a situation where being in a different scope matters, but its worth bearing in mind.
One possible scenario I could imagine is where you're using a DbContext in your IConfigureOptions<> instance. Given you're creating the DbContext out of the usual request scope, the DbContext wouldn't be subject to any session management services for handling SaveChanges(), or committing and rolling back transactions for example. But then, writing to the database in the IConfigureOptions.Configure() method seems like a bad idea anyway, so you're probably trying to force a square peg into a round hole at that point!
Summary
In this post I provided an overview of how to use strongly-typed settings with ASP.NET Core. In particular, I highlighted how IOptions<> is registered as Singleton service, while IOptionsSnapshot<> is registered as a Scoped service. It's important to bear that difference in mind when using IConfigureOptions<> with Scoped services to configure your strongly-typed settings.
If you need to use Scoped services when implementing IConfigureOptions<>, you should inject an IServiceProvider into your class, and manually create a new scope to resolve the services. Don't inject the services directly into your IConfigureOptions<> instance as you will end up with a captive dependency.
When using this approach you should be aware that the scope created in IConfigureOptions<> is distinct from the scope associated with the request. Consequently, any services you resolve from it will be different instances to those resolved in the rest of your application
In my previous post I looked in depth at the scenario named options are designed to solve. Named options provide a solution where you want to have multiple instances of a strongly-typed settings class, each of which can be resolved from the DI container.
In my previous post, I used the scenario where you want to have an arbitrary number of settings for sending messages to Slack using WebHooks. For example, imagine you have the following strongly-typed settings object:
Each instance is given a unique name (the first parameter to the Configure() method), and a configuration section to bind. You access these settings using the IOptionsSnapshot<> interface method and its Get(name) method:
publicclassSlackNotificationService{publicSlackNotificationService(IOptionsSnapshot<SlackApiSettings> options){// fetch the settings for each channelSlackApiSettings devSettings = options.Get("Dev");SlackApiSettings generalSettings = options.Get("General");SlackApiSettings publicSettings = options.Get("Public");}}
It's worth remembering that IOptionsSnapshot<T>re-binds options when they're requested (once every request). This differs from IOptions which binds options once for the lifetime of the app. As named options are typically exposed using IOptionsSnapshot<T>, they are similarly bound once-per request.
Named options vs the default options instance
You can use named options and the default options in the same application, and they won't interfere. Calling Configure() without specifying a name targets the default options, for example:
publicvoidConfigureServices(IServiceCollection services){// Configure named options
services.Configure<SlackApiSettings>("Dev", Configuration.GetSection("SlackApi:DevChannel"));
services.Configure<SlackApiSettings>("Public", Configuration.GetSection("SlackApi:PublicChannel"));// Configure the default "unnamed" options
services.Configure<SlackApiSettings>(Configuration.GetSection("SlackApi:GeneralChannel"));}
You can retrieve the default options using the Value property on IOptions<T> or IOptionsSnapshot<T>:
publicclassSlackNotificationService{publicSlackNotificationService(IOptionsSnapshot<SlackApiSettings> options){// fetch the settings for each channelSlackApiSettings devSettings = options.Get("Dev");SlackApiSettings publicSettings = options.Get("Public");// fetch the default unnamed optionsSlackApiSettings defaultSettings = options.Value;}}
Even if you don't explicitly use named options in your applications, the Options framework itself uses named options under the hood. When you call the Configure<T>(section) extension method (without providing a name), the framework calls the named version of the extension method behind the scenes, using Options.DefaultName as the default name:
Options.DefaultName is set to string.Empty, so the following two lines have the same effect - they configure the default options object:
publicvoidConfigureServices(IServiceCollection services){
services.Configure<SlackApiSettings>(Configuration.GetSection("SlackApi:GeneralChannel"));// Using string.Empty as the named options type
services.Configure<SlackApiSettings>(string.Empty, Configuration.GetSection("SlackApi:GeneralChannel"));}
This is an important thing to bear in mind for this post - the default options are just named options with a specific name: string.Empty.
For the rest of this post I show some of the ways to configure named options in particular, compared to their default "unnamed" counterpart.
Injecting services into named options with IConfigureNamedOptions<T>
It's relatively common to require an external service when configuring your options. I've written previously about how to use IConfigureOptions<T> to access services when configuring options. In my last post, I discussed some of the issues to watch out for when those services are registered as Scoped services.
In all of those posts, I described how to configure the default options using IConfigureOptions<T>. There is also an equivalent interface you can implement to configure named options, called IConfigureNamedOptions<T>:
Configure(name, options) - implemented by the interface directly
Configure(options) - implemented by IConfigureOptions<T> (which it inherits)
When implementing the interface, it's important to understand that Configure(name, options) will be called for every instance of the options objects T that are instantiated in your application. That includes all named options, including the default options. It's up to you to check which instance is currently being configured at runtime.
Implementing IConfigureNamedOptions<T> for a specific named options instance
I think the the easiest way to understand IConfigureNamedOptions<T> is with an example. Lets consider a situation based on the Slack WebHooks scenario I described earlier. You have multiple WebHook URLs your app must call, which are configured in appsettings.json and are bound to separate named instances of SlackApiSettings. In addition, you have a default options instance. These are all configured as I described earlier:
Now imagine that the WebHook URL for the named instance "Public" is not known in advance, and so can't be added to appsettings.json. Instead you have a separate service PublicSlackDetailsService that can be called to find the URL:
Note that the GetPublicWebhookUrl() method is synchronous, not async. Options configuration occurs inside a DI container when constructing an object, so it's not a good place to be doing asynchronous things like calling remote end points. If you find you need this capability, consider using other patterns such as a factory object instead of Options.
The PublicSlackDetailsService service is registered as a Singleton in ConfigureServices():
Important: if you need to use Scoped services to configure your named options, see my previous post.
By implementing IConfigureNamedOptions<T>, you can configure a specific named options instance ("Public") using the PublicSlackDetailsService service:
publicclassConfigurePublicSlackApiSettings:IConfigureNamedOptions<SlackApiSettings>{// inject the PublicSlackDetailsService directlyprivatereadonlyPublicSlackDetailsService _service;publicConfigurePublicSlackApiSettings(PublicSlackDetailsService service){
_service = service;}// Configure the named instancepublicvoidConfigure(string name,SlackApiSettings options){// Only configure the options if this is the correct instanceif(name =="Public"){
options.WebhookUrl = _service.GetPublicWebhookUrl();}}// This won't be called, but is required for the interfacepublicvoidConfigure(SlackApiSettings options)=>Configure(Options.DefaultName, options);}
It's easy to restrict ConfigurePublicSlackApiSettings to only configure the "Public" named instance. A simple check of the name parameter passed to Configure(name, options) avoids configuring both other named instances (e.g. "Dev") or the default instance (name will be string.Empty).
The other thing to note is that the Configure(options) method (required by the IConfigureOptions interface) delegates to the Configure(name, options) method, using the name Options.DefaultName. Technically speaking, this isn't really necessary: the options infrastructure used to create options (OptionsFactory) always preferentially calls Configure(name, options) when its available. However, the example shown should be considered a best practice.
The last thing to do is register the ConfigurePublicSlackApiSettings class with the DI container in ConfigureServices():
publicvoidConfigureServices(IServiceCollection services){// Configure the options objects using appsettings.json
services.Configure<SlackApiSettings>("Dev", Configuration.GetSection("SlackApi:DevChannel"));
services.Configure<SlackApiSettings>("Public", Configuration.GetSection("SlackApi:PublicChannel"));
services.Configure<SlackApiSettings>(Configuration.GetSection("SlackApi:GeneralChannel"));// Add required service
services.AddSingleton<PublicSlackDetailsService>();// Add named options configuration AFTER other configuration
services.AddSingleton<IConfigureOptions<SlackApiSettings>, ConfigurePublicSlackApiSettings>);}
Important: note that you must register as an IConfigureOptions<T> instance, not an IConfigureNamedOptions<T> instance! Also, as with all options configuration, order is important.
Whenever you request an instance of SlackApiSettings using IOptionsSnapshot<T>.Get(), the ConfigurePublicSlackApiSettings.Configure(name, options) method will be executed. The "Public" instance will have its WebhookUrl property updated, an all other named options will be ignored.
Now, I said earlier that the default options instance is just a named options instance with the special name string.Empty. I also said that IConfigureNamedOptions<T> is called for all named settings. This includes when the default options instance is requested using IOptions<T>.Value. ConfigurePublicSlackApiSettings handles this as the name passed to Configure(name, options) will be string.Empty so our code gracefully ignores it, the same as any other named options.
Configuring all options objects with ConfigureAll<T>
Use services to configure named options with IConfigureNamedOptions (this post)
One thing I haven't shown is how to configure all options at once: both named options and the default options. If you're binding to configuration sections or using an Action<>, the easiest approach is to use the ConfigureAll() extension method
publicvoidConfigureServices(IServiceCollection services){// Configure ALL options instances, both named and default
services.ConfigureAll<SlackApiSettings>(Configuration.GetSection("SlackApi:GeneralChannel"));
services.ConfigureAll<SlackApiSettings>(options => options.DisplayName ="Unknown");// Override values for named options
services.Configure<SlackApiSettings>("Dev", Configuration.GetSection("SlackApi:DevChannel"));
services.Configure<SlackApiSettings>("Public", Configuration.GetSection("SlackApi:PublicChannel"));// Override values for default options
services.Configure<SlackApiSettings>(()=> options.DisplayName ="default");}
In this example, we bind every options object that we request to the "SlackApi:GeneralChannel" configuration section, and also set the DisplayName to "Unknown". Then depending on the name of the options instance requested, another configuration step may take place:
If the default instance is requested (using IOptions<T>.Value or IOptionsSnapshot<T>.Value, the DisplayName is set to "default")
If the "Dev" named instance is requested, the instance is bound to the "SlackApi:DevChannel" configuration section
If the "Public" named instance is requested, the instance is bound to the "SlackApi:PublicChannel" configuration section
If any other named instance is requested, no further configuration occurs.
This raises another important point:
You can request a named options instance that has not been explicitly registered.
Configuring all options in this way is convenient when you can use a simple Action<> or bind to a configuration section, but what if you need to use a service like PublicSlackDetailsService? In that case, you're back to implementing IConfigureNamedOptions<T>.
Using injected services when configuring all options instances
For simplicity's sake, we'll extend the scenario we described earlier. Instead of using PublicSlackDetailsService to set the WebhookUrl for only the "Public" named options instance, we'll imagine we need to set the value for every named options instance, including the default options. Luckily, all we need to do is remove the if() statement from our previous implementation, and we're pretty much there:
publicclassConfigureAllSlackApiSettings:IConfigureNamedOptions<SlackApiSettings>{// inject the PublicSlackDetailsService directlyprivatereadonlyPublicSlackDetailsService _service;publicConfigurePublicSlackApiSettings(PublicSlackDetailsService service){
_service = service;}// Configure all instancespublicvoidConfigure(string name,SlackApiSettings options){// we don't care which instance it is, just set the URL!
options.WebhookUrl = _service.GetPublicWebhookUrl();}// This won't be called, but is required for the interfacepublicvoidConfigure(SlackApiSettings options)=>Configure(Options.DefaultName, options);}
All that remains is to register the ConfigureAllSlackApiSettings in the default container. Remember that order matters for option configuration: if you want ConfigureAllSlackApiSettings to run before other configuration it should appear before other Configure() methods in ConfigureServices; otherwise it should appear after them:
publicvoidConfigureServices(IServiceCollection services){// Configure ALL options instances, both named and default
services.ConfigureAll<SlackApiSettings>(options => options.DisplayName ="Unknown");// Override values for named options
services.Configure<SlackApiSettings>("Dev", Configuration.GetSection("SlackApi:DevChannel"));
services.Configure<SlackApiSettings>("Public", Configuration.GetSection("SlackApi:PublicChannel"));// Add ALL options configuration AFTER other configuration (in this case)
services.AddSingleton<IConfigureOptions<SlackApiSettings>, ConfigureAllSlackApiSettings>);}
With Configure<T>(), ConfigureAll<T>(), IConfigureOptions<T>, and IConfigureNamedOptions<T> you have a wide range of tools for configuring both the default options and the named options in your application. IConfigureNamedOptions<T> is especially flexible - it's easy to apply configuration to all of your options instance, to a subset, or to a specific named instance.
However, as always, it's best to choose the simplest approach that gets the job done. Don't need named options? Don't use them. Need to bind to a configuration section? Just use Configure<T>(). KISS rules, but it's good to know the flexibility is there if you need it.
Summary
In this post I described how the default options object is a special case of named options, with a name of string.Empty. I showed how you could configure options that required other injected services by implementing IConfigureNamedOptions<T>, and how you could limit which options it applies too.
I also showed how you can apply configuration to all options, including both named and default instances, using the ConfigureAll<T>() extension method. Finally, I showed how you could achieve the same thing using IConfigureNamedOptions<T> when you need access to other services for configuration.
If you're implementing IConfigureNamedOptions<T> it's important to consider the lifecycle of the services you're using. In particular, you'll need to take extra steps to consume Scoped services, as I described in my previous post.
In this post I describe a scenario in which a library author wants to use the Options pattern to configure their library, and enforce some default values / constraints. I describe the difficulties with trying to achieve this using the standard Configure<T>() method for strongly-typed options, and introduce the concept of "post" configuration actions such as PostConfigure<T>() and PostConfigureAll<T>().
tl;dr; If you need to ensure a configuration action for a strongly-typed settings instance runs after all other configuration actions, you can use the PostConfigure<T>() method. Actions registered using this method are executed in the order they are registered, but after all other Configure<T>() actions have been applied.
Using the Options pattern as a library author
The Options pattern is the standard way to add strongly-typed settings to ASP.NET Core applications, by binding POCO objects to a configuration object consisting of key-value pairs. If you're building a library designed for ASP.NET Core, using the Options pattern to configure your library is a standard approach to take.
ASP.NET Core strongly-typed settings are configured for your application in Startup.ConfigureServices(), typically by calling services.Configure<MySettings>() to configure a strongly-typed settings object MySettings. You can use multiple configuration "steps" to configure a single MySettings instance, where each step corresponds to a Configure<MySettings>() invocation. The order that the Configure<MySettings>() calls are made controls the order in which configuration is "applied" to MySettings, and hence its final properties.
publicvoidConfigureServices(IServiceCollection services){
services.Configure<MySettings>(Configuration.GetSection("MySettings"));
services.Configure<MySettings>(opts => opts.SomeValue ="Overriden");// Overrides SomeValue property (which may have been set in the previous Configure call)}
As a library author, this can be both useful and a challenge. On the positive side, if you use the Options pattern then users of your library will have a familiar and extensible mechanism for configuring your library. On the other hand, you lose some control over when and how your library is configured.
An example library using options
Lets explore this a little. Imagine you have a service that sends WhatsApp messages to users. You have a hosted API service that users can register with, which you've also open sourced. Users can send requests to the hosted API service to send a message to a user via WhatsApp. Alternatively, as it's open source, users could also host their own instance of the API to send messages, instead of using your hosted service.
You've also created a simple .NET Standard library that users can use to call the API. At the heart of the library is the IWhatsAppService:
which is implemented as WhatsAppService (not shown). There are a number of configuration settings required, for which you've created a strongly-typed settings object, and provided default values:
The details of this aren't really important, what's more important is that there is a specific rule you need to enforce: when the ApiUrl is set to Constants.DefaultHostedUrl, the Region must be set to DefaultHostedRegion.
By default, the WhatsAppSettings instance will have the correct values for the hosted service, but the user is free to update the values to point to another API if they wish. What we don't want to happen (and which we'll come to shortly) is for the user to change the Region, while still using the default ApiUrl.
To help the user add your library to their application, you've created a couple of extension methods they can call in ConfigureServices():
publicstaticclassWhatsAppServiceCollectionExtensions{publicstaticIServiceCollectionAddWhatsApp(thisIServiceCollection services){// Add ASP.NET Core Options libraries - needed so we can use IOptions<WhatsAppSettings>
services.AddOptions();// Add our required services
services.AddSingleton<IWhatsAppService,WhatsAppService>();return services;}}
This extension method registers all the required services with the DI container. To add the library to an ASP.NET Core application in Startup.ConfigureServices(), and to keep the defaults, you would use
So that's our library. The question is, how do we ensure that if the user uses the default hosted URL DefaultHostedUrl, the region is always set to DefaultHostedRegion.
Enforcing constraints on strongly-typed settings
I'm going to leave aside the whole question of whether strongly-typed options are the right place to enforce these sorts of constraints, as well as the fact API URLs definitely shouldn't be hard coded as constants! This whole scenario is just for me to introduce a feature, so just go with it! 😁
As the library author, we know that we need to add a configuration action for WhatsAppSettings to enforce the constraint on the hosted region. As an initial attempt we simply add the configuration action to the AddWhatsApp extension method:
publicstaticclassWhatsAppServiceCollectionExtensions{publicstaticIServiceCollectionAddWhatsApp(thisIServiceCollection services){
services.AddOptions();
services.AddSingleton<IWhatsAppService,WhatsAppService>();// Add configuration action for WhatsAppSettings
services.Configure<WhatsAppSettings>(options =>{if(options.ApiUrl == Constants.DefaultUrl){// if we're using the hosted service URL, use the correct region
options.Region = Constants.DefaultHostedRegion;}});return services;}}
Unfortunately, this approach isn't very robust. As I've discussed in severalpreviousposts, configuration actions are applied to a strongly-typed settings instance in the same order that they are added to the DI container. That means if the user calls Configure<WhatsAppSettings>()after they call AddWhatsApp(), they will overwrite any changes enforced by the extension method:
publicvoidConfigureServices(IServiceCollection services){// Add the necessary settings and also enforce the hosted service region constraint
services.AddWhatsApp();// Add another configuration action, overwriting previous configuration
services.Configure<WhatsAppSettings>(options =>{
options.ApiUrl = Constants.DefaultUrl;
options.ApiKey ="MY-KEY-123456"
options.Region ="us-east3";// "Oh noes, wrong one!"});}
This highlights one of the fundamental difficulties of working with a DI container where the order things are added to the container matters, and you (the library author) are fundamentally not in control of that process. Luckily there's a solution to this by way of the PostConfigure<T>() family of extension methods.
Configuring strongly-typed options last with PostConfigure()
PostConfigure<T>() is an extension method that works very similarly to the Configure<T>() method, with one exception - PostConfigure<T>() configuration actions run after allConfigure<T>() actions have executed. So when configuring a strongly typed settings object, the Options framework will run all "standard" configuration actions (in the order they were added to the DI container), followed by all "post" configuration actions (in the order they were added to the DI container).
This provides a nice, simple solution to our scenario. We can update the AddWhatsApp() extension method to use PostConfigure<T>(), and then we can be sure that it will run after any standard configuration actions:
publicstaticclassWhatsAppServiceCollectionExtensions{publicstaticIServiceCollectionAddWhatsApp(thisIServiceCollection services){
services.AddOptions();
services.AddSingleton<IWhatsAppService,WhatsAppService>();// Use PostConfigure to ensure it runs after normal configuration
services.PostConfigure<WhatsAppSettings>(options =>{if(options.ApiUrl == Constants.DefaultUrl){
options.Region = Constants.DefaultHostedRegion;}});return services;}}
Now users can place their call to Configure<WhatsAppSettings>() anywhere in ConfigureServices() and it's fine. That's a lot easier than relying on users to read your documentation that says "You must call Configure<WhatsAppSettings> before calling AddWhatsApp(). It's more usable for the user, and hopefully fewer issues raised on GitHub for you!
One of the first thoughts I had when discovering this method was "what if the end user uses PostConfigure<T>() too?" Well, in that situation, there's not a lot you can do about it. But also, that's fine - the idea here was to try and enforce certain constraints in normal circumstances. Fundamentally, if an application author wants to misuse your library they'll always find a way…
Post configuration options for named options
The PostConfigure<T>() extension method doesn't just support the "default" options instance, it also works with named instances (which I've discussed in previous posts). If you're familiar with named options and they're use then the PostConfigure methods won't hold any surprises - there's a "post" configuration version for most of the "standard" configuration methods and interfaces:
PostConfigure<T>(options) - Configure the default options instance T
PostConfigure<T>(name, options) - Configure the named options instance T with name name
PostConfigureAll<T>(options) - Configure all the options instances T (both the default and named instances)
IPostConfigureOptions<T> - This is the "post" version of the IConfigureNamedOptions<T> instance, which allows you to use injected services when configuring your options. There is no "post" version of the IConfigureOptions<T> interface.
Only the last point is worth watching out for, so I'll reiterate: there is no "post" version of the IConfigureOptions<T> interface. The IPostConfigureOptions<T> interface (shown below) uses named instances:
This means if you aren't using named options, and you just want to implement an interface that's equivalent to the IConfigureOptions<T> interface, you should look for the special Options.DefaultName value, which is string.Empty. So for example, imagine you have the following implementation of IConfigureOptions<T> which configures the default options instance:
If you want to create a "post" configuration version that only configures the default options, you should use:
publicclassConfigureMySettingsOptions:IPostConfigureOptions<MySettings>{privatereadonlyCalculatorService _calculator;publicConfigureMySettingsOptions(CalculatorService calculator){
_calculator = calculator;}publicvoidPostConfigure(string name,MySettings options){// Only run when name == string.Emptyif(name == Options.Options.DefaultName){
options.MyValue = _someService.DoComplexCalcaulation();}}}
You can add this post configuration class to your DI container using:
In this post I showed how you could use PostConfigure<T>() to configure strongly-typed options after all the standard Configure<T>() actions have run. This is useful as a library author, as it allows you to do things like configure default values only if the user hasn't configured options, or to enforce constraints. As an application user you generally shouldn't need to use PostConfigure<T>() as you can already control the order in which configuration occurs, based on the order you call methods in ConfigureServices().
In recent posts I've been discussing the Options pattern for strongly-typed settings configuration in some depth. One of the patterns that has come up several times is using IConfigureOptions<T> or IConfigureNamedOptions<T> when you need to use a service from DI to configure your Options. In this post I show a convenient way for registering your IConfigureOptions with the ASP.NET Core DI container using the ConfigureOptions() extension method.
tl;dr;ConfigureOptions<T> is a helper extension method that looks for all IConfigureOptions<>, and IPostConfigureOptions<> implemented by the type T, and registers them in the DI container for you, so you don't have to do it manually using AddTransient<,>.
Using services to configure strongly-typed options
Whenever you need to use a service that's registered with the DI container as part of your strongly-typed setting configuration, you need to use IConfigureOptions<T> or IConfigureNamedOptions<T>. By implementing these interfaces in a class, you can configure an options object T using any required services from the DI container.
For example, the following class implements IConfigureOptions<MySettings>. It is used to configure the default MySettings options instance, using the CalculatorService service obtained from the DI container.
Even though this class implements IConfigureNamedOptions<T>, you still have to register it in the DI container using the non-named interface, IConfigureOptions<MySettings>:
In my last post, I showed another interface IPostConfigureOptions<T> which can be used in a similar manner, but only runs its configuration actions after all other configure actions for an options type have been executed. This one also needs to be registered in the DI container:
Remember, there is no named-options-specific IPostConfigureOptions<T> - IPostConfigureOptions<T> is used to configure both default and named options.
Automatically registering the correct interfaces with ConfigureOptions()
Having to remember which version of the interface to use when registering your class in the DI container is a bit cumbersome. This is especially true if your configuration class implements multiple configuration interfaces! This class:
Luckily, there's a convenient extension method that can dramatically simplify the registration process, called ConfigureOptions(). With this method, your registrations slim down to the following:
Behind the scenes, ConfigureOptions<> finds all of the IConfigureOptions<> (including IConfigureNamedOptions<>) and IPostConfigureOptions<> interfaces implemented by the provided type, and registers them in the DI container:
publicstatic IServiceCollection ConfigureOptions<T>(thisIServiceCollection services){var configureType =typeof(T);
services.AddOptions();// Adds the infrastructure classes if not already addedvar serviceTypes =FindIConfigureOptions(configureType);// Finds all the IConfigureOptions and IPostConfigure optionsforeach(var serviceType in serviceTypes){
services.AddTransient(serviceType, configureType);// Adds each registration for you}return services;}
Even if your classes only implement one of the configuration interfaces, I suggest always using this extension method instead of manually registering them yourself. Sure, there will be the tiniest startup performance impact in doing so, as it uses reflection to do the registration. But the registration code is so much easier to read, and harder to get wrong, that I suspect it's probably worth it!
Summary
When you need to use DI services to configure your strongly-typed settings, you have to implement IConfigureOptions<>, IConfigureNamedOptions<>, or IPostConfigureOptions<>, and register your class appropriately in the DI container. The ConfigureOptions() extension method can take care of the registration for you, by reflecting over the type, finding the implemented interfaces, and registering them in the DI container with the appropriate service. If you find your registration code hard to grok it might be worth considering switching to ConfigureOptions() in your own apps.
In recent posts I've been discussing some of the lesser known features of the Options system in ASP.NET Core 2.x. In the first of these posts, I described how to use named options when you want to have multiple instances of a strongly-typed setting, each with a different name. If you're new to them, I recommend reading that post for an introduction to named options, when they make sense, and how to use them.
In this post I'm going to address a limitation with the named options approach seen previously. Namely,
the documented way to access named options is with the IOptionsSnaphshot<T> interface. Accessing named options in this way means they always have a Scoped lifecycle, and are re-bound to the underlying configuration with every request. In this post I introduce the IOptionsMonitor<T> interface, and show how you can use it to create Singleton named options.
Named options are always scoped with IOptionsSnapshot<>
So far, we've mainly looked at two different interfaces for accessing your strongly-typed settings: IOptions<T> and IOptionsSnapshot<T>.
For IOptions<T>:
Value property contains the default, strongly-typed settings object T.
Is a Singleton - cache's the T instance for the lifetime of the app.
Creates and populates the T instance the first time an IOptions<T> instance is requested and the Value property is accessed.
Whereas for IOptionsSnapshot<T>:
Value property contains the default, strongly-typed settings object T
Get(name) method is used to fetch named options for T.
Is Scoped - caches T instances for the lifetime of the request.
Creates and populates the default and named T instances the first time they're accessed each request.
To me, the IOptionsSnapshot<T> feels a little bit messy, as it differs from the basic IOptions<T> interface in two orthogonal ways:
It allows you to use named options.
It is Scoped, and responds to changes in the underlying IConfiguration object.
If you wish to have your strongly-typed settings objects automatically change when someone updates the appsettings.json file (for example) then IOptionsSnapshot<T> is definitely the interface for you.
However, if you just want to use named options and don't care about the "reloading" behaviour, then the fact that IOptionsSnapshot<T> is Scoped is actually detrimental. You can't inject Scoped dependencies into Singleton services, which means you can't easily use named options in Singleton services. Also, if you know that the underlying configuration files aren't going to change (or you don't want to respect those changes), then re-binding the configuration to a new T settings object every request is very wasteful. That's a lot of pointless reflection and garbage to be collected for no benefit.
So what if you want to use named options, but you want them to be Singletons, not Scoped? There's a few options available to you, some cleaner than others. I'll discuss three of those possibilities in this post.
1. Casting IOptions<T> to IOptionsSnapshot<T>
The IOptionsSnapshot<T> interface extends the IOptions<T> interface, adding support for named options with the Get(name) method:
publicinterfaceIOptionsSnapshot<out T>: IOptions<T>where T :class,new(){TGet(string name);}
With that in mind, the suggestion "cast IOptions<T> to IOptionsSnapshot<T>" doesn't seem to makes sense; we could safely cast an IOptionsSnapshot<T> instance to IOptions<T>, but not the other way around, surely?
publicstaticclassOptionsServiceCollectionExtensions{publicstaticIServiceCollectionAddOptions(thisIServiceCollection services){// Both IOptions<T> and IOptionsSnapshot<T> are implemented by OptionsManager<T>
services.TryAdd(ServiceDescriptor.Singleton(typeof(IOptions<>),typeof(OptionsManager<>)));
services.TryAdd(ServiceDescriptor.Scoped(typeof(IOptionsSnapshot<>),typeof(OptionsManager<>)));// I'll get to this one later
services.TryAdd(ServiceDescriptor.Singleton(typeof(IOptionsMonitor<>),typeof(OptionsMonitor<>)));// Other depedent services elidedreturn services;}}
This extension method is called by the framework in ASP.NET Core, so you rarely have to call it directly yourself.
Assuming you don't override this registration somehow (you really shouldn't!) then you can be pretty confident that any IOptions<T> instance is actually an OptionsManager<T> instance, and hence implements IOptionsSnapshot<T>. That means the following code is generally going to be safe:
publicclassMySingletonService{// Inject the singleton IOptions<T> instancepublicMySingletonService(IOptions<SlackApiSettings> options){// Cast to IOptionsSnapshot<T>. // Safe as options.GetType() = typeof(OptionsManager<SlackApiSettings>)var optionsSnapshot = options as IOptionsSnapshot<SlackApiSettings>;// Access Singleton named optionsvar namedOptions = optionsSnapshot.Get("MyName");}}
With this approach, we get Singleton named option with very little drama. We know the OptionsManager<T> instance injected into the service is a Singleton, so it's still a singleton after casting to IOptionsSnapshot<T>. The "MyName" named options are bound only once, the first time they're requested, and they're cached for the lifetime of the app. Another benefit is that we didn't have to mess with the DI registrations at all.
It doesn't feel very nice though, does it? It requires explicit knowledge of the underlying DI configuration, and is definitely not obvious. Instead of casting interfaces around, we could just use the OptionsManager<T> directly.
2. Using OptionsManager<T> directly
As you've already seen, OptionsManager<T> is the class that implements both IOptions<T> and IOptionsSnapshot<T>. We could just directly inject this class into our services, and access the implementation methods directly:
publicclassMySingletonService{publicMySingletonService(OptionsManager<SlackApiSettings> options){// No need to cast, as implements IOptionsSnapshot<T>var namedOptions = options.Get("MyName");var defaultOptions = options.Value;}}
Unfortunately, we also need to register OptionsManager<T> as a Singleton service in ConfigureServices():
Even though this approach avoids the dirty cast, it's not ideal. Your services now depend on a specific implementation instead of an interface, and we had to add an extra registration with DI.
publicclassMyScopedService{publicMyScopedService(
IOptions<SlackApiSettings> options,// Implemented by OptionsManager<SlackApiSettings>
IOptionsSnapshot<SlackApiSettings> optionsSnapshot,// Implemented by OptionsManager<SlackApiSettings>
OptionsManager<SlackApiSettings> optionsManager)// Is OptionsManager<SlackApiSettings>{
Assert.AreSame(options, optionsManager);//FALSE
Assert.AreSame(optionsSnapshot, optionsManager);//FALSE
Assert.AreSame(optionsSnapshot, options);//FALSE
Assert.AreSame(options.Value, optionsManager.Value);//FALSE
Assert.AreSame(optionsSnapshot.Value, optionsManager.Value);//FALSE
Assert.AreSame(optionsSnapshot.Value, options.Value);//FALSE}}
It's pretty unlikely that this will actually cause any issues in practice. Strongly-typed settings are typically (and arguably should be) dumb POCO objects that are treated as immutable once created. So even though they may not actually be singletons (the IOptions<T> instance has one copy, and the OptionsManager<T> instance has another), they will have the same values. Just don't go storing state in them!
So if we're not quite happy with OptionsManager<T>, what's left?
3. Using IOptionsSnapshot<T>'s cousin: IOptionsMonitor<T>
IOptionsMonitor<T> is a bit like IOptions<T> in some ways and IOptionsSnapshot<T> in others:
It's registered as a Singleton (like IOptions<T>)
It contains a CurrentValue property that gets the default strongly-typed settings object as a Singleton (like IOptions<T>.Value)
It has a Get(name) method for returning named options (like IOptionsSnapshot<T>). Unlike IOptionsSnapshot<T>, these named options are Singletons.
Responds to changes in the underlying IConfiguration object by re-binding options. Note this only happens when the configuration changes (not every request like IOptionsSnapshot<T> does).
IOptionsMonitor<T> is itself a Singleton, and it caches both the default and named options for the lifetime of the app. However, if the underlying IConfiguration that the options are bound to changes, IOptionsMonitor<T> will throw away the old values, and rebuild the strongly-typed settings. You can register to be informed about those changes with the OnChange(listener) method, but I won't go into that in this post.
Using named options in singleton services is now easy with IOptionsMonitor<T>:
IOptionsMonitor<T> has a lot of advantages in this case:
Registered as a singleton by default
Your services depend on an interface instead of a concrete implementation
No safe/unsafe casts required
The only thing to remember is that CurentValue (and the values from Get()) are just that, the current values. While they're the only instance at any one time, they will change if the underlying IConfiguration changes. If that's not a concern for you, then IOptionsMonitor<T> is probably the way to go.
This doesn't solve the issue of taking a dependency on the IOptions* interfaces in general. There are ways to avoid it when using IOptions<T>, but you're stuck with it if you're using named options.
Summary
Named options solve a specific use case - where you want to have multiple instance of a strongly-typed configuration object. You can access named options from the IOptionsSnapshot<T> interface. However, the strongly-typed settings object you get T will be recreated with every request, and can only be used in a Scoped context. Sometimes, for performance or convenience reasons, you might want to access named options from a Singleton service.
There are several ways to achieve this. You can:
Inject an IOptions<T> instance and cast it to IOptionsSnapshot<T>.
Register OptionsManager<T> as a Singleton in the DI container, and inject it directly.
Use IOptionsMonitor<T>. Be aware that if the underlying configuration changes, the singleton objects will change too.
Of these three options, I think IOptionsMonitor<T> provides the best solution, though it's important to be aware of the behaviour when the underlying IConfiguration object changes.
In this post I show how to install the experimental IntelliCode extension in Visual Studio, and how to use it to generate an EditorConfig file from your existing code.
Keeping a consistent style throughout a codebase is important for readability, but can be hard to achieve without some sort of automated tooling to help you.
Having said that, pretty much none of my projects have an .editorconfig file.
Why?
Every time I've tried to add one to an existing project, I get bogged down trying to decide what value I want to use for each of the rules. And there's a lot of them.
That's why I was very interested when James mentioned on Merge Conflict that there's an experimental Visual Studio extension that can generate this file for you!
Visual Studio IntelliCode
Visual Studio IntelliCode was announced some time ago, but it passed me by. According to their website:
Visual Studio IntelliCode is an experimental set of AI-assisted development capabilities for next-generation developer productivity.
That's a pretty bold claim, and there's a lot in the works, but right now it basically has two features:
Assisted IntelliSense - which tries to guess which item you're most likely to pick from the IntelliSense completion list, and puts it at the top. I'm pretty sure ReSharper has done this for years, but you know… AI…
Infer code style and formatting conventions - generate an .editorconfig file from the code in your solution. This is what I came for!
I decided to give the extension a go. I run Visual Studio in various places both with and without ReSharper, so I'll try out the enhanced IntelliSense in good time. In this post, I'll show how you can generate an .editorconfig file for your project.
Even if you don't normally use Visual Studio, it might be worth installing the extension, generating the .editorconfig file, and committing it to your source code repository. You can then go back to using your preferred IDE, but with the benefit of an auto-generated .editorconfig.
Installing the IntelliCode extension
You can install the extension from Visual Studio by choosing Tools > Extensions and Updates. Search in the Online section for IntelliCode and download it:
You'll have to close Visual Studio to complete the install. When you do, the VSIX installer window should pop up:
When you start up Visual Studio, you should see little stars next to your IntelliSense lists - that's the IntelliCode extension at work:
Now the extension is installed, you can generate an .editorconfig file.
Generating an .editorconfig file with IntelliCode
You can generate an .editorconfig file anywhere in your solution by right-clicking in Solution Explorer and choosing Add > New EditorConfig (IntelliCode):
IntelliCode will pause for a while while it analyses your solution, before presenting the generated .editorconfig. I tried it on one of my GitHub projects and it generated the file below:
# Rules in this file were initially inferred by Visual Studio IntelliCode from the NetEscapades.AspNetCore.SecurityHeaders codebase based on best match to current usage at 16/11/2018
# You can modify the rules from these initially generated values to suit your own policies
# You can learn more about editorconfig here: https://docs.microsoft.com/en-us/visualstudio/ide/editorconfig-code-style-settings-reference
[*.cs]
#Core editorconfig formatting - indentation
#use soft tabs (spaces) for indentation
indent_style= space
#Formatting - indentation options
#indent switch case contents.
csharp_indent_case_contents= true
#indent switch labels
csharp_indent_switch_labels= true
#Formatting - new line options
#require braces to be on a new line for types, object_collection, methods, control_blocks, and lambdas (also known as "Allman" style)
csharp_new_line_before_open_brace= types, object_collection, methods, control_blocks, lambdas
#Formatting - organize using options
#sort System.* using directives alphabetically, and place them before other usings
dotnet_sort_system_directives_first= true
...
#Style - qualification options
#prefer fields not to be prefaced with this. or Me. in Visual Basic
dotnet_style_qualification_for_field= false:suggestion
#prefer methods not to be prefaced with this. or Me. in Visual Basic
dotnet_style_qualification_for_method= false:suggestion
#prefer properties not to be prefaced with this. or Me. in Visual Basic
dotnet_style_qualification_for_property= false:suggestion
One of the really nice things about this file is the annotations describing what the fields do. Some of the names can be pretty obscure. Unfortunately if want to add any extra rules, you're left having to trawl through the documentation to find what you want.
To help tweak the .editorconfig I decided to install one more extension, the EditorConfig Language Service.
Installing the EditorConfig Language Service
The EditorConfig Language Service is a Visual Studio extension by the prolific Mads Kristensen. It puts your Visual Studio editor on steroids for .editorconfig files! Install the extension from Tools > Extensions and Updates, restart Visual Studio again, and you'll be good to go.
The key feature I was after is IntelliSense for .editorconfig. Now when you start typing you'll get the classic Visual Studio completion list, with all the options available, as well as a clear description of what it does.
It includes a bunch of other nice-to-haves like auto-formatting your code when you type Ctrl+K,D to line up all the = and :, e.g:
Overall, definitely worth installing, even if you only use it once!
I think I might try generating .editorconfig files for a bunch of my different projects, and see how they compare. Anything that takes the hassle out of having to create one manually, or making a million and one tiny decisions!
Summary
In this post I showed how to install the experimental IntelliCode extension in Visual Studio. This extension is able to automatically generate an EditorConfig file from your project's code, so that the rules reflect the styles you're already using. If it works for your code base, then this seems like a great way to set a baseline for an existing code base, that you can then migrate gradually towards a more consistent style.
In this post I describe how I improved the build performance of my ASP.NET Core Docker containers when building on a serverless host that doesn't provide any layer caching. I used a combination of multi-stage builds and caching from a remote repository to improve performance by avoiding repetitive work.
tl;dr; Use --target to build specific stages of your multi-stage builds, and push these images to a remote repository. In subsequent builds, pull these images and use as the build cache by using --cache-from. See below for a complete script.
Building applications in Docker
One of the big selling points of Docker containers for application hosting is their reliability and immutability. You can run an image on any host, and it will run the same (within reason), regardless of the underlying operating system. It's also incredibly useful for building applications.
Applications often require many more dependencies to build then they do to run. Take an ASP.NET Core application for example. To build it you need the .NET Core SDK, but depending on your application, you may also need various extra tools like Node.js for front-end building and minification, or Cake for writing your build scripts. In comparison, you only need the .NET Core runtime to run an ASP.NET Core application, or if you're building a standalone app, not even that!
Using Docker to build your applications allows you tame these dependencies, ensuring you don't end up with clashes between different applications. Without Docker you have to keep a careful eye on the version of Node used by all your applications and installed on your build server. Instead, you can happily upgrade an application's Docker image without affecting any other app on the build server.
In previous posts I've used an example of an optimised Dockerfile for building ASP.NET Core apps. I typically use Cake for building my apps, even in Docker, but for simplicity the example below uses raw dotnet commands:
# Builder imageFROM microsoft/dotnet:2.1.402-sdk AS builder
WORKDIR /sln
COPY ./*.sln ./NuGet.config /*.props /*.targets ./
# Copy the main source project filesCOPY src/*/*.csproj ./
RUN for file in $(ls *.csproj); do mkdir -p src/${file%.*}/ && mv $file src/${file%.*}/; done
# Copy the test project filesCOPY test/*/*.csproj ./
RUN for file in $(ls *.csproj); do mkdir -p test/${file%.*}/ && mv $file test/${file%.*}/; done
RUN dotnet restore
# Copy across the rest of the source filesCOPY ./test ./test
COPY ./src ./src
RUN dotnet build -c Release
RUN dotnet test "./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj" \
-c Release --no-build --no-restore
RUN dotnet publish "./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj" \
-c Release -o "../../dist"--no-restore
# App imageFROM microsoft/dotnet:2.1.3-aspnetcore-runtime-alpine
WORKDIR /app
ENTRYPOINT["dotnet","AspNetCoreInDocker.Web.dll"]COPY--from=builder /sln/dist .
This docker file has multiple optimisations:
It's a multi-stage build. The builder image uses the SDK image to build and publish the app. The final app output is copied into the tiny alpine-based runtime image.
Each dotnet command (restore, build, publish) is run individually, instead of letting dotnet publish run all the stages at once. This allows Docker to cache the output of each command if nothing has changed since it was last run. This is the layer caching.
We manually copy across the .csproj and .sln files and run dotnet restorebefore copying across the rest of the source code. That way if none of the .csproj files have changed since the last build, we can used the cached output of the dotnet restore layer.
In reality, I've found the dotnet restore layer caching is the most important. If anything meaningful has changed about your app (e.g. source code files or test files), then the layer cache for dotnet build will be invalid. This will generally also be true if you're embedding version numbers in your output dlls, especially if you're embedding a unique per-build version.
I've found that Dockerfiles like this (that rely on Docker's layer caching) work really well when you're building locally, or if you have a single build server you're using for your apps. Where it falls down is when you're building using a hosted platform, where build agents are ephemeral and provisioned on demand.
The upside of building Docker images on hosted agents
I experienced both the highs and lows of moving to a hosted build platform recently. I was tasked with moving an ASP.NET Core application from building on a self-hosted Jenkins agent to using AWS's CoreBuild platform. CodeBuild, like many other CI products, allows you to provision a build agent in response to demand, e.g. a PR request, or a push to master in your GitHub repo.
The process of migrating to CodeBuild had inevitable hurdles associated with migrating to any new service. But the process of building the ASP.NET Core application was fundamentally identical to building with Jenkins, as it was encapsulated in a Dockerfile. The actual build script was essentially nothing more than:
This bash script builds the Docker image based on the dockerfile AspNetCoreInDocker.Web.Dockerfile. It tags the output image with both a commit-specific version number $DOCKER_IMAGE_VERSION and the special latest tag. It then pushes the image to our private repository, and the build process is done!
Our actual build script does a lot more than this, but it's all that's relevant for this post.
The downside of building Docker images on hosted agents
While the build was working, one thing was bugging me about the solution. In using a hosted agent, we'd completely lost the advantages of layer caching that the Dockerfiles are designed to take advantage of. Every build used a new agent that had none of the layers cached from previous builds. The builds would still succeed (it's only a "cache" after all), they just took longer than they would have done if caching was available.
Unfortunately, CodeBuild doesn't have anything built-in to take advantage of this Docker feature. While you can cache files to an S3 bucket, that's not so useful here. You can use docker save and docker load to save an image to a tar file and rehydrate it later, but it didn't provide much time benefit in my case. The best solution in my case (based on the scripts in this issue), was to leverage two docker features I didn't previously know about: the --cache-from and --target arguments.
The --target argument
When you create a multi stage build, you can provide names for each stage. For example, in the Dockerfile I showed earlier, I used the name builder for the first stage:
# This stage is called 'builder'FROM microsoft/dotnet:2.1.402-sdk AS builder
# ...# This stage doesn't have a nameFROM microsoft/dotnet:2.1.3-aspnetcore-runtime-alpine
WORKDIR /app
ENTRYPOINT["dotnet","AspNetCoreInDocker.Web.dll"]# Copy files from the 'builder' stage
COPY--from=builder /sln/dist .
By providing a name for your stages you can reference them later in the Dockerfile. In the previous example I copy the contents of /sln/dist from the output of the builder stage to the final alpine runtime image.
What I didn't realise is that you can tell Docker to only build some of the stages by using the --target argument. For example, to only build the builder stage (and not the final runtime image stage) you could run
The output of this command would contain only the builder stage, not the runtime stage. Notice I've also tagged this stage using the :builder tag - I'll come back to this later when we put together the final script.
The --cache-from argument
By default, when you build Docker images, Docker uses it's build cache to check if it can skip any of the steps in your Dockerfile. On a hosted agent, that build cache will be empty, as a new host is spun up for every request. The --cache-from argument allows you to tell Docker to also consider a specific image as part of it's build cache. If the provided image and your current build have layers in common, you get the same speed up as if the image had been built on the same machine.
For example, imagine briefly that we're not using multi-stage builds, so the final image pushed to the remote repository contains all the build layers. Without using --cache-from our build script would always have to execute every command in the Dockerfile, as the build cache would be empty:
# As the build cache is empty, this docker build command has to execute every layer
docker build \
-t my-images/AspNetCoreInDocker.Web:latest \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."
Instead, we can use --cache-from in combination with an explicit docker pull:
# Pull the image from remote repository (|| true avoids errors if the image hasn't been pushed before)
docker pull my-images/AspNetCoreInDocker.Web:latest ||true# Use the pulled image as the build cache for the next build
docker build \
--cache-from my-images/AspNetCoreInDocker.Web:latest \
-t my-images/AspNetCoreInDocker.Web:latest \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."# Push the image to the repository. Subsequent builds can pull this and use it as the cache
docker push my-images/AspNetCoreInDocker.Web:latest
This simple approach works well if your final built image contains all your docker build layers, but if you're using multi-stage builds (and you should be!) then there's a problem. The final image that is pushed to (and pulled from) the remote repository is only the runtime stage.
That's fundamentally the point of multi-stage builds - we don't want our build layers in our runtime image. So how can we get round this? By using --target and --cache-from together!
Using --cache-from and --target with multi-stage builds
Currently we have a problem - we want to reuse the build layers of the builder stage in our multi-stage Dockerfile, but we don't push those layers to a repository, so we can't pull them in subsequent builds.
The solution is to explicitly build and tag the builder stage of the multi-stage Dockerfile, so we can push that to the remote repository for subsequent builds. We can then build the runtime stage of the Dockerfile and push that too.
DOCKER_IMAGE_VERSION=1.2.3_someversion
# Pull the latest builder image from remote repository
docker pull my-images/AspNetCoreInDocker.Web:builder ||true# Only build the 'builder' stage, using pulled image as cache
docker build \
--target builder \
--cache-from my-images/AspNetCoreInDocker.Web:builder \
-t my-images/AspNetCoreInDocker.Web:builder \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."# Pull the latest runtime image from remote repository# (This may or may not be worthwhile, depending on your exact image)
docker pull my-images/AspNetCoreInDocker.Web:latest ||true# Don't specify target (build whole Dockerfile)# Uses the just-built builder image and the pulled runtime image as cache
docker build \
--cache-from my-images/AspNetCoreInDocker.Web:builder \
--cache-from my-images/AspNetCoreInDocker.Web:latest \
-t my-images/AspNetCoreInDocker.Web:$DOCKER_IMAGE_VERSION \
-t my-images/AspNetCoreInDocker.Web:latest \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."# Push runtime images to remote repository
docker push my-images/AspNetCoreInDocker.Web:$DOCKER_IMAGE_VERSION
docker push my-images/AspNetCoreInDocker.Web:latest
# Push builder image to remote repository for next build
docker push my-images/AspNetCoreInDocker.Web:builder
With this approach, you keep your runtime images small by using multi-stage builds, but you also benefit from the build cache by building the builder stage separately.
Bonus: toggling between build approaches
As with many things, the exact speedup you see will depend on the particulars of your app and its Dockerfile. If you're doing a lot of setup at the start of your Dockerfile (installing tools etc) then you may well see a significant speed up. In my case, using --cache-from to cache the install of Cake and dotnet restore on a modest sized application shaved about 2 minutes off a 10 minute build time. At $0.005 per minute, that means my efforts saved the company a whopping 1¢ per build. Ooh yeah, time to crack out the champagne.
A 20% reduction in build time isn't to be sniffed at, but your mileage may vary. I wanted to be able to test my build with and without the explicit caching. Also, I wanted to be able to just use the standard build cache when building locally. Consequently, I created the following bash script, which either builds using the build-cache or uses --cache-from based on the presence of the variable USE_REMOTE_DOCKER_CACHE:
#!/bin/bash -eu
# If USE_REMOTE_DOCKER_CACHE is not set, set it to an empty variable
USE_REMOTE_DOCKER_CACHE="${USE_REMOTE_DOCKER_CACHE:-""}"
DOCKER_IMAGE_VERSION=1.2.3_someversion
if[[ -z "${USE_REMOTE_DOCKER_CACHE}"]];then# Use multi-stage build and buit-in layer caching
docker build \
-t my-images/AspNetCoreInDocker.Web:$DOCKER_IMAGE_VERSION \
-t my-images/AspNetCoreInDocker.Web:latest \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."else# Use the remote cache
docker pull my-images/AspNetCoreInDocker.Web:builder ||true
docker build \
--target builder \
--cache-from my-images/AspNetCoreInDocker.Web:builder \
-t my-images/AspNetCoreInDocker.Web:builder \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."
docker pull my-images/AspNetCoreInDocker.Web:latest ||true
docker build \
--cache-from my-images/AspNetCoreInDocker.Web:builder \
--cache-from my-images/AspNetCoreInDocker.Web:latest \
-t my-images/AspNetCoreInDocker.Web:$DOCKER_IMAGE_VERSION \
-t my-images/AspNetCoreInDocker.Web:latest \
-f "path/to/AspNetCoreInDocker.Web.Dockerfile" \
"."fi# Push runtime images to remote repository
docker push my-images/AspNetCoreInDocker.Web:$DOCKER_IMAGE_VERSION
docker push my-images/AspNetCoreInDocker.Web:latest
if[[ -z "${USE_REMOTE_DOCKER_CACHE}"]];thenecho'Skipping builder push as not using remote docker cache'else
docker push my-images/AspNetCoreInDocker.Web:builder
fi
Summary
Moving your CI build process to use a hosted provider makes a lot of sense compared to managing your own build agents, but you have to be aware of the trade-offs. One such trade-off for building Docker images is the loss of the build cache. In this post I showed how I worked around this problem by using --target and --cache-from with multi-stage builds to explicitly save builder image layers to a remote repository, and to retrieve them on the next build. Depending on your specific Dockerfile and how well it is designed for layer caching, this can give a significant performance boost compared to building the image from scratch on every build.
An important aspect of running ASP.NET Core apps in the cloud is how you secure the secrets your app requires, things like connection strings and API keys. In this post, I show one approach to securing your application when you're running in AWS - using AWS Secrets Manager to access the secrets at runtime.
In my next post, I'll show how to improve this process by filtering out which secrets are loaded by a given application.
Protecting secrets in ASP.NET Core apps
Secrets are configuration values that are in some way sensitive and should not be public. They include things like connection strings, API Keys, and certificates. As a rule of thumb, you should never write these values in appsettings.json files or in any file that is checked-in to a source control repository. Ideally, they should be stored outside your source control working directory.
For local development, User Secrets (also known as Secrets Manager, but I'll stick to User Secrets for this post) is the preferred way to store sensitive values. This tool manages storing configuration values outside the working directory of your project (in your user profile directory). This works well for local development, though it's important to be aware that User Secrets doesn't encrypt the secrets, it just moves them to a location you're less likely to accidentally expose.
User Secrets are added to your ASP.NET Core configuration by default if you're using the default builder WebHost:
publicstaticIWebHostBuilderCreateWebHostBuilder(string[] args)=>
WebHost.CreateDefaultBuilder(args)// Adds User Secrets to configuration.UseStartup<Startup>();
User Secrets are intended only for development-time storage of secrets, what about in a production environment?
The approach you take will depend a lot on the environment you're running in. Environment variables are often suggested as a good choice, though there are some downsides.
If you're injecting environment variables at runtime (for example, into a docker container), then you need a process to do the injecting. That typically falls on your CI/CD server, which means it (the CI/CD server) needs to have knowledge (or know how to retrieve) all the required secrets for every application.
Alternatively, you could "bake" the the secrets into your docker images themselves, so that when they're run they have all the required secrets available. That's generally a bad idea as anyone can inspect the Docker image and retrieve the secrets directly (assuming they're not previously encrypted in some way).
A better approach, and the approach generally advocated by Microsoft, is to store your secrets in a dedicated "Secrets Vault" such as Azure Key Vault. At runtime, your app requests access to Secrets from the Azure Key Vault service.
One practicality to be aware of - accessing Azure Key Vault requires a "Client Secret" to call the Azure Key Vault API. That leaves you with a chicken-and-egg problem. You store your secrets securely, but you can't access them without an API key, so how do you store that API key securely? If your app is running in Azure, I think Managed Service Identity can solve this problem, but I haven't used it myself so I'm not sure.
AWS Secrets Manager serves an essentially identical role as Azure Key Vault. It securely stores your secrets until you retrieve them at runtime. If your going to be running your ASP.NET Core app in AWS, then AWS Secrets Manager is a great option, as it allows you to finely control the permissions associated with the AWS IAM roles running your apps. It also handles the chicken and egg problem if you're running inside AWS: if the AWS role used to run your app has access to AWS Secrets Manager, you don't have to worry about storing extra API/Access keys; you control access at the AWS role/policy level instead of using API keys.
Adding a secret to AWS Secrets Manager
As with most AWS features, there are several ways to add a secret to AWS Secrets Manager. I'll show how to do so via the CLI tool and the AWS Console.
Note: To generate secrets, you'll need to have the secretsmanager:CreateSecret permission granted for your user/role in IAM
AWS Secrets Manager has a lot of different features, that I'm not going to touch on in this post. You can store database credentials, key-value pairs, plaintext strings, encrypt with custom AWS KMS keys, and rotate database credentials automatically. I'm going to store a simple plain text string (the secret value) and use the name of the secret as the key.
The secret I'm going to store is a connection string, and I want to store it so that the final key added to the ASP.NET Core configuration is ConnectionStrings:MyTestApp i.e. it's the MyTestApp key, in the ConnectionStrings section. If we were storing the secret directly in JSON, it would look something like this:
For legacy reasons, I'm actually going to store the : in the secret name as __, and replace it inside the app when the secret is loaded. This is consistent with the behaviour for environment variables in ASP.NET Core, and I think it's a nice convention to preserve. So the secret name stored in AWS will be ConnectionStrings__MyTestApp.
An important point to note is that you'll need to configure the AWS IAM role used to run your ASP.NET Core application with the necessary permissions to List and Fetch stored secrets, plus to decrypt secrets with KMS. An example IAM Policy snippet might look something like the following (but be sure to check for your own environment - this allows the role to read any secret in Secrets Manager)
aws secretsmanager create-secret \
--name ConnectionStrings__MyTestApp \
--description "The connection string for my test app" \
--secret-string "Server=127.0.0.1;Port=5432;Database=myDataBase;User Id=myUsername;Password=myPassword;"
Alternatively, you could use the contents of a file as the secret value. This avoids printing the secret to the console:
aws secretsmanager create-secret \
--name ConnectionStrings__MyTestApp \
--description "The connection string for my test app" \
--secret-string file://connectionstring.txt
Both of these options will use the default KMS encryption key to store the secret, and won't configure rotation.
Adding a secret using the AWS Console
Does it bug anyone else that AWS calls their web UI the Console? Console always makes me think of command line!
If CLIs aren't your thing, you can create a new secret using the AWS Console. Navigate to Secrets Manager for your desired region, and click "Store a New Secret".
This will take you to the "Store a new Secret" wizard. The first step is to choose the type of secret, and set its value. We'll be using the "Other type of secret" and will store the plaintext value. We'll leave the encryption as the default for now.
Click Next, and on the next page enter the name ConnectionStrings__MyTestApp and a description for the secret.
Click Next to view the rotation option. We'll leave rotation disabled. Click Next again and you're presented with a review of your secret, and sample code for accessing it. Don't worry about this - we'll be using the AWS .NET SDK to abstract away all this complexity. Finally, click Store to store your secret in AWS Secrets Manager.
After storing the secret, you can view the details of the secret from the Secrets Manager home page, and manually retrieve the secret value if necessary.
Loading secrets from AWS Secrets Manager with ASP.NET Core
Now we've got a secret stored, it's on to the interesting part - loading it in our ASP.NET Core application. To do this I used a little NuGet package called Kralizek.Extensions.Configuration.AWSSecretsManager. The library is open source on GitHub - it doesn't have many stars, but its actual code foot print is very small, and it does everything I need so I recommend it.
<ProjectSdk="Microsoft.NET.Sdk"><PropertyGroup><TargetFrameworks>netcoreapp2.1</TargetFrameworks></PropertyGroup><ItemGroup><PackageReferenceInclude="Microsoft.AspNetCore.App"/><!-- Add the package--><PackageReferenceInclude="Kralizek.Extensions.Configuration.AWSSecretsManager"Version="1.0.0"/></ItemGroup></Project>
The README for the library includes great instructions for how to add configuration using AWS Secrets Manager to your application. The simplest use case is to add the AWS Secrets to the standard CreateDefaultBuilder call in Program.cs by using ConfigureAppConfiguration():
publicclassProgram{publicstaticvoidMain(string[] args)=>BuildWebHost(args).Run();publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).ConfigureAppConfiguration((hostingContext, config)=>{// Load AWS Secrets after all other configuration steps
config.AddSecretsManager();}).UseStartup<Startup>().Build();}
This adds AWS Secrets loading after all other configuration sources (e.g. appsettings.json, environment variables, command line arguments). It also assumes that AWS credentials are available by default to your application, using the usual AWS SDK mechanisms. If you're running your app inside AWS, then this will likely work out of the box. If not, there are other ways to obtain the necessary credentials, but I won't go into those here, as they circle back to the chicken and egg issue!
This is almost all we need for our application, but there's a couple of tweaks I want to make.
Don't add AWS secrets when developing locally
First, I don't want to use AWS SecretsManager when developing applications locally - .NET User Secrets are a better solution for that problem. It's possible that _my_ connection string for a local development database will be different to someone else's connection string when they're working locally on the app. AWS Secrets Manager configuration would be shared across all users, and would overwrite any local values we'd set. On top of that, it means I don't have to have AWS credentials configured for my local environment to run the application.
Ignoring the AWS Secrets Manager when developing locally is easy to achieve by using Hosting Environments. We can conditionally check if we're in the Development environment and only call AddSecretsManager() if it's appropriate:
publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).ConfigureAppConfiguration((hostingContext, config)=>{if(!hostingContext.HostingEnvironment.IsDevelopment()){// Don't add AWS secrets in local environment
config.AddSecretsManager();}}).UseStartup<Startup>().Build();}
Customising the generated key
There's one more piece of configuration to add. When I created the AWS secret, I said that I would store the secret using the __ token to separate configuration sections. The .NET Core configuration system requires you use : to separate sections, so we need to change the secret name when it's loaded. Luckily, Kralizek.Extensions.Configuration.AWSSecretsManager provides an options object to do just that.
Our key generation function isn't complicated, we are just replacing instances of "__" with ":":
Note that you have access to the whole SecretListEntry object here, so you can do more complex transformations if necessary. This object includes all the metadata about the secret (LastChangedDate and Tags for example), but not the value itself.
Add the GenerateKey call to the AwsSecretsManager() call by configuring the SecretsManagerConfigurationProviderOptions object. As the GenerateKey is so simple, I've inlined it here:
publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).ConfigureAppConfiguration((hostingContext, config)=>{if(!hostingContext.HostingEnvironment.IsDevelopment()){
config.AddSecretsManager(configurator: ops =>{// Replace __ tokens in the configuration key name
opts.KeyGenerator =(secret, name)=> name.Replace("__",":");});}}).UseStartup<Startup>().Build();
And that's it - you now have secrets being stored securely in Secrets Manager, and loaded at runtime based on the AWS IAM role your app is running under! This is great for getting started, but you'll generally want a more sophisticated setup than this provides, especially if you're storing secrets for multiple apps or for multiple environments. In the next post I'll show how you can achieve that with just a few tweaks to this basic configuration.
Summary
In this post I showed how to create a secret in AWS Secrets Manager using the AWS CLI or the web Console. I showed how to configure an ASP.NET Core application to load the secrets at runtime using the Kralizek.Extensions.Configuration.AWSSecretsManager NuGet package. One big advantage to using AWS Secrets Manager if you're already running in AWS is that you don't need to configure additional API keys. That avoids the "chicken and egg" problem you can run into if trying to access secure resources from outside the ecosystem.
In my last post, I showed how to add secrets to AWS Secrets Manager, and how you could configure your ASP.NET Core application to load them into the .NET Core configuration system at runtime. In this post, I take the process a little further. Instead of loading all secrets into the app, we'll only load those secrets which have a required prefix. This will allows us to have different secrets for different environments and for different apps.
A quick recap on loading secrets from AWS Secrets Manager.
I'm not going to cover the background of why we need secure secrets management, or how to add secrets to AWS Secrets Manager - check out my previous post for those details. At the end of my previous post, I showed how to add the Kralizek.Extensions.Configuration.AWSSecretsManager NuGet package to your app, and how to call AddSecretsManager() in Program.cs. I also showed how to conditionally load the package depending on the hosting environment, and how to replace "__" tokens in the secret name with ":".
This was the code we ended up with:
publicclassProgram{publicstaticvoidMain(string[] args)=>BuildWebHost(args).Run();publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).ConfigureAppConfiguration((hostingContext, config)=>{// Don't add AWS secrets when running locallyif(!hostingContext.HostingEnvironment.IsDevelopment()){
config.AddSecretsManager(configurator: ops =>{// Replace __ tokens in the configuration key name
opts.KeyGenerator =(secret, name)=> name.Replace("__",":");});}}).UseStartup<Startup>().Build();}
This worked well for my example, but it falls down a bit in practical usage. There's two main issues here:
All apps share the same secrets. We load all secrets we have access to and add them all to the IConfiguration object. That means currently all apps need to have the same IConfiguration/appsettings.json schema, and use the same values.
We have no way of differentiating configuration specific to different environments such as testing/staging/production. We would need to have separate sections for each environment, which would quickly get messy and is not recommended. The idiomatic approach in ASP.NET Core is for every hosting environments to have the same configuration schema, but different values. This is easily achieved with configuration layering, but is not possible with our current setup.
The solution to both of these problems in our case, is to add a "prefix" to the secret name stored in AWS. We can use that prefix to filter the secrets we load both by environment and by application.
Note - It you're using Azure Key Vault, the guidance is to not use this approach. Instead, create a separate Key Vault for each app and each environment. Unfortunately, AWS Secrets Manager is currently "global" to an account (and region) so we can't use that approach.
Filtering the secrets loaded from AWS
Before I dive into the solution, I'll take a brief detour to describe how the Kralizek.Extensions.Configuration.AWSSecretsManager package loads your secrets from AWS. When you call AddSecretsManager(), you add a SecretsManagerConfigurationProvider to the list of IConfigurationProviders for your app. This doesn't immediately load the secrets from AWS, it just registers the provider with the IConfigurationBuilder.
When you call IConfigurationBuilder.Build() (or it's called implicitly as part of the standard ASP.NET Core bootstrapping), the provider calls LoadAsync(). An (abbreviated) annotated version of which is shown below:
publicclassSecretsManagerConfigurationProvider:ConfigurationProvider{publicSecretsManagerConfigurationProviderOptions Options {get;}asyncTaskLoadAsync(){// Fetch ALL secrets from AWS Secrets Manager// This does not include the secret valuevar allSecrets =awaitFetchAllSecretsAsync().ConfigureAwait(false);foreach(var secret in allSecrets){// If we should not load the secret, skip itif(!Options.SecretFilter(secret))continue;// Fetch the secret value from AWSvar secretValue =await Client.GetSecretValueAsync(newGetSecretValueRequest{ SecretId = secret.ARN }).ConfigureAwait(false);// generate the keyvar key = Options.KeyGenerator(secret, secret.Name);// Save the value in the `IConfiguration` objectSet(key, secretValue);}}}
It's important to realise that we list all the secrets available first, so you need to ensure your AWS IAM role has permission to List all secrets, as well as Fetch specific values.
In order to solve our environment/app clashing problems we can build an appropriate predicate to filter our secrets by environment and application name. We'll also need to update the Key Generator, as you'll see later.
Deciding how to filter secrets
From the previous code, you can see the SecretFilter() predicate takes a single SecretListEntry object, and returns true if we should load the secret. That gives you a lot of different options for filtering your secrets.
For example, you could provide a hard list of ARNs that should be loaded, ensuring a very strict list of secrets to load. (ARNs are the unique resource identifiers in AWS, something like arn:aws:secretsmanager:eu-west-1:30123456:secret:ConnectionStrings__MyTestApp-abc123). Alternatively, you could add Tags to your secrets.
Specifying the exact secret name seemed attractive initially for keeping the secrets as locked down as possible. But having to maintain a specific list of ARNs for every environment in each app seemed like too much of a maintenance burden.
Instead I decided to go with a consistent naming convention for secrets based on the environment and a concept of variable "groups", inspired by Octopus Deploy's Variable Sets.
So for example, the connection string for MyTestApp in the Staging environment might have the following key name:
Staging/MyTestApp/ConnectionStrings__MyTestApp
This lets us do two things:
Filter secrets based on the hosting environment
Filter secrets based on the "secret groups" an app needs.
A given app will probably not have access to many different groups. Each app would have it's own group, for secrets specific to that app. It might also require access to one or more "shared" groups that contain global settings. That means you don't have to duplicate the same API Keys into app-specific secret groups, for example. The app can instead depend on the shared "Segment", "Twilio", or "Cloudflare" keys as necessary.
Partially building configuration to access stored values
By adding the flexibility to load multiple different secrets groups, we've somewhat inadvertently added some configuration to our app that we need in order to load the secrets. Another chicken and egg problem! Luckily this configuration isn't sensitive so we can store the configuration in appsettings.json.
Whenever possible I like to use strongly typed configuration, so we'll create a simple POCO for this configuration:
publicclassAwsSecretsManagerSettings{/// <summary>/// The allowed secret groups, e.g. Shared or MyAppsSecrets/// </summary>public ICollection<string> SecretGroups {get;}=newList<string>();}
Now we can add our configuration to appsettings.json:
Ordinarily, you would bind this configuration to the AwsSecretsManagerSettings object by using the Options pattern, calling Configure<T> in Startup.ConfigureServices(). Unfortunately that's not going to work in this case.
We need to access the configuration values before we start doing dependency injection, and before the Startup class is instantiated. The only way to make that work is to partially build the IConfiguration object for the app, and to manually bind our settings to it.
The code for this would look something like the following:
publicclassProgram{publicstaticvoidMain(string[] args)=>BuildWebHost(args).Run();publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).ConfigureAppConfiguration((hostingContext, configBuilder)=>{// Partially build the IConfigurationBuilder. It won't contain// out AWS secrets, but that's ok, we're going to throw it away soonIConfiguration partialConfig = configBuilder.Build();// Create a new instance of the settings object, and bind our configuration to itvar settings =newAwsSecretsManagerSettings();
partialConfig
.GetSection(nameof(AwsSecretsManagerSettings)).Bind(settings);// Build the list of allowed prefixes var env = hostingContext.HostingEnvironment.EnvironmentName;var allowedPrefixes = settings.SecretGroups
.Select(grp => $"{hostingContext.Host}/{grp}/");// TODO: Use allowedPrefixes and add AWS secrets// configBuilder.AddSecretsManager();}).UseStartup<Startup>().Build();}
This allows us to access the partial configuration we need to populate our AwsSecretsManagerSettings object and generate the list of secret prefixes to load from AWS. All that's left is to use those prefixes to set the SecretFilter() predicate, and add the SecretsManagerConfigurationProvider to the configuration builder.
Note that the framework will call IConfigurationBuilder.Build() a second time, when building the final IConfiguration object. By that point, we will have added the SecretsManagerConfigurationProvider by calling AddSecretsManager(), so the configuration will contain our AWS secrets.
Creating the filter methods
The filter methods themselves are pretty basic. First the SecretsManagerConfigurationProvider loads the list of available secrets. For each one, it calls the SecretFilter() predicate to decide whether to load the secret's value. Given our list of allowedPrefixes, we can write a predicate that looks something like this:
ICollection<string> allowedPrefixes;// Loaded from configuration
builder.AddSecretsManager(configurator: opts =>{// For a given entry, if it's name starts with any of the allowed prefixes// then load the secret
opts.SecretFilter = entry => allowedPrefixes.Any(prefix => entry.Name.StartsWith(prefix));
opts.KeyGenerator =// TODO: });
Once the provider has established that it should load a secret's value (because SecretFilter() returned true), and has called AWS to fetch the secret, it then calls our KeyGenerator function. In my last post, this was a simple string.Replace() to swap the "__" tokens for ":". With our "prefix" approach, we need to strip the prefix off first:
ICollectionstring allowedPrefixes;// Loaded from configuration
builder.AddSecretsManager(configurator: opts =>{
opts.SecretFilter = entry => allowedPrefixes.Any(prefix => entry.Name.StartsWith(prefix));
opts.KeyGenerator = entry =>{// We know one of the prefixes matches, this assumes there's only one match,// So don't use '/' in your environment or secretgroup names!var prefix = allowedPrefixes.First(text.StartsWith);// Strip the prefix, and replace "__" with ":"return secretValue
.Substring(prefix.Length).Replace("__",":");}});
We're almost there now, we just need to put all the pieces together.
Putting it all together and extracting into an extension method
We're starting to put quite a lot of code together here, most of which is boilerplate plumbing. In these situations I like to extract the code into an extension method instead of bloating the program.cs file. The code below is the same as shown throughout this post, just extracted into extension methods, and using static functions instead of anonymous delegates. For convenience I've actually created two extension methods:
An extension method on IConfigurationBuilder to add the AWS Secrets using the allowed prefixes
An extension method on IWebHostBuilder which skips AWS secrets in Development environments
publicstaticclassAwsSecretsConfigurationBuilderExtensions{publicstaticIWebHostBuilderAddAwsSecrets(thisIWebHostBuilder hostBuilder){return hostBuilder.ConfigureAppConfiguration((hostingContext, configBuilder)=>{// Don't add AWS secrets when running in developif(!hostingContext.HostingEnvironment.IsDevelopment()){// Call our extension method
configBuilder.AddAwsSecrets();}})}publicstaticIConfigurationBuilderAddAwsSecrets(thisIConfigurationBuilder configurationBuilder){IConfiguration partialConfig = configBuilder.Build();var settings =newAwsSecretsManagerSettings();
partialConfig
.GetSection(nameof(AwsSecretsManagerSettings)).Bind(settings);var env = hostingContext.HostingEnvironment.EnvironmentName;var allowedPrefixes = settings.SecretGroups
.Select(grp => $"{hostingContext.Host}/{grp}/");
builder.AddSecretsManager(configurator: opts =>{
opts.SecretFilter = entry =>HasPrefix(allowedPrefixes, entry);
opts.KeyGenerator =(entry, key)=>GenerateKey(allowedPrefixes, key);});}// Only load entries that start with any of the allowed prefixesprivatestaticboolHasPrefix(List<string> allowedPrefixes,SecretListEntry entry){return allowedPrefixes.Any(prefix => entry.Name.StartsWith(prefix));}// Strip the prefix and replace '__' with ':'privatestaticstringGenerateKey(IEnumerable<string> prefixes,string secretValue){// We know one of the prefixes matches, this assumes there's only one match,// So don't use '/' in your environment or secretgroup names!var prefix = prefixes.First(secretValue.StartsWith);// Strip the prefix, and replace "__" with ":"return secretValue
.Substring(prefix.Length).Replace("__",":");}}
That leaves our program.cs file nice and clean:
publicclassProgram{publicstaticvoidMain(string[] args)=>BuildWebHost(args).Run();publicstaticIWebHostBuildWebHost(string[] args)=>
WebHost.CreateDefaultBuilder(args).AddAwsSecrets()// Add the AWS secrets to the configuration (if we're not in Dev).UseStartup<Startup>().Build();}
We now have secure storage of secrets in AWS, loaded dynamically at runtime into an ASP.NET Core app.
Final thoughts
It's important to be aware of the limitations of any approach. If you're running your ASP.NET Core app in AWS then you'll be running under an IAM role which will have a range of security policies attached to it. In order to fetch a secret from AWS Secrets Manager, the role must have permission to fetch the secret. That means you can lock down access to secrets on a per-role basis. However, it also means that if your apps are all running with the same IAM role, then any app will be able to access the secrets from any other app. That's worth thinking about if you're running your applications on a single web server, or aren't using separate roles for each pod in Kubernetes for example.
Another point to consider with this design is that every AWS secret corresponds to a single configuration value. If you have a lot of configuration values, that could mean a lot of secrets stored in AWS, and more secrets to manage. The alternative would be to store all the secrets for a given secret group as a JSON object. That would significantly decrease the number of secrets stored in Secret Manager. It would also secure the actual configuration keys that are stored for each group.
I'm not sure if that's a good or bad thing to be honest - the approach I've described is working for me currently, so I'm inclined to leave it as it is. The good news is that if I change my mind later and start storing multiple values per secret, the Kralizek.Extensions.Configuration.AWSSecretsManager library supports JSON secrets out of the box, so a switch wouldn't mean any changes to my code. It will gracefully deconstruct a JSON payload into separate configuration values per string. See the source code if you're interested how this works.
Summary
In my previous post I showed how to use AWS Secrets Manager to securely store secrets, and how to use the Kralizek.Extensions.Configuration.AWSSecretsManager package to load them at runtime in ASP.NET Core apps. The solution shown in that post had two problems - you couldn't use different secrets for different environments, and secret keys were global across all of your apps. In this post I showed how to use a standard naming prefix and introduced the concept of secrets-groups to work around these issuses.