This post builds on my previous posts on building ASP.NET Core apps in Docker and using Cake in Docker. In this post I show how you can optimise your Dockerfiles for dotnet restore, without having to manually specify all your app's .csproj files in the Dockerfile.
Background - optimising your Dockerfile for dotnet restore
When building ASP.NET Core apps using Docker, there are many best-practices to consider. One of the most important aspects is using the correct base image - in particular, a base image containing the .NET SDK to build your app, and a base image containing only the .NET runtime to run your app in production.
In addition, there are a number of best practices which apply to Docker and the way it caches layers to build your app. I discussed this process in a previous post on building ASP.NET Core apps using Cake in Docker, so if that's new to you, i suggest checking it out.
A common way to take advantage of the build cache when building your ASP.NET Core in, is to copy across only the .csproj, .sln and nuget.config files for your app before doing a restore, rather than the entire source code for your app. The NuGet package restore can be one of the slowest parts of the build, and it only depends on these files. By copying them first, Docker can cache the result of the restore, so it doesn't need to run twice, if all you do is change a .cs file.
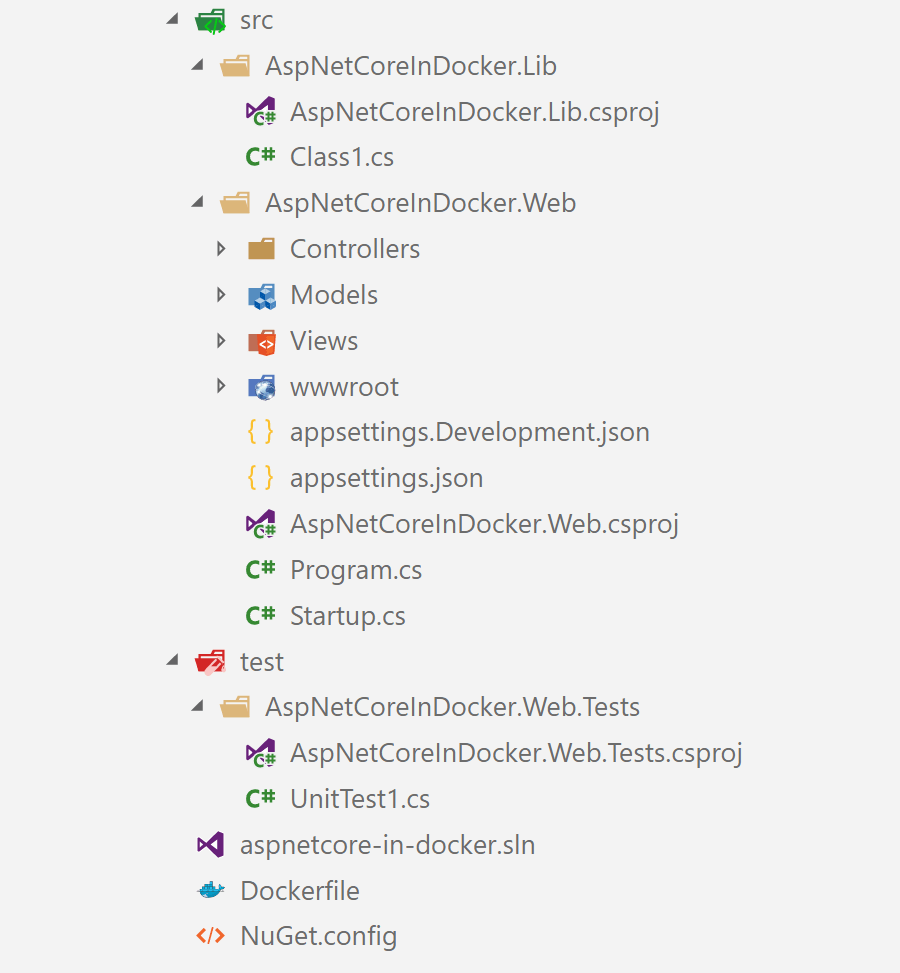
For example, in a previous post I used the following Docker file for building an ASP.NET Core app with three projects - a class library, an ASP.NET Core app, and a test project:
# Build image
FROM microsoft/dotnet:2.0.3-sdk AS builder
WORKDIR /sln
COPY ./aspnetcore-in-docker.sln ./NuGet.config ./
# Copy all the csproj files and restore to cache the layer for faster builds
# The dotnet_build.sh script does this anyway, so superfluous, but docker can
# cache the intermediate images so _much_ faster
COPY ./src/AspNetCoreInDocker.Lib/AspNetCoreInDocker.Lib.csproj ./src/AspNetCoreInDocker.Lib/AspNetCoreInDocker.Lib.csproj
COPY ./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj ./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj
COPY ./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj ./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj
RUN dotnet restore
COPY ./test ./test
COPY ./src ./src
RUN dotnet build -c Release --no-restore
RUN dotnet test "./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj" -c Release --no-build --no-restore
RUN dotnet publish "./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj" -c Release -o "../../dist" --no-restore
#App image
FROM microsoft/aspnetcore:2.0.3
WORKDIR /app
ENV ASPNETCORE_ENVIRONMENT Local
ENTRYPOINT ["dotnet", "AspNetCoreInDocker.Web.dll"]
COPY --from=builder /sln/dist .
As you can see, the first things we do are copy the .sln file and nuget.config files, followed by all the .csproj files. We can then run dotnet restore, before we copy the /src and /test folders.
While this is great for optimising the dotnet restore point, it has a couple of minor downsides:
- You have to manually reference every .csproj (and .sln) file in the Dockerfile
- You create a new layer for every
COPYcommand. (This is a very minor issue, as the layers don't take up much space, but it's a bit annoying)
The ideal solution
My first thought for optimising this process was to simply use wildcards to copy all the .csproj files at once. This would solve both of the issues outlined above. I'd hoped that all it would take would be the following:
# Copy all csproj files (WARNING, this doesn't work!)
COPY ./**/*.csproj ./
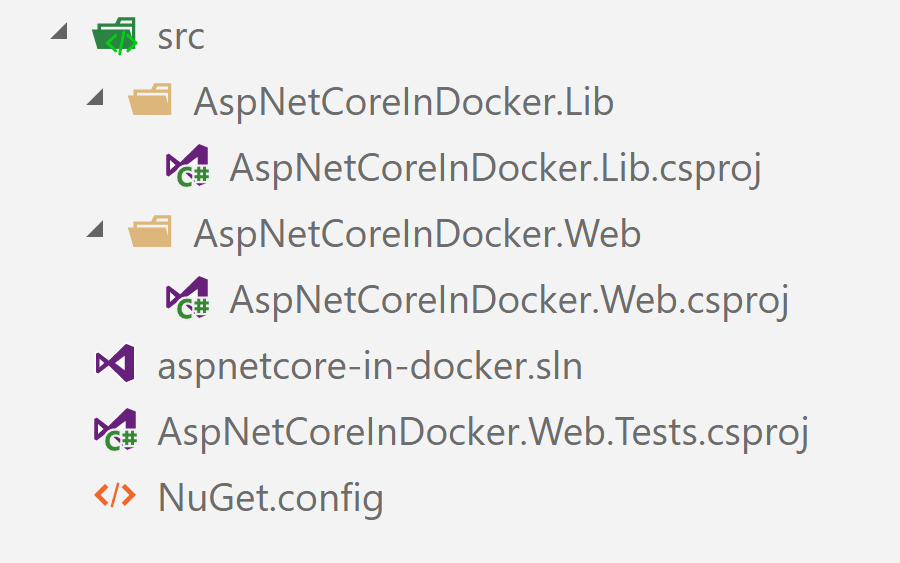
Unfortunately, while COPY does support wildcard expansion, the above snippet doesn't do what you'd like it to. Instead of copying each of the .csproj files into their respective folders in the Docker image, they're dumped into the root folder instead!
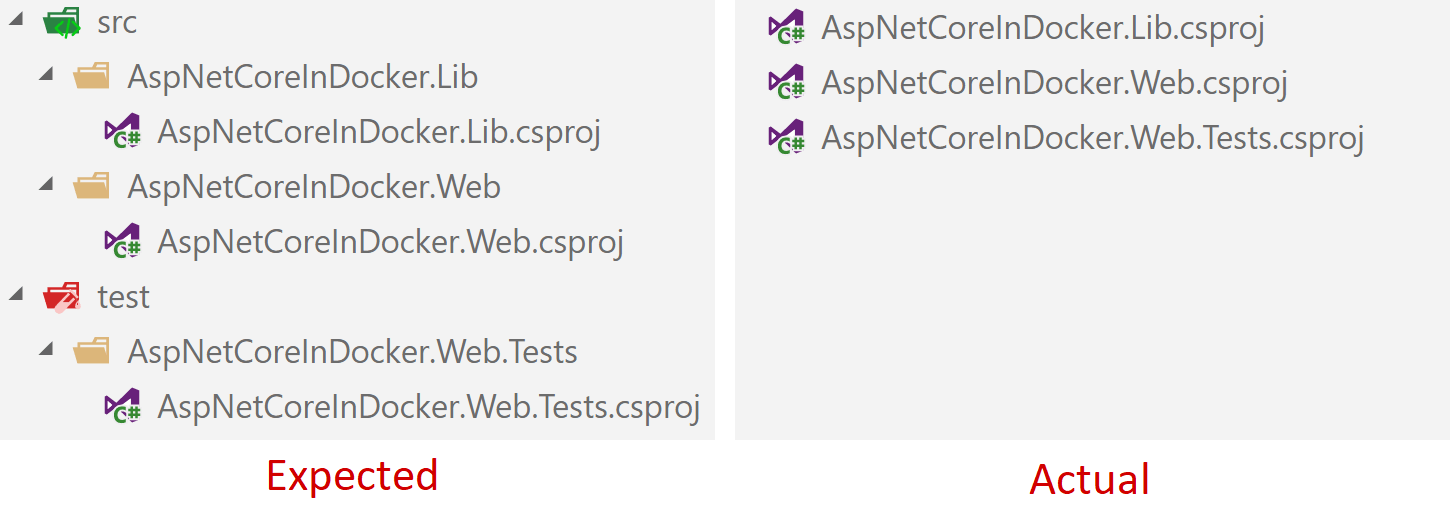
The problem is that the wildcard expansion happens before the files are copied, rather than by the COPY file itself. Consequently, you're effectively running:
# Copy all csproj files (WARNING, this doesn't work!)
# COPY ./**/*.csproj ./
COPY ./src/AspNetCoreInDocker.Lib/AspNetCoreInDocker.Lib.csproj ./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj ./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj ./
i.e. copy the three .csproj files into the root folder. It sucks that this doesn't work, but you can read more in the issue on GitHub, including how there's no plans to fix it 🙁
The solution - tarball up the csproj
The solution I'm using to the problem is a bit hacky, and has some caveats, but it's the only one I could find that works. It goes like this:
- Create a tarball of the .csproj files before calling
docker build. - In the Dockerfile, expand the tarball into the root directory
- Run
dotnet restore - After the docker file is built, delete the tarball
Essentially, we're using other tools for bundling up the .csproj files, rather than trying to use the capabilities of the Dockerfile format. The big disadvantage with this approach is that it makes running the build a bit more complicated. You'll likely want to use a build script file, rather than simplu calling docker build .. Similarly, this means you won't be able to use the automated builds feature of DockerHub.
For me, those are easy tradeoffs, as I typically use a build script anyway. The solution in this post just adds a few more lines to it.
1. Create a tarball of your project files
If you're not familiar with Linux, a tarball is simply a way of packaging up multiple files into a single file, just like a .zip file. You can package and unpackage files using the tar command, which has a daunting array of options.
There's a plethora of different ways we could add all our .csproj files to a .tar file, but the following is what I used. I'm not a Linux guy, so any improvements would be greatly received 🙂
find . -name "*.csproj" -print0 \
| tar -cvf projectfiles.tar --null -T -
Note: Don't use the
-zparameter here to GZIP the file. Including it causes Docker to never cache theCOPYcommand (shown below) which completely negates all the benefits of copying across the .csproj files first!
This actually uses the find command to iterate through sub directories, list out all the .csproj files, and pipe them to the tar command. The tar command writes them all to a file called projectfiles.tar in the root directory.
2. Expand the tarball in the Dockerfile and call dotnet run
When we call docker build . from our build script, the projectfiles.tar file will be available to copy in our Dockerfile. Instead of having to individually copy across every .csproj file, we can copy across just our .tar file, and the expand it in the root directory.
The first part of our Dockerfile then becomes:
FROM microsoft/aspnetcore-build:2.0.3 AS builder
WORKDIR /sln
COPY ./aspnetcore-in-docker.sln ./NuGet.config ./
COPY projectfiles.tar .
RUN tar -xvf projectfiles.tar
RUN dotnet restore
# The rest of the build process
Now, it doesn't matter how many new projects we add or delete, we won't need to touch the Dockerfile
3. Delete the old projectfiles.tar
The final step is to delete the old projectfiles.tar after the build has finished. This is sort of optional - if the file already exists the next time you run your build script, tar will just overwrite the existing file.
If you want to delete the file, you can use
rm projectfiles.tar
at the end of your build script. Either way, it's best to add projectfiles.tar as an ignored file in your .gitignore file, to avoid accidentally committing it to source control.
Further optimisation - tar all the things!
We've come this far, why not go a step further! As we're already taking the hit of using tar to create and extract an archive, we may as well package everything we need to run dotnet restore i.e. the .sln and _NuGet.config files!. That lets us do a couple more optimisations in the Docker file.
All we need to change, is to add "OR" clauses to the find command of our build script (urgh, so ugly):
find . \( -name "*.csproj" -o -name "*.sln" -o -name "NuGet.config" \) -print0 \
| tar -cvf projectfiles.tar --null -T -
and then we can remove the COPY ./aspnetcore-in-docker.sln ./NuGet.config ./ line from our Dockerfile.
The very last optimisation I want to make is to combine the layer that expands the .tar file with the line that runs dotnet restore by using the && operator. Given the latter is dependent on the first, there's no advantage to caching them separately, so we may as well inline it:
RUN tar -xvf projectfiles.tar && dotnet restore
Putting it all together - the build script and Dockerfile
And we're all done! For completeness, the final build script and Dockerfile are shown below. This is functionally identical to the Dockerfile we started with, but it's now optimised to better handle changes to our ASP.NET Core app. If we add or remove a project from our app, we won't have to touch the Dockerfile, which is great! 🙂
The build script:
#!/bin/bash
set -eux
# tarball csproj files, sln files, and NuGet.config
find . \( -name "*.csproj" -o -name "*.sln" -o -name "NuGet.config" \) -print0 \
| tar -cvf projectfiles.tar --null -T -
docker build .
rm projectfiles.tar
The Dockerfile
# Build image
FROM microsoft/aspnetcore-build:2.0.3 AS builder
WORKDIR /sln
COPY projectfiles.tar .
RUN tar -xvf projectfiles.tar && dotnet restore
COPY ./test ./test
COPY ./src ./src
RUN dotnet build -c Release --no-restore
RUN dotnet test "./test/AspNetCoreInDocker.Web.Tests/AspNetCoreInDocker.Web.Tests.csproj" -c Release --no-build --no-restore
RUN dotnet publish "./src/AspNetCoreInDocker.Web/AspNetCoreInDocker.Web.csproj" -c Release -o "../../dist" --no-restore
#App image
FROM microsoft/aspnetcore:2.0.3
WORKDIR /app
ENV ASPNETCORE_ENVIRONMENT Local
ENTRYPOINT ["dotnet", "AspNetCoreInDocker.Web.dll"]
COPY --from=builder /sln/dist .
Summary
In this post I showed how you can use tar to package up your ASP.NET Core .csproj files to send to Docker. This lets you avoid having to manually specify all the project files explicitly in your Dockerfile.