This is the second in a series of posts looking at authentication and authorisation in ASP.NET Core. In the previous post, I talked about authentication in general and how claims-based authentication works. In this post I'm going to go into greater detail about how an AuthenticationMiddleware is implemented in ASP.NET Core, using the CookieAuthenticationMiddleware as a case study. Note that it focus on 'how the middleware is built' rather than 'how to use it in your application'.
Authentication in ASP.NET Core
Just to recap, authentication is the process of determining who a user is, while authorisation revolves around what they are allowed to do. In this post we are dealing solely with the authentication side of the pipeline.
Hopefully you have an understanding of claims-based authentication in ASP.NET Core at a high level. If not I recommend you check out my previous post. We ended that post by signing in a user with a call to AuthenticationManager.SignInAsync, in which I stated that this would call down to the cookie middleware in our application.
The Cookie Authentication Middleware
In this post we're going to take a look at some of that code in the CookieAuthenticationMiddleware, to see how it works under the hood and to get a better understanding of the authentication pipeline in ASP.NET Core. We're only looking at the authentication side of security at the moment, and just trying to show the basic mechanics of what's happening, rather than look in detail at how cookies are built and how they're encrypted etc. We're just looking at how the middleware and handlers interact with the ASP.NET Core framework.
So first of all, we need to add the CookieAuthentiationMiddleware to our pipeline, as per the documentation. As always, middleware order is important, so you should include it before you need to authenticate a user:
app.UseCookieAuthentication(new CookieAuthenticationOptions()
{
AuthenticationScheme = "MyCookieMiddlewareInstance",
LoginPath = new PathString("/Account/Unauthorized/"),
AccessDeniedPath = new PathString("/Account/Forbidden/"),
AutomaticAuthenticate = true,
AutomaticChallenge = true
});
As you can see, we set a number of properties on the CookieAuthenticationOptions when configuring our middleware, most of which we'll come back to later.
So what does the cookie middleware actually do? Well, looking through the code, surprisingly little actually - it sets up some default options and it derives from the base class AuthenticationMiddleware<T>. This class just requires that you return an AuthenticationHandler<T> from the overloaded method CreateHandler(). It's in this handler where all the magic happens. We'll come back to the middleware itself later and focus on the handler for now.
AuthenticateResult and AuthenticationTicket
Before we get in to the meaty stuff, there are a couple of supporting classes we will use in the authentication handler which we should understand: AuthenticateResult and AuthenticationTicket, outlined below:
public class AuthenticationTicket
{
public string AuthenticationScheme { get; }
public ClaimsPrincipal Principal{ get; }
public AuthenticationProperties Properties { get; }
}
AuthenticationTicket is a simple class that is returned when authentication has been successful. It contains the authenticated ClaimsPrinciple, the AuthenticationScheme indicating which middleware was used to authenticate the request, and an AuthenticationProperties object containing optional additional state values for the authentication session.
public class AuthenticateResult
{
public bool Succeeded
{
get
{
return Ticket != null;
}
}
public AuthenticationTicket Ticket { get; }
public Exception Failure { get; }
public bool Skipped { get; }
public static AuthenticateResult Success(AuthenticationTicket ticket)
{
return new AuthenticateResult() { Ticket = ticket };
}
public static AuthenticateResult Skip()
{
return new AuthenticateResult() { Skipped = true };
}
public static AuthenticateResult Fail(Exception failure)
{
return new AuthenticateResult() { Failure = failure };
}
}
An AuthenticateResult holds the result of an attempted authentication and is created by calling one of the static methods Success, Skip or Fail. If the authentication was successful, then a successful AuthenticationTicket must be provided.
The CookieAuthenticationHandler
The CookieAuthenticationHandler is where all the authentication work is actually done. It derives from the AuthenticationHandler base class, and so in principle only a single method needs implementing - HandleAuthenticateAsync():
protected abstract Task<AuthenticateResult> HandleAuthenticateAsync();
This method is responsible for actually authenticating a given request, i.e. determining if the given request contains an identity of the expected type, and if so, returns an AuthenticateResult containing the authenticated ClaimsPrinciple. As is to be expected, the CookieAuthenticationHandler implementation depends on a number of other methods but we'll run through each of those shortly:
protected override async Task<AuthenticateResult> HandleAuthenticateAsync()
{
var result = await EnsureCookieTicket();
if (!result.Succeeded)
{
return result;
}
var context = new CookieValidatePrincipalContext(Context, result.Ticket, Options);
await Options.Events.ValidatePrincipal(context);
if (context.Principal == null)
{
return AuthenticateResult.Fail("No principal.");
}
if (context.ShouldRenew)
{
RequestRefresh(result.Ticket);
}
return AuthenticateResult.Success(new AuthenticationTicket(context.Principal, context.Properties, Options.AuthenticationScheme));
}
So first of all, the handler calls EnsureCookieTicket() which tries to create an AuthenticateResult from a cookie in the HttpContext. Three things can happen here, depending on the state of the cookie:
- If the cookie doesn't exist, i.e. the user has not yet signed in, the method will return
AuthenticateResult.Skip(), indicating this status. - If the cookie exists and is valid, it returns a deserialised
AuthenticationTicketusingAuthenticateResult.Success(ticket). - If the cookie cannot be decrypted (e.g. it is corrupt or has been tampered with), if it has expired, or if session state is used and no corresponding session can be found, it returns
AuthenticateResult.Fail().
At this point, if we don't have a valid AuthenticationTicket, then the method just bails out. Otherwise, we are theoretically happy that a request is authenticated. However at this point we have literally just taken the word of an encrypted cookie. It's possible that things may have changed in the back end of your application since the cookie was issued - the user may have been deleted for instance! To handle this, the CookieHandler calls ValidatePrincipal, which should set the ClaimsPrincipal to null if it is no longer valid. If you are using the CookieAuthenticationMiddleware in your own apps and are not using ASP.NET Core Identity, you should take a look at the documentation for handling back-end changes during authentication.
SignIn and SignOut
For the simplest authentication, implementing HandleAuthenticateAsync is all that is required. In reality however, you will need to override other methods of AuthenticationHandler in order to have usable behaviour. The CookieAuthenticationHandler needs more behaviour than just this method - HandleAuthenticateAsync means we can read and deserialise and authentication ticket to a ClaimsPrinciple, but we also need to have the ability to set a cookie when the user signs in, and to remove the cookie when the user signs out.
The HandleSignInAsync(SignInContext signin) method builds up a new AuthenticationTicket, encrypts it, and writes the cookie to the response. It is called internally as part of a call to SignInAsync(), which in turn is called by AuthenticationManager.SignInAsync(). I won't cover this aspect in detail in this post, but it is the AuthenticationManager which you would typically invoke from your AccountController after a user has successfully logged in. As shown in my previous post, you would construct a ClaimsPrincipal with the appropriate claims and pass that in to AuthenticationManager, which eventually would reach the CookieAuthenticationMiddleware and allow you to set the cookie. Finally, if the user is currently on the login page, it redirects the user to the return url.
At the other end of the process, HandleSignOutAsync deletes the authentication cookie from the context, and if the user is on the logout page, redirects the user to the return url.
Unauthorised vs Forbidden
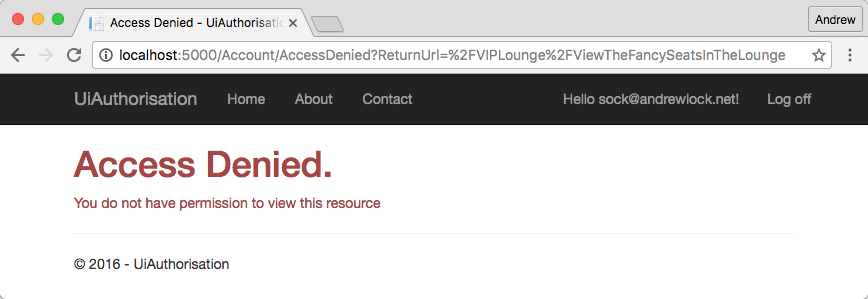
The final two methods of AuthenticationHandler which are overridden in the CookieAuthenticationHandler deal with the case where authentication or authorisation has failed. These two cases are distinct but easy to confuse.
A user is unauthorised if they have not yet signed in. This corresponds to a 401 when thinking about HTTP requests. A user is forbidden if they have already signed in, but the identity they are using does not have permission to view the requested resource, which corresponds to a 403 in HTTP.
The default implementations of HandleUnauthorizedAsync and HandleForbiddenAsync in the base AuthenticationHandler are very simple, and look like this (for the forbidden case):
protected virtual Task<bool> HandleForbiddenAsync(ChallengeContext context)
{
Response.StatusCode = 403;
return Task.FromResult(true);
}
As you can see, they just set the status code of the response and leave it at that. While perfectly valid from an HTTP and security point of view, leaving the methods as that would give a poor experience for users, as they would simply see a blank screen:
Instead, the CookieAuthenticationHandler overrides these methods and redirects the users to a different page. For the unauthorised response, the user is automatically redirected to the LoginPath which we specified when setting up the middleware. The user can then hopefully login and continue where they left off.
Similarly, for the Forbidden response, the user is redirected to the path specified in AccessDeniedPath when we added the middleware to our pipeline. We don't redirect to the login path in this case, as the user is already authenticated, they just don't have the correct claims or permissions to view the requested resource.
Customising the CookieHandler using CookieHandlerOptions
We've already covered a couple of the properties on the CookieAuthenticationOptions we passed when creating the middleware, namely LoginPath and AccessDeniedPath, but it's worth looking at some of the other common properties too.
First up is AuthenticationScheme. In the previous post on authentication we said that when you create an authenticated ClaimsIdentity you must provide an AuthenticationScheme. The AuthenticationScheme provided when configuring the middleware is passed down into the ClaimsIdentity when it is created, as well as into a number of other fields. It becomes particularly important when you have multiple middleware for authentication and authorisation (which I'll go into on a later post).
Next, up is the property AutomaticAuthenticate, but that requires us to back peddle slightly, to think about how the authentication middleware works. I'm going to assume you understand about ASP.NET Core middleware in general, if not it's probably worth reading up on it first!
The AuthenticationHandler Middleware
The CookieAuthenticationMiddleware is typically configured to run relatively early in the pipeline. The abstract base class AuthentictionMiddleware<T> from which it derives has a simple Invoke method, which just creates a new handler of the appropriate type, initialises it, runs the remaining middleware in the pipeline, and then tears down the handler:
public abstract class AuthenticationMiddleware<TOptions>
where TOptions : AuthenticationOptions, new()
{
private readonly RequestDelegate _next;
public string AuthenticationScheme { get; set; }
public TOptions Options { get; set; }
public ILogger Logger { get; set; }
public UrlEncoder UrlEncoder { get; set; }
public async Task Invoke(HttpContext context)
{
var handler = CreateHandler();
await handler.InitializeAsync(Options, context, Logger, UrlEncoder);
try
{
if (!await handler.HandleRequestAsync())
{
await _next(context);
}
}
finally
{
try
{
await handler.TeardownAsync();
}
catch (Exception)
{
// Don't mask the original exception, if any
}
}
}
protected abstract AuthenticationHandler<TOptions> CreateHandler();
}
As part of the call to InitializeAsync, the handler verifies whether AutomaticAuthenticate is true. If it is, then the handler will immediately run the method HandleAuthenticateAsync, so all subsequent middleware in the pipeline will see an authenticated ClaimsPrincipal. In contrast, if you do not set AutomaticAuthenticate to true, then authentication will only occur at the point authorisation is required, e.g. when you hit an [Authorize] attribute or similar.
Similarly, during the return path through the middleware pipeline, if AutomaticChallenge is true and the response code is 401, then the handler will call HandleUnauthorizedAsync. In the case of the CookieAuthenticationHandler, as discussed, this will automatically redirect you to the login page specified.
The key points here are that when the Automatic properties are set, the authentication middleware always runs at it's configured place in the pipeline. If not, the handlers are only run in response to direct authentication or challenge requests. If you are having problems where you are returning a 401 from a controller, and you are not getting redirected to the login page, then check the value of AutomaticChallenge and make sure it's true.
In cases, where you only have a single piece of authentication middleware, it makes sense to have both values set to true. Where it gets more complicated is if you have multiple authentication handlers. In that case, as explained in the docs, you must set AutomaticAuthenticate to false. I'll cover the specifics of using multiple authentication handlers in a subsequent post but the docs give a good starting point.
Summary
In this post we used the CookieAuthenticationMiddleware as an example of how to implement an AuthenticationMiddleware. We showed some of the methods which must be handled in order to implement an AuthenticationHandler, the methods called to sign a user in and out, and how unauthorised and forbidden requests are handled.
Finally, we showed some of the common options available when configuring the CookieAuthenticationOptions, and the effects they have.
In later posts I will cover how to configure your application to use multiple authentication handlers, how authorisation works and the various ways to use it, and how ASP.NET Core Identity pulls all of these aspects together to do the hard work for you.