In this post I show 5 different ways to change which URLs your app listens on.
There are multiple ways to set the URLs that ASP.NET Core binds to on startup. I have an old post about the various options available to you that applies to ASP.NET Core 1.0, but the options available in ASP.NET Core 3.x are much the same:
UseUrls() - Set the URLs to use statically in Program.cs.
Environment variables - Set the URLs using DOTNET_URLS or ASPNETCORE_URLS.
Command line arguments - Set the URLs with the --urls parameter when running from the command line.
Using launchSettings.json - Set the URLs using the applicationUrl property.
KestrelServerOptions.Listen() - Configure addresses for Kestrel server manually using Listen().
We'll look at each of these options in more detail below.
What URLs can you use?
In this post I describe the "URLs" you can bind to, but you can't use just any URL. There are essentially 3 classes of URLs that you can bind:
The "loopback" hostname for IPv4 and IPv6 (e.g. http://localhost:5000), in the format: {scheme}://{loopbackAddress}:{port}
A specific IP address available on your machine (e.g. http://192.168.8.31:5005), in the format {scheme}://{IPAddress}:{port}
"Any" IP address for a given port (e.g. http://*:6264), in the format {scheme}://*:{port}
The port in the above patterns is also optional - if you omit it, the default port for the given scheme is used instead (port 80 for http, port 443 for https).
Which of these pattern you choose will depend on your deployment mechanism. For example, if you're hosting multiple applications on a "bare metal" machine, you may well need to set an explicit IPAddress. If you're hosting in a container, then you can generally use a localhost address.
Watch out for the "any" IP address format - you don't have to use *, you can use anything that's not an IP Address and is not localhost. That means you can use http://*, http://+, http://mydomain, or http://example.org. All of these behave identically, and listen on any IP address. If you only want to handle requests from a single hostname, you need to configure host filtering in addition.
Once you know the URLs you need to listen on, you need to tell your application about them. In this post I show 5 possible ways of doing that.
UseUrls()
The first, and easiest, option to set the binding URLs is to hard code them when configuring the IWebHostBuilder using UseUrls():
Hard-coding the URLs never feels like a particularly clean or extensible solution, so this option isn't really useful for anything more than demos.
Luckily, you can also load the URLs from an external configuration file, from environment variables, or from command line arguments.
Environment variables
.NET Core uses two types of configuration:
App configuration is the configuration you typically use in your application, and is loaded from appSettings.json and environment variables, among other places.
Host configuration is used to configure basic things about your application, like the hosting environment and the host URLs to use.
The host configuration is the one we're interested in when considering how to set the URLs for our application. By default, host configuration values are loaded from three different sources:
Environment variables that have the prefix DOTNET_. The environment variables have the prefix removed and are added to the collection.
Command line arguments.
Environment variables that have the prefix ASPNETCORE_. For ASP.NET Core apps only, these environment variables are also added. These aren't added if you are creating a generic-host-based worker service.
If you don't override them manually with UseUrls(), then ASP.NET Core will use the value of the URLS key from the configuration system. Based on the description above you can set the URLS using either of the following environment variables:
DOTNET_URLS
ASPNETCORE_URLS
If you set both of these environment variables, the ASPNETCORE_URLS parameter takes precedence.
You can set environment variables in the usual way based on your environment. For example, using the command line:
As you can see above, you can also pass multiple addresses to listen on (using HTTP or HTTPS) by separating them with a semicolon.
Command line arguments
The other way to set host configuration values is to use the command line. Command line arguments override the value of the environment variables if they're set. Simply use the --urls parameter:
dotnet run --urls "http://localhost:5100"
As before, you can pass multiple URLs to listen on by separating them with a semicolon:
dotnet run --urls "http://localhost:5100;https://localhost:5101"
Environment variables and command line arguments are probably the most common way to set URLs for an application in production, but they're a bit cumbersome for local development. It's often easier to using launchSettings.json instead.
launchSettings.json
Most .NET project templates include a launchSettings.json file in the Properties folder. This file contains various profiles for launching your ASP.NET Core application. A typical file contains one definition for launching the profile directly from the command line and one definition for launching the profile using IIS Express. This file drives the Debug drop-down in Visual Studio:
launchSettings.json provides an easy way to set the application URLs via the applicationUrl property - you can see one under the iisSettings for IIS express, and one under TestApp (the name of the application for this file).
You don't need to do anything special to use this file — dotnet run will pick it up automatically.
launchSettings.json also provides an easy way to set additional environment variables using the environmentVariables, as you can see from the file above.
When you run your app from the command line with dotnet run, your app will use the applicationUrl properties in the "Project" command: https://localhost:5001;http://localhost:5000 in the file above. When you run the app using the "IISExpress" command, your app will use the applicationUrl from the iisSettings.iisExpress node: http://localhost:38327
This file is the easiest way to configure your environment when developing locally. In fact, you have to go out of your way to not use the launchSettings.json:
dotnet run --no-launch-profile
This will skip over the launchSettings.json file and fall back to the machine environment variables to determine the URLs instead.
All of the approaches shown so far set the URLs for Kestrel indirectly, but you can also set them directly.
KestrelServerOptions.Listen()
Kestrel is configured by default in almost all ASP.NET Core apps. If you wish, you can configure the endpoints for Kestrel manually, or via configuring KestrelServerOptions using the IConfiguration system.
I've never found myself actually needing to do this, and there's a lot of configuration options available, so for the most part I suggest referring to the documentation. As an example, you can use the Listen() functions exposed by KestrelServerOptions:
publicclassProgram{publicstaticvoidMain(string[] args){CreateHostBuilder(args).Build().Run();}publicstaticIHostBuilderCreateHostBuilder(string[] args)=>
Host.CreateDefaultBuilder(args).ConfigureWebHostDefaults(webBuilder =>{
webBuilder.UseStartup<Startup>();
webBuilder.UseKestrel(opts =>{// Bind directly to a socket handle or Unix socket// opts.ListenHandle(123554);// opts.ListenUnixSocket("/tmp/kestrel-test.sock");
opts.Listen(IPAddress.Loopback, port:5002);
opts.ListenAnyIP(5003);
opts.ListenLocalhost(5004, opts => opts.UseHttps());
opts.ListenLocalhost(5005, opts => opts.UseHttps());});});}
This configuration sets Kestrel listening on multiple addresses. It's hard-coded in the example above, but it doesn't have to be — you can bind to an IConfiguration instead. When you set the URLs for kestrel in this way, it overrides the URLS configuration value if you've set it through one of the other mechanisms as well, such as environment variables. You'll see a warning in the logs if that happens:
warn: Microsoft.AspNetCore.Server.Kestrel[0]
Overriding address(es)'http://localhost:5007'. Binding to endpoints defined in UseKestrel() instead.
info: Microsoft.Hosting.Lifetime[0]
Now listening on: http://127.0.0.1:5002
info: Microsoft.Hosting.Lifetime[0]
Now listening on: http://[::]:5003
Personally I haven't found a need to set the listening endpoints in Kestrel this way, but it's good to be aware that you can get complete control of Kestrel like this if you need it.
Summary
In this post I showed five different ways you can set the URLs that your application listens on. UseUrls() is one of the simplest, but generally isn't suitable for production workloads. The --urls command line argument and ASPNETCORE_/DOTNET_ environment variables are most useful for setting the values in production. The launchSettings.json file is very useful for setting the URLs in a development environment. If you need fine-grained control over your configuration, you can use Kestrel's Listen* options directly. These can also be loaded from configuration for easy use in both production and development.
This post is in response to a discussion I had with a friend recently who was trying out .NET Core. Unfortunately, when they attempted to start their new application they received the following message:
crit: Microsoft.AspNetCore.Server.Kestrel[0]
Unable to start Kestrel.
System.IO.IOException: Failed to bind to address http://127.0.0.1:5000: address already in use.
When you create a new .NET project using a template, it always uses the same URLs, defined in
Unfortunately, the MacBook had a driver installed that was already bound to port 5000, so whenever the .NET Core project attempted to start, the port would conflict, and they'd the see error above. Not a great experience!
In this post I show one way to resolve the problem by randomising the ports ASP.NET Core uses when it starts the application. I'll also show how you can work out which port the application has selected from inside your app.
Randomly selecting a free port in ASP.NET Core
In my previous post, I showed some of the ways you can set the URLs for your ASP.NET Core application. Unfortunately, all of those approaches still require that you choose a port to use. When you're developing locally, you might not care about that, just run the application!
You can achieve exactly this by using the special port 0 when setting the URL to use. For example, to bind to a random http and https port on the loopback (localhost) address, run your application using the following command:
dotnet run --urls "http://[::1]:0;https://[::1]:0"
This will randomly select a pair of ports that aren't currently in use, for example:
info: Microsoft.Hosting.Lifetime[0]
Now listening on: http://[::1]:54213
info: Microsoft.Hosting.Lifetime[0]
Now listening on: https://[::1]:54214
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
Alternatively, instead of binding to the loopback address, you can bind to any IP address (using a random port) with the following command:
dotnet run --urls "http://*:0"
This binds to all IPv4 and IPv6 addresses on a random port.
The * isn't actually special, you just need to use something that isn't a valid IPv4 or IPv6 IP address (or localhost). Even a hostname is treated the same as * i.e. it binds to all IP addresses on the machine.
The downside of choosing at random port at runtime is that you get a different pair of ports every time you run the application. That may or may not be a problem for you.
When is this useful?
On the face of it, having your application listen on a different URL every time you restart it doesn't sound very useful. It would be incredibly irritating to have to type a new URL into your browser (instead of just hitting refresh) every time you restart the app. So why would you do this?
The one time I use this approach is when building worker services that run background tasks in Kubernetes.
But wait, isn't the whole point of worker services that they don't run Kestrel and expose URLs?
Well, yes, but due to the issues in the 2.x implementation of worker services, I typically still use a full WebHost based ASP.NET Core app, instead of a generic Host app. Now, in ASP.NET Core 3.0, those problems have been resolved, but I still don't use the generic host…
The problem is, I'm running applications in Kubernetes. An important part of that is having liveness/health checks, that check that the application hasn't crashed. The typical approach is to expose an HTTP or TCP endpoint that the Kubernetes infrastructure can call, to verify the application hasn't crashed.
Exposing an HTTP or TCP endpoint…that means, you guessed it, Kestrel!
An HTTP/TCP health check endpoint is very common for applications, but there are other options. For example you could use a command that checks for the presence of a file, or some other mechanism. I'd be interested to know in the comments if you're using a different mechanism for health checks of your worker services!
When the application is running in Kubernetes, the application obviously needs to use a known URL, so I don't use random port selection running when it's running in production. But when developing locally on my dev machine, I don't care about the port at all. Running locally, I only care that the background service is running, not the health check endpoint. So for those services, the random port selection works perfectly.
How do I found out which port was selected?
For the scenario I've described above, it really doesn't matter which port is selected, as it's not going to be used. But in some cases you may need to determine that at runtime.
You can find out which port (and IP Address) your app is listening on using the IServerAddressesFeature, using the following approach:
var server = services.GetRequiredService<IServer>();var addressFeature = server.Features.Get<IServerAddressesFeature>();foreach(var address in addressFeature.Addresses){
_log.LogInformation("Listing on address: "+ address);}
Note that Kestrel logs this information by default on startup, so you shouldn't need to log it yourself. You might need it for other purposes though, to register with Consul for example, so logging is just a simple example.
The question is, where should you write that code? Depending on where you put it, you can get very different answers.
You might consider placing it inside Startup.Configure(), where you can easily access the server features on IApplicationBuilder:
publicclassStartup{publicvoidConfigure(IApplicationBuilder app, ILogger<Startup> log){// IApplicationBuilder exposes an IFeatureCollection property, ServerFeaturesvar addressFeature = app.ServerFeatures.Get<IServerAddressesFeature>();foreach(var address in addressFeature.Addresses){
_log.LogInformation("Listing on address: "+ address);}}// ... other configuration}
Unfortunately, that doesn't work either. In this case, Addresses isn't empty, but it contains the values you provided with the --urls command, or using the ASPNETCORE_URLS variable, with the port set to 0:
Listing on address: http://*:0
Listing on address: http://[::1]:0
That's not very useful either, we want to know which ports are chosen!
The only safe place to put the code is somewhere that will run after the application has been completely configured, and Kestrel is handling requests. The obvious place is in an MVC controller, or in middleware.
The following middleware shows how you could create a simple endpoint that returns the addresses being used as a comma delimited string:
publicclassServerAddressesMiddleware{privatereadonlyIFeatureCollection _features;publicServerAddressesMiddleware(RequestDelegate _,IServer server){
_features = server.Features;}publicasyncTaskInvoke(HttpContext context){// fetch the addressesvar addressFeature = _features.Get<IServerAddressesFeature>();var addresses = addressFeature.Addresses;// Write the addresses as a comma separated listawait context.Response.WriteAsync(string.Join(",", addresses));}}
We can add this middleware as an endpoint:
publicclassStartup{// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.publicvoidConfigure(IApplicationBuilder app){
app.UseRouting();
app.UseEndpoints(endpoints =>{// Create the address endpoint, consisting of our middlewarevar addressEndpoint = endpoints
.CreateApplicationBuilder().UseMiddleware<ServerAddressesMiddleware>().Build();// Register the endpoint
endpoints.MapGet("/addresses", addressEndpoint);});}}
Now when you hit the /addresses endpoint, you'll finally get the actual addresses your application is listening on:
Of course, middleware is clearly not the place to be handling this sort of requirement, as you would need to know the URL to call before you call the URL that tells you what URL to call! 🤪 The point is just that this information isn't available until after you can handle requests!
For example, the following code registers a callback that waits for Kestrel to be fully configured, and then logs the addresses:
publicclassStartup{publicvoidConfigure(IApplicationBuilder app,IHostApplicationLifetime lifetime, ILogger<Startup> logger){// Register a callback to run after the app is fuly configured
lifetime.ApplicationStarted.Register(()=>LogAddresses(app.ServerFeatures, logger));// other config}// Called after configuration is completestaticvoidLogAddresses(IFeatureCollection features,ILogger logger){var addressFeature = features.Get<IServerAddressesFeature>();// Do something with the addressesforeach(var addresses in addressFeature.Addresses){
logger.LogInformation("Listening on address: "+ addresses);}}}
This approach gives you access to your application's URLs at one of the earliest points they're available in your application's lifetime. Just be aware that the callback can't be async, so you can't do anything especially fancy there!
Summary
In this post I described how to use the "magic port 0" to tell your ASP.NET Core application to choose a random port to listen on. I use this approach locally when creating background services that I don't need to make HTTP requests to (but which I want to expose an HTTP endpoint for liveness checks in Kubernetes).
I also showed how you can find out the actual URLs your application is listening on at runtime using the IServerAddressesFeature. I showed that you need to be careful when you call this feature - calling it too early in your application's startup could give you either an empty list of addresses, the requested list of addresses (i.e. the "port 0" addresses), or the actual addresses. Make sure to only use this feature after application configuration is complete, for example from middleware, from an MVC controller, or in the IHostApplicationLifetime.ApplicationStarted callback.
In this post I show a simple way to obfuscate email addresses to make it harder for bots to scrape them from your site. It uses a similar approach as Cloudflare Scrape Shield.
It's important to not that the encoding scheme used here is incredibly weak. But that's kind of the point. It's only meant to provide rudimentary protection against automated scraping by bots. It's obfuscation, not encryption!
Background - Cloudflare Scrape Shield
I include my email address on the about page of my blog in case people want to get in touch. I've personally only ever had pleasant emails from people (though I'm well aware that's a rarity for many people in our industry). Somewhat surprisingly perhaps, I don't get a huge amount of spam because of it.
Some time ago I moved my blog from a self-hosted instance of Ghost to Netlify. At the same time, I also removed the Cloudflare caching layer, as Netlify uses its own layer of caching. One of the features of Cloudflare is Scrape Shield. This has multiple parts to it, but the one I was most interested in was email obfuscation.
Cloudflare's email obfuscation works by modifying the HTML output of your app when they serve it. If cloudflare detects an email address in an <a> tag, for example:
When the page is served, the email-decode.min.js script is executed, and the <a> tag is replaced with the original. The advantage of this is that bots need to execute the JavaScript on your page in order to retrieve your email address, which raises the barrier (slightly) for bots trying to scrape the email address from your app.
To avoid causing problems, there are a bunch of places that Cloudflare won't obfuscate email addresses. See the documentation for details.
When I moved my blog from Cloudflare to Netlify, I didn't want to lose that email obfuscation, so I looked at how I could implement it myself. Luckily, it's pretty trivial to achieve, as I found from reading this excellent post. This post is very much based on that one.
So, how does the email address "encryption" work?
Decoding an obfuscated email address
First of all, while technically encryption, the scheme is so weak, you really shouldn't think of it as that. It's more just like obfuscation. That's all that's required for our intended goal, but it's important to keep in mind.
I'll start with the decoding strategy - how do you retrieve the email address from the encoded version shown previously?
The email is encoded into the # portion of the modified attribute, i.e. /cdn-cgi/l/email-protection#EMAIL. In the previous example, that was:
a5c0ddc4c8d5c9c0e5c0ddc4c8d5c9c08bcad7c2
The overall strategy to decoding this is as follows:
Remove the first 2 characters (a5), and convert to its hex equivalent value (165). This is the key for the rest of the calculation.
Iterate through the remainder of the characters, incrementing by two. For each pair of characters (the first pair is c0):
Convert the pair to its hex equivalent (192)
Perform a bitwise XOR of the number with the key. so 165 ^ 192 = 101
Convert the result (101) to its UTF-16 equivalent (e)
Append the result to previous results
Repeat until all characters are consumed. The final result is the original email
The XOR scheme used is one of the most basic encryption schemes possible. And on top of that, the key for the encryption is stored right along-side the cipher text! Again, this is not secure encryption; it is simply obfuscation.
This is actually a simplified description of the cloudflare approach - Cloudflare have an additional step to handle Unicode codepoints (which can be multiple bytes long). See this blog post for a description of that step.
So how can you implement this algorithm for your own apps?
Implementing email obfuscation on your own blog
Cloudflare dynamically replaces email addresses in your HTML, and injects additional scripts into the DOM. That's not really necessary in my case - my blog is statically generated, and even if it wasn't, there's probably only a few email addresses I would want to be encoding.
Because of those constraints, I opted to encode the email address on my blog ahead of time, rather than trying to do it on-the-fly. I can also then just include the email decoding script in the standard JavaScript bundle for the site.
Encoding the email address
Given you have an email address you want to obfuscate on your site, e.g. `example@example.org`, how can you encode that in the required format?
I wrote a small JavaScript function that takes an email address, and a key in the range 0-255 and outputs an obfuscated email address. It uses the algorithm from the previous section in reverse to generate the output:
functionencodeEmail(email, key){// Hex encode the keyvar encodedString = key.toString(16);// loop through every character in the emailfor(var n=0; n < email.length; n++){// Get the code (in decimal) for the nth charactervar charCode = email.charCodeAt(n);// XOR the character with the keyvar encoded = charCode ^ key;// Hex encode the result, and append to the output string
encodedString += encoded.toString(16);}return encodedString;}
I only have a couple of emails on my blog I want to obfuscate, so I ran them through this function, choosing an arbitrary key. I used Chrome's dev tools to run it - open up any old website, hit F12 to view the console, and copy-paste the function above. Then run the function using your email, picking a random number between 0-255:
encodeEmail('example@example.org',156);
The hex encoded output is what we'll use in our website.
The code to decode the email is is very similar.
Decoding the email address
The function to decode an email address from the encoded string is shown below, and follows the algorithm shown previously:
functiondecodeEmail(encodedString){// Holds the final outputvar email ="";// Extract the first 2 lettersvar keyInHex = encodedString.substr(0,2);// Convert the hex-encoded key into decimalvar key =parseInt(keyInHex,16);// Loop through the remaining encoded characters in steps of 2for(var n =2; n < encodedString.length; n +=2){// Get the next pair of charactersvar charInHex = encodedString.substr(n,2)// Convert hex to decimalvar char =parseInt(charInHex,16);// XOR the character with the key to get the original charactervar output = char ^ key;// Append the decoded character to the output
email += String.fromCharCode(output);}return email;}
When you pass this function an encoded email, you'll get your original back:
Now lets look at how to use these functions in a website.
Replacing existing emails with obfuscated emails
I only use my email in anchor tags, so I want the final (unencoded) tag on my blog to look something like the following:
If bots scrape the website, they won't see an easily recognisable email, which will hopefully go some way to prevent it being scraped.
There's lots of different points at which you could decode the string, depending on the experience you want. You could keep the string encoded on your website until someone clicks a "reveal" button for example. I had a very simple use case, so I chose to automatically decode the email immediately when the page loads.
// Find all the elements on the page that use class="eml-protected"var allElements = document.getElementsByClassName("eml-protected");// Loop through all the elements, and update themfor(var i =0; i < allElements.length; i++){updateAnchor(allElements[i])}functionupdateAnchor(el){// fetch the hex-encoded stringvar encoded = el.innerHTML;// decode the email, using the decodeEmail() function from beforevar decoded =decodeEmail(encoded);// Replace the text (displayed) content
el.textContent = decoded;// Set the link to be a "mailto:" link
el.href ='mailto:'+ decoded;}
Hopefully the code is self explanatory, but I'll walk through it here
Find all elements on the page with the class eml-protected
For each element:
Fetch the inner text (9cf9e4fdf1ecf0f9dcf9e4fdf1ecf0f9b2f3eefb) in the example above
Run the inner text through the decoder, to get the real email address
Set the href of the anchor to be mailto:example@example.org.
The code is functionally complete, but there's a lot of short-cuts:
No error checking or handling
Assumes that all eml-protected elements are <a> tags
Assumes the document is fully loaded before the script runs
Assumes the encoded email isn't corrupted or invalid
If you're applying this approach to a larger site, you don't have strict control over the contents, or any of these assumptions don't hold, then you'll probably need to be more careful. For my purposes, this is more than enough 🙂
Summary
In this post I showed how you can obfuscate email addresses on a website to make it harder for bots to easily scrape them. The encoding scheme is based on the one used in Cloudflare's scrape shield product, which uses a simple XOR scheme to hide the data as a hex-string. This is not at all "secure", especially as the key for decoding is included in the string, but it serves its purposes of obfuscating emails from automated systems.
Mass assignment, also known as over-posting, is an attack used on websites that use model-binding. It is used to set values on the server that a developer did not expect to be set. This is a well known attack now, and has been discussed many times before, (it was a famous attack used against GitHub some years ago). In this post I describe how to stay safe from oper posting with Razor Pages.
This post is an updated version of one I wrote several years ago, talking about over posting attacks in ASP.NET Core MVC controllers. The basic premise is exactly the same, though Razor Pages makes it much easier to do the "right" thing.
What is mass assignment?
Mass assignment occurs during the model binding phase of a Razor Pages request. It happens when a user sends data in a request that you weren't expecting to be there, and that data is used to modify state on the server.
It's easier to understand with an example. Lets imagine you have a form on your website where a user can edit their name. On the same form, you also want to display some details about the user that they shouldn't be able to edit - whether they're an admin user.
Lets imagine you have the following very simple domain model of a user:
publicclassAppUser{publicstring Name {get;set;}publicbool IsAdmin {get;set;}}
It has three properties, but you only actually allow the user to edit the Name property - the IsAdmin property is just used to control the markup they see, by adding an "Admin" badge to the markup.
In the above Razor Page, the CurrentUser property exposes the AppUser instance that we use to display the form correctly. The vulnerability in the Razor Page is because we're directly model-binding a domain model AppUser instance to the incoming request and using that data to update the database:
Don't use the code below, it's riddled with issues!
publicclassVulnerableModel:PageModel{privatereadonlyAppUserService _users;publicVulnerableModel(AppUserService users){
_users = users;}[BindProperty]// Binds the AppUser properties directly to the requestpublicAppUser CurrentUser {get;set;}publicIActionResultOnGet(int id){
CurrentUser = _users.Get(id);// load the current user. Needs null checks etcreturnPage();}publicIActionResultOnPost(int id){if(!ModelState.IsValid){returnPage();}
_users.Upsert(id, CurrentUser);// update the user with the properties provided in AppUserreturnRedirectToPage();}}
On the face of it, this might seem OK - in the normal browser flow, a user can only edit the Name field. When they submit the form, only the Name field will be sent to the server. When model binding occurs on the model parameter, the IsAdmin field will be unset, and the Name will have the correct value:
However, with a simple bit of HTML manipulation, or by using Postman/Fiddler for example, a malicious user can set the IsAdmin field to true, even though you didn't render a form field for it. The model binder will dutifully bind the value to the request:
If you update your database/state with the provided IsAdmin value (as the previous Razor Page does) then you have just fallen victim to mass assignment/over posting!
There's a very simple way to solve this with Razor Pages, and thankfully, it's pretty much the default approach for Razor Pages.
Using a dedicated InputModel to prevent over posting
The solution to this problem is actually very commonly known, and comes down to this: use a dedicated InputModel.
Instead of model-binding to the domain model AppUser class that contains the IsAdmin property, create a dedicated InputModel that contains only the properties that you want to bind in your form. This is commonly defined as a nested class in the Razor Page where it's used.
With this approach, we can update the Razor Page as follows:
publicclassSafeModel:PageModel{privatereadonlyAppUserService _users;publicSafeModel(AppUserService users){
_users = users;}[BindProperty]publicInputModel Input {get;set;}// Only this property is model boundpublicAppUser CurrentUser {get;set;}// NOT model boundpublicIActionResultOnGet(int id){
CurrentUser = _users.Get(id);// Needs null checks etc
Input =newInputModel{ Name = CurrentUser.Name };// Create an InputModel from the AppUserreturnPage();}publicIActionResultOnPost(int id){if(!ModelState.IsValid){
CurrentUser = _users.Get(id);// Need to re-set properties that weren't model boundreturnPage();}var user = _users.Get(id);
user.Name = Input.Name;// Only update the properties that have changed
_users.Upsert(id, user);returnRedirectToPage();}// Only properties on this nested class will be model boundpublicclassInputModel{publicstring Name {get;set;}}}
We then update the Razor Page slightly, so that the form inputs bind to the Input property, instead of CurrentUser:
In the example above, we still have access to the same AppUser object in the view as we did before, so we can achieve exactly the same functionality (i.e. display the IsAdmin badge).
Only the Input property is model bound, so malicious users can only set properties that exist on the InputModel
We have to "re-populate" values in the OnPost that weren't model bound. In practical terms this was required for correctness previously too, I just ignored it…
To set values on our "domain" AppUser object, we rely on "manual" left-right copying from the InputModel to the AppUser before you save it.
Overall, there's essentially no down-sides to this approach. The only additional work you have to do is define the nested class InputModel, and also copy the values from the input to the domain object, but I'd argue they're not really downsides.
First, the nested InputModel isn't strictly necessary. In this very simple example, it's pretty much redundant, as it only has a single property, which could be set directly on the PageModel instead. If you prefer, you could do this:
publicclassSafeModel:PageModel{[BindProperty]publicstring Name {get;set;}}
In practice though, your InputModel will likely contain many properties, potentially with multiple data annotation attributes for validation etc. I really like having all that encapsulated in a nested class. It also simplifies the PageModel overall and makes all your pages consistent, as every page has just a single bound property called Input of type PAGENAME.InputModel. Also, being a nested class, I don't have to jump around in the file system, so there's no real overhead there either.
The final point, having to copy values back and forth between your InputModel and your domain object (AppUser) is a bit annoying. But there's not really anything you can do about that. Code like that has to exist somewhere in your application, and you already know it can't be in the model binder! You can potentially use tools like AutoMapper to automate some of this.
Another approach, which keeps separate Input and Output models is using a mediator. With this approach, the request is directly model-bound to a "command" which is dispatched to a mediator for handling. This command is the "input" model. The response from the mediator serves as the output model.
Using a separate InputModel like this really is the canonical way to avoid over-posting in Razor Pages, but I think it's interesting to consider why this approach didn't seem to be as prevalent with MVC.
Defending against over posting in MVC
In my previous post on over posting in ASP.NET Core MVC, I described multiple different ways to protect yourself from this sort of attack, many of which used extra features of the model binder to "ignore" the IsAdmin property. This typically involves adding extra attributes, like [Bind], [BindNever], or [ModelMetadataType] to convince the model binder to ignore the IsAdmin field.
The simplest option, and the best in my (and others) opinion, is simply to use separate input and output models for MVC too. The "Output" model would contain the IsAdmin and Name properties, so can render the view as before. The "Input" model would only contain the Name property, so isn't vulnerable to over posting, just as for Razor Pages.
publicclassInputModel{publicstring Name {get;set;}}
So if the answer is as simple as that, why isn't in more popular?
To be clear, it is very popular, especially if you're using the Mediator pattern with something like MediatR. I really mean why isn't it the default in all sample code for example?
As far as I can tell, the reason that separate Input/Output models wasn't more popular stems from several things:
The C# convention of a separate file per class. Even the small overhead of creating another file can be enough to discourage good practices!
The "default" MVC layout. Storing Controller, View, and Models files separately in a project, means lots of jumping around the file system. Coupled with the separate-file convention, that's just more overhead. Feature slices are designed to avoid this problem.
Properties on the Output model must be model-bound to the equivalent properties on the Input model. That means properties on the Input model must be named exactly the same as those on the Output model that are used to render the view. Similarly, validation metadata must be kept in-sync between the models.
The perceived additional left-right copying between models required. I say perceived, because once you close the over-posting vulnerability you realistically have to have some left-right copying somewhere, it just wasn't always as obvious!
These minor annoyances all add up in MVC which seems to discourage the "separate input/output" model best practice. So why didn't that happen for Razor Pages?
Razor Pages inherently tackles the first 2 points, by co-locating handlers, models, and views. It's hard to overstate just how beneficial this is compared to separate MVC views and controllers, but you really have to try it to believe it!
Point 3 above could be tackled in MVC either by using inheritance, by using separate "metadata" classes, or by using composition. Razor Pages favours the composition approach, where the InputModel is composed with the other properties required to render the view on the PageModel (CurrentUser in my previous example). This neatly side-steps many of the issues with using composition, and just fits really well into the Razor Pages model.
Point 4 is still there for Razor Pages, but as I mentioned, it's pretty much a fact of life. The only way around that is to bind directly to domain models, which you should never do, even if the ASP.NET Core getting started code does it!😱
Bonus: over posting protection != authorization
Before we finish, I just want to address a point that always seems to come up when discussing over posting:
You could edit the id parameter to update the name for a different user. How does separate-models protect against that?
The short answer: it doesn't. But it's not trying to.
The Razor Page I described above allows anyone to edit the name of anyAppUser - you just need to provide a valid ID in the URL. We can't easily remove the ID from the URL, or prevent users from sending it, as we need to know which user to edit the name for. There's only really 3 feasible approaches:
Store the ID in state on the server-side. Now you've got a whole different set of problems to manage!
Encrypt the ID and echo it back in the request. Again, way more complex than you need, and if done incorrectly can be a security hole, or not offer the protection you think it does.
In this post I discussed mass assignment attacks, and how they work on a Razor Pages application. I then showed how to avoid the attack, by creating a nested InputModel in your Razor Page, and only using BindProperty on this single type. This keeps your vulnerable surface-area very explicit, while not exposing other values that you might need to display the Razor view correctly (i.e. IsAdmin).
This approach is pretty standard for Razor Pages, but it wasn't as easy to fall into the pit of success for MVC. The overall design of Razor Pages helps to counteract the impediments, so if you haven't already, I strongly suggest trying them out.
Finally I discussed an issue that comes up a lot that conflates over-posting with more general authorization. These are two very different topics - you can still be vulnerable to over-posting even if you have authorization, and vice-versa. In general, resource-based authorization is a good approach for tackling this side-issue.
In this post, I show how to use the Link Tag Helper and Script Tag Helper in Razor with the asp-fallback attribute to serve files from a Content Delivery Network (CDN), falling back to local scripts if the CDN is unavailable.
Using a CDN with a fallback was the default approach in the ASP.NET Core templates for .NET Core 2.x, but in 3.x the templates were significantly simplified and now only serve from local files.
Using a CDN for common libraries
The first thing to discuss is why you might want to use a CDN for serving your application's client-side dependencies.
A CDN is just another server that hosts common files, often used for client-side assets like CSS stylesheets, JavaScript libraries, or images. Using a CDN can speed up your applications for several reasons:
CDNs are typically globally distributed, so can give very low latencies for downloading files, wherever in the world your users are. That can make a big difference if your application is only hosted in one region, and users are sending requests from the other side of the world!
It offloads network traffic from your servers, reducing the load on your server.
By sending requests for client-side assets to a CDN, you may see higher overall network throughput for your application. Browsers limit the number of simultaneous connections they make to a server (commonly 6). If you host your files on a CDN, the connections to the CDN don't count towards your server limit, leaving more connections to download in parallel from your app.
Other applications may have already downloaded common libraries from the CDN. If the file is already cached by the browser, it may not need to make a request at all, significantly speeding up your application.
If you need to include common libraries such as Bootstrap or jQuery, then it can make a lot of sense to serve these from a CDN. These libraries are publicly hosted on many different CDNs, so using any of the common ones can be a big win for your application's performance.
There are a couple of downsides or considerations when using CDNs
By using a CDN you're trusting them to deliver code to your user's browser. You need to be careful that if a CDN is compromised with malicious JavaScript, your website doesn't run it on your page. That can put both you and your users at risk.
If a CDN is unavailable, you should fallback to serving the scripts from your own website, as otherwise a CDN going down could break your application, as shown below.
I'm going to describe how to tackle that second point in this post, but the solutions will also cover the first point too. For more details on the security side, see this post by Scott Helme on adding a Content-Security Policy (CSP) to your application, and using Sub Resource Integrity (SRI) checks.
Whether you consider adding a fallback worthwhile will depend very much on the application you're building. Using a fallback adds complexity to your site that you may not need. The Tag Helper approach I show here also requires injecting inline-JavaScript, which may be at-odds with your CSP.
The current ASP.NET Core templates - no CDN for you
As part of the ASP.NET Core 3.x updates, the default templates were updated to use Bootstrap 4 (instead of version 3). They were also simplified significantly, and as part of that, CDN support was removed. If you look at the default _Layout.cshtml for a Razor Pages or MVC application in ASP.NET Core 3.0, you'll see something like the following (I've only kept the pertinent <link> and <script> tags in the example below):
<!DOCTYPE html><htmllang="en"><head><!-- other head tags --><linkrel="stylesheet"href="~/lib/bootstrap/dist/css/bootstrap.min.css"/><linkrel="stylesheet"href="~/css/site.css"/></head><body><!-- other body content -->
@RenderBody()
<!-- other body content --><scriptsrc="~/lib/jquery/dist/jquery.min.js"></script><scriptsrc="~/lib/bootstrap/dist/js/bootstrap.bundle.min.js"></script><scriptsrc="~/js/site.js"asp-append-version="true"></script>
@RenderSection("Scripts", required: false)
</body></html>
As you can see, the default layout references the following files:
bootstrap.min.css - The core Bootstrap CSS files. Version 4.3.1 as of .NET Core 3.1
site.css - The custom CSS for your website.
jquery.min.js - jQuery version 3.3.1 - required by Bootstrap.
bootstrap.bundle.min.js - The bootstrap jQuery plugins (bundled with Popper.js)
site.js - The custom JavaScript for your website.
In addition, for client-side validation you need to add the jQuery validation libraries. These are specified in the separate _ValidationScriptsPartial.cshtml file:
All these libraries are included in the default templates in the wwwroot/lib folders, but if you'd rather serve these files from a CDN, then you should consider keeping these files as a fallback.
Using fallback Tag Helpers to test for failed file loading from a CDN
The Link and Script Tag Helpers support the concept of configuring a fallback test for files loaded from a CDN. You can add asp-fallback-* attributes to a link, and the tag helper automatically generates some JavaScript to check if the file was downloaded from the CDN correctly.
For example, lets just take the first <link> from _layout.cshtml:
However, if the CDN is unavailable, your site will look very broken. You can provide a fallback for a CSS stylesheet link, by adding the following attributes:
asp-fallback-test-class - The CSS class to apply to a test element. Should be a class specified in the linked stylesheet, that won't exist otherwise.
asp-fallback-test-property - The CSS property to check on the test element.
asp-fallback-test-value - The value of the CSS property that the test element should have, if the linked stylesheet didn't load correctly.
asp-fallback-href - The URL of the file to load if the test fails.
For the Bootstrap example, you could apply the .sr-only class, and check that the position property has the value absolute using the following:
When it renders, this generates the following markup and inline JavaScript (the JavaScript is minified in practice, I've de-mangled and simplified it to make it a bit easier to understand below):
As you can see, that's a lot of extra JavaScript to check for a fallback. The version for <script> tags is a lot simpler. You just need two attributes for that:
asp-fallback-test - the JavaScript code to run that should evaluate to a "truthy" value if the script was loaded correctly.
asp-fallback-src - The URL of the file to load if the test fails.
The JavaScript generated is pretty simple - run the test, and if it fails, add a new <script> tag with the correct URL.
That gives us everything we need to update our layout files to use a CDN with a local falback.
Updating the templates to use a CDN with a fallback
I'll start with _Layout.cshtml first, from the start of this post.
<!DOCTYPE html><htmllang="en"><head><!-- other head tags --><environmentinclude="Development"><linkrel="stylesheet"href="~/lib/bootstrap/dist/css/bootstrap.css"/><linkrel="stylesheet"href="~/css/site.css"/></environment><environmentexclude="Development"><linkrel="stylesheet"href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css"asp-fallback-href="~/lib/bootstrap/dist/css/bootstrap.min.css"asp-fallback-test-class="sr-only"asp-fallback-test-property="position"asp-fallback-test-value="absolute"integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T"crossorigin="anonymous"/><linkrel="stylesheet"href="~/css/site.css"asp-append-version="true"/></environment></head><body><!-- other body content -->
@RenderBody()
<!-- other body content --><environmentinclude="Development"><scriptsrc="~/lib/jquery/dist/jquery.js"></script><scriptsrc="~/lib/bootstrap/dist/js/bootstrap.js"></script><scriptsrc="~/js/site.js"asp-append-version="true"></script></environment><environmentexclude="Development"><scriptsrc="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"asp-fallback-src="~/lib/jquery/dist/jquery.min.js"asp-fallback-test="window.jQuery"crossorigin="anonymous"integrity="sha384-tsQFqpEReu7ZLhBV2VZlAu7zcOV+rXbYlF2cqB8txI/8aZajjp4Bqd+V6D5IgvKT"></script><scriptsrc="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.bundle.min.js"asp-fallback-src="~/lib/bootstrap/dist/js/bootstrap.bundle.min.js"asp-fallback-test="window.jQuery && window.jQuery.fn && window.jQuery.fn.modal"crossorigin="anonymous"integrity="sha384-xrRywqdh3PHs8keKZN+8zzc5TX0GRTLCcmivcbNJWm2rs5C8PRhcEn3czEjhAO9o"></script><scriptsrc="~/js/site.js"asp-append-version="true"></script></environment>
@RenderSection("Scripts", required: false)
</body></html>
There's a lot in there, but here are the highlights:
Use the EnvironmentTagHelper to render the local files during development, and the CDN files in production
Use the recommended BootstrapCDN for bootstrap CSS and JS files, and the common cdnjs CDN for the jQuery files.
The easiest way to test that your fallback behaviour is working correctly, is to actively block the CDN files from loading. You can achieve that in Chrome or Edge by opening dev-tools (F12) and right-clicking the network file in question. From that you can choose "Block Request URL":
If you go through and block all the CDN URLs (or the domains) and reload the page, it should load fine. The blocked URLs are shown as blocked in the network tab, but the fallback tests wil fail, and use the local URLs instead:
Success!
There's one thing to watch out for though - for the integrity attribute to work correctly, the local file must be exactly the same as the CDN version. When I tested blocking CDN files initially, the fallback tests failed, but so did loading the local files:
SRI requires referenced files to be byte-for-byte identical. In my case, the local files used CRLF instead of the LF used in the CDN. I fixed it by overwriting the local files with the ones from the CDN, and ensuring that git preserved the LF, by adding this to the project .gitattributes file:
**/wwwroot/lib/** text eol=lf
That ensures that the files in wwwroot/lib are always checked-out with LF line endings, even on windows, and should help avoid SRI issues!
Summary
In this post I showed how you could update the default ASP.NET templates to load CSS stylesheets and JavaScript libraries from a CDN. I showed how to use Tag Helpers to add fallback tests, so that if the CDN is unreachable, then your library files will be loaded from the local files instead.
As part of the update, I added SRI hashes to ensure that if the CDN files are compromised (as has happened in several high-profile cases), your application will refuse to run the compromised files. With the fallbacks configured, your application will be protected and will continue to function. Win win!
I was seeing an issue recently where our application wasn't running the StopAsync method in our IHostedService implementations when the app was shutting down. It turns out that this was due to some services taking too long to respond to the shutdown signal. In this post I show an example of the problem, discuss why it happens, and how to avoid it.
StartAsync is called when the application is starting up. In ASP.NET Core 2.x this occurs just after the application starts handling requests, while in ASP.NET Core 3.x the hosted services are started just before the application starts handling requests.
StopAsync is called when the application receives the shut down (SIGTERM) signal, for example when you push CTRL+C in the console window, or the app is stopped by the host system. This allows you to close any open connections, dispose resources, and generally clean up your class as required.
In practice, there are actually some subtleties to implementing this interface that means that you typically want to derive from the helper class BackgroundService.
Problems shutting down an IHostedService implementation
The problem I saw recently was causing an OperationCanceledException to be thrown when the application was shutting down:
Unhandled exception. System.OperationCanceledException: The operation was canceled.
at System.Threading.CancellationToken.ThrowOperationCanceledException()
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
I traced the source of this problem to one particular IHostedService implementation. We use IHostedServices as the host for each of our Kafka consumers. The specifics of this aren't important - the key is just that shutting down the IHostedService is relatively slow: it can take several seconds to cancel the subscription.
Part of the problem is the way the Kafka library (and underlying librdkafka library) uses synchronous, blocking Consume calls, instead of async, cancellable calls. There's not a great way around that.
The easies way to understand this issue is with an example.
Demonstrating the problem
The easiest way to understand the problem is to create an application containing two IHostedService implementations:
NormalHostedService logs when it starts up and shuts down, then returns immediately.
SlowHostedService logs when it starts and stops, but takes 10s to complete shutdown
The implementations for these two classes are shown below. The NormalHostedService is very simple:
The IHostedServices I had in practice only took 1s to shutdown, but we had many of them, so the overall effect was the same as above!
The order the services are registered in ConfigureServices is important in this case - to demonstrate the issue, we need SlowHostedService to be shut down first. Services are shut down in reverse order, which means we need to register it last:
When we run the application, you'll see the starting logs as usual:
info: ExampleApp.NormalHostedService[0]
NormalHostedService started
info: ExampleApp.SlowHostedService[0]
SlowHostedService started
...
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
However, if you press CTRL+C to shut down the application, there's a problem. The SlowHostedService completes shutting down, but then an OperationCanceledException is thrown:
info: Microsoft.Hosting.Lifetime[0]
Application is shutting down...
info: ExampleApp.SlowHostedService[0]
SlowHostedService stopping...
info: ExampleApp.SlowHostedService[0]
SlowHostedService stopped
Unhandled exception. System.OperationCanceledException: The operation was canceled.
at System.Threading.CancellationToken.ThrowOperationCanceledException()
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.WaitForShutdownAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.Run(IHost host)
at ExampleApp.Program.Main(String[] args)in C:\repos\andrewlock\blog-examples\SlowShutdown\Program.cs:line 16
The NormalHostedService.StopAsync() method is never called. If the service needed to do some cleanup then you have a problem. For example, maybe you need to gracefully deregister the service from Consul, or unsubscribe from Kafka topics - that won't happen now.
So what's going on here? Where's that timeout coming from?
internalclassHost:IHost, IAsyncDisposable
{privatereadonlyHostOptions _options;private IEnumerable<IHostedService> _hostedServices;publicasyncTaskStopAsync(CancellationToken cancellationToken =default){// Create a cancellation token source that fires after ShutdownTimeout secondsusing(var cts =newCancellationTokenSource(_options.ShutdownTimeout))using(var linkedCts = CancellationTokenSource.CreateLinkedTokenSource(cts.Token, cancellationToken)){// Create a token, which is cancelled if the timer expiresvar token = linkedCts.Token;// Run StopAsync on each registered hosted serviceforeach(var hostedService in _hostedServices.Reverse()){// stop calling StopAsync if timer expires
token.ThrowIfCancellationRequested();try{await hostedService.StopAsync(token).ConfigureAwait(false);}catch(Exception ex){
exceptions.Add(ex);}}}// .. other stopping code}}
The key point here is the CancellationTokenSource that is configured to fire after HostOptions.ShutdownTimeout. By default, this fires after 5 seconds. That means hosted service shutdown is abandoned after 5s - shut down of all IHostedServices has to happen within this timeout.
On the first iteration of the foreach loop, the SlowHostedService.Stopasync() executes, which takes 10s to run. On the second iteration, the 5s timeout is exceeded, and so token.ThrowIfCancellationRequested(); throws an OperationConcelledException. That exits the control flow, and NormalHostedService.Stopasync() is never executed.
There's a simple solution to this - increase the shutdown timeout!
The solution: increase the shutdown timeout
HostOptions isn't explicitly configured anywhere by default, so you will need to configure it manually in your ConfigureSerices method. For example, the following config increases the timeout to 15s:
publicvoidConfigureServices(IServiceCollection services){
services.AddHostedService<NormalHostedService>();
services.AddHostedService<SlowShutdownHostedService>();// Configure the shutdown to 15s
services.Configure<HostOptions>(
opts => opts.ShutdownTimeout = TimeSpan.FromSeconds(15));}
Alternatively, you can also load the timeout from configuration. For example, if you add the following to appsettings.json:
{"HostOptions":{"ShutdownTimeout":"00:00:15"}
// other config
}
You can then bind the HostOptions configuration section to the HostOptions object:
publicclassStartup{publicIConfiguration Configuration {get;}publicStartup(IConfiguration configuration){
Configuration = configuration;}publicvoidConfigureServices(IServiceCollection services){
services.AddHostedService<NormalHostedService>();
services.AddHostedService<SlowShutdownHostedService>();// bind the config to host options
services.Configure<HostOptions>(Configuration.GetSection("HostOptions"));}}
This binds the serialised TimeSpan value 00:00:15 to the HostOptions value and sets the timeout to 15s. With that configuration, now when we stop the application, the services all shutdown correctly:
Your application will now wait up to 15s for all the hosted services to finish shutting down before exiting!
Summary
In this post I discussed an issue recently where our application wasn't running the StopAsync method in our IHostedService implementations when the app was shutting down. This was due to some background services taking too long to respond to the shutdown signal, and exceeding the shutdown timeout. I demonstrated the problem with a single service taking 10s to shutdown, but in practice it happens whenever the total shutdown time for all services exceeds the default 5s.
The solution to the problem was to extend the HostOptions.ShutdownTimeout configuration value to be longer than 5s, using the standard ASP.NET Core IOptions<T> configuration system.
ASP.NET Core 2.1 introduced the [ApiController] attribute which applies a number of common API-specific conventions to controllers. In ASP.NET Core 2.2 an extra convention was added - transforming error status codes (>= 400) to ProblemDetails.
Returning a consistent type, ProblemDetails, for all errors makes it much easier for consuming clients. All errors from MVC controllers, whether they're a 400 (Bad Request) or a 404 (Not Found), return a ProblemDetails object:
However, if your application throws an exception, you don't get a ProblemDetails response:
In the default webapi template (shown below), the developer exception page handles errors in the Development environment, producing the error above.
publicclassStartup{publicvoidConfigureServices(IServiceCollection services){
services.AddControllers();}publicvoidConfigure(IApplicationBuilder app,IWebHostEnvironment env){// Only add error handling in development environmentsif(env.IsDevelopment()){
app.UseDeveloperExceptionPage();}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{
endpoints.MapControllers();});}}
In the production environment, there's no exception middleware registered so you get a "raw" 500 status code without a message body at all:
A better option would be to consistent, and return a ProblemDetails object for exceptions too. One way to achieve this would be to create a custom error handler, as I described in a previous post. A better option is to use an existing NuGet package that handles it for you.
ProblemDetailsMiddleware
The ProblemDetailsMiddleware from Kristian Hellang does exactly what you expect - it handles exceptions in your middleware pipeline, and converts them to ProblemDetails. It has a lot of configuration options (which I'll get to later), but out of the box it does exactly what we need.
Add the Hellang.Middleware.ProblemDetails to your .csproj file, by calling dotnet add package Hellang.Middleware.ProblemDetails. The latest version at the time of writing is 5.0.0:
You need to add the required services to the DI container by calling AddProblemDetails(). Add the middleware itself to the pipeline by calling UseProblemDetails. You should add this early in the pipeline, to ensure it catches errors from any subsequent middleware:
publicclassStartup{publicvoidConfigureServices(IServiceCollection services){
services.AddControllers();
services.AddProblemDetails();// Add the required services}publicvoidConfigure(IApplicationBuilder app,IWebHostEnvironment env){
app.UseProblemDetails();// Add the middleware
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{
endpoints.MapControllers();});}}
With this simple addition, if you get an exception somewhere in the pipeline (in a controller for example), you'll still get a ProblemDetails response. In the Development environment, the middleware includes the exception details and the Stack Trace:
This is more than just calling ToString() on the Exception though - the response even includes the line that threw the exception (contextCode) and includes the source code before (preContextCode) and after (postContextCode) the offending lines:
In the Production environment, the middleware doesn't include these details for obvious reasons, and instead returns the basic ProblemDetails object only.
As well as handling exceptions, the ProblemDetailsMiddleware also catches status code errors that come from other middleware too. For example, if a request doesn't match any endpoints in your application, the pipeline will return a 404. The ApiController attribute won't catch that, so it won't be converted to a ProblemDetails object.
Similarly, by default, if you send a POST request to a GET method, you'll get a 405 response, again without a method body, even if you apply the [ApiController] attribute:
With the ProblemDetailsMiddleware in place, you get a ProblemDetails response for these error codes too:
This behaviour gave exactly what I needed out-of-the-box, but you can also extensively customise the behaviour of the middleware if you need to. In the next section, I'll show some of these customization options.
Customising the middleware behaviour
You can customise the behaviour of the ProblemDetailsMiddleware by providing a configuration lambda for an ProblemDetailsOptions instance in the AddProblemDetails call:
There's lots of possible configuration settings, as shown below. Most of the configuration settings are Func<> properties, that give access to the current HttpContext, and let you control how the middleware behaves.
For example, by default, ExceptionDetails are included only for the Development environment. If you wanted to include the details in the Staging environment too, you could use something like the following:
publicvoidConfigureServices(IServiceCollection services){
services.AddControllers();
services.AddProblemDetails(opts =>{// Control when an exception is included
opts.IncludeExceptionDetails =(ctx, ex)=>{// Fetch services from HttpContext.RequestServicesvar env = ctx.RequestServices.GetRequiredService<IHostEnvironment>();return env.IsDevelopment()|| env.IsStaging();};});}
Another thing worth pointing out is that you can control when the middleware should convert non-exception responses to ProblemDetails. The default configuration converts non-exception responses to ProblemDetails when the following is true:
The status code is between 400 and 600.
The Content-Length header is empty.
The Content-Type header is empty.
As I mentioned at the start of this post, the [ApiController] attribute from ASP.NET Core 2.2 onwards automatically converts "raw" status code results into ProblemDetails anyway. Those responses are ignored by the middleware, as the response will already have a Content-Type.
However, if you're not using the [ApiController] attribute, or are still using ASP.NET Core 2.1, then you can use the ProblemDetailsMiddleware to automatically convert raw status code results into ProblemDetails, just as you get in ASP.NET Core 2.2+.
The responses in these cases aren't identical, but they're very similar. There are small differences in the values used for the Title and Type properties for example.
Another option would be to use the ProblemDetailsMiddleware in an application that combines Razor Pages with API controllers. You could then use the IsProblem function to ensure that ProblemDetails are only generated for API controller endpoints.
I've only touched on a couple of the customisation features, but there's lots of additional hooks you can use to control how the middleware works. I just haven't had to use them, as the defaults do exactly what I need!
Summary
In this post I described the ProblemDetailsMiddleware by Kristian Hellang, that can be used with API projects to generate ProblemDetails results for exceptions. This is a very handy library if you're building APIs, as it ensures all errors return a consistent object. The project is open source on GitHub, and available on NuGet, so check it out!
If you don't know what strongly typed IDs are about, I suggest reading the previous posts in this series. In summary, strongly-typed IDs help avoid bugs introduced by using primitive types for entity identifiers. For example, imagine you have a method signature like the following:
The call above accidentally inverts the order of orderId and userId when calling the method. Unfortunately, the type system doesn't help us here because both IDs are using the same type, Guid.
Strongly Typed IDs allow you to avoid these types of bugs entirely, by using different types for the entity IDs, and using the type system to best effect. This is something that's easy to achieve in some languages (e.g. F#), but is a bit of a mess in C# (at least until we get record types in C# 9!):
publicreadonlystruct OrderId : IComparable<OrderId>, IEquatable<OrderId>{publicGuid Value {get;}publicOrderId(Guidvalue){
Value =value;}publicstaticOrderIdNew()=>newOrderId(Guid.NewGuid());publicboolEquals(OrderId other)=>this.Value.Equals(other.Value);publicintCompareTo(OrderId other)=> Value.CompareTo(other.Value);publicoverrideboolEquals(object obj){if(ReferenceEquals(null, obj))returnfalse;return obj isOrderId other &&Equals(other);}publicoverrideintGetHashCode()=> Value.GetHashCode();publicoverridestringToString()=> Value.ToString();publicstaticbooloperator==(OrderId a,OrderId b)=> a.CompareTo(b)==0;publicstaticbooloperator!=(OrderId a,OrderId b)=>!(a == b);}
On top of that, the StronglyTypedId package uses Roslyn to auto generate the additional code whenever you save a file. No need for snippets, full IntelliSense, but all the benefits of strongly-typed IDs!
So that's the background, now lets look at some of the updates
Recent updates
These updates are primarily courtesy of Bartłomiej Oryszak who did great work! There are primarily three updates:
Support creating JSON converters for System.Text.Json
Support for using long as a backing type for the strongly typed ID
Support for .NET Core 3.x
StronglyTypedId has now been updated to the latest version of CodeGeneration.Roslyn to support for .NET Core 3.x. This brings updates to the Roslyn build tooling, which makes the library much easier to consume. You can add a single <PackageReference> in your project.
Setting PrivateAssets=all prevents the CodeGeneration.Roslyn.Attributes and StronglyTypedId.Attributes from being published to the output. There's no harm in them being there, but they're only used at compile time!
With the package added, you can now add the [StronglyTypedId] to your IDs:
This will generate a Guid-backed ID, with a TypeConverter, without any JSON converters. If you do want explicit JSON converters, you have another option—System.Text.Json converters.
Support for System.Text.Json converters
StronglyTypedId has always supported the Newtonsoft.JsonJsonConverter but now you have another option, System.Text.Json. You can generate this converter by passing an appropriate StronglyTypedIdJsonConverter value:
Remember, if you generate a Newtonsoft.Json converter, you'll need to add a reference to the project file.
Support for long as a backing type
The final update is adding support for using long as the backing field for your strongly typed IDs. To use long, use the StronglyTypedIdBackingType.Long option:
C# 9 is bringing some interesting features, most notably source generators and record types. Both of these features have the potential to impact the StronglyTypedId package in different ways.
Source generators are designed for exactly the sort of functionality StronglyTypedId provides - build time enhancement of existing types. From a usage point of view, as far as I can tell, converting to using source generators would provide essentially the exact same experience as you can get now with CodeGeneration.Roslyn. For that reason, it doesn't really seem worth the effort looking into at this point, unless I've missed something!
Record types on the other hand are much more interesting. Records provide exactly the experience we're looking for here! With the exception of the built-in TypeConverter and JsonConverters, records seem like they would give an overall better experience out of the box. So when C#9 drops, I think this library can probably be safely retired 🙂
Summary
In this post I described some recent enhancements to the StronglyTypedId NuGet package, which lets you generate strongly-typed IDs at compile time. The updates simplify using the StronglyTypedId package in your app by supporting .NET Core 3.x, added support for System.Text.Json as a JsonConverter, and using long as a backing field. If you have any issues using the package, let me know in the issues on GitHub, or in the comments below.
ASP.NET Core Identity includes a default UI as a Razor library that enables you to quickly add users to an application, without having to build all the UI yourself. The downside is that if you want to customise any of the pages associated with the default UI, then you end up taking ownership of all the logic too. Even if all you want to do is add a CSS class to an element, you're stuck maintaining the underlying page handler logic too.
In this post I show how you can replace the Razor views for the default UI, without taking ownership of the business logic stored in the Razor Page PageModel code-behind files. I show how you can use the ASP.NET Core Identity scaffolder to generate the replacement Razor Pages initially, but customise these to use the existing, default, PageModels.
Background: ASP.NET Core Identity
ASP.NET Core Identity is a series of services that provide functionality for managing and signing in users. You can use the Identity services to (among other things):
Create users, and provide sign-in functionality
Secure passwords using best practice, strong, hashing algorithms
The Identity services provide APIs for achieving all these things, but you still have to arrange them all in the right order. You also have to write the UI that users use to interact with the services. Obviously, that's a huge investment, and is working with sensitive data, so you have to be very careful not to introduce any security holes.
Prior to ASP.NET Core 2.1, your best bet for implementing this was to use the UI generated from the Visual Studio templates. Unfortunately, using templates means that your UI is fine initially, but you then have a lot of code to maintain. If a bug is found in the templates, you have to go and update it yourself. What are the chances of people doing that? Slim to none I'd wager.
Luckily, ASP.NET Core 2.1 introduced a default UI Razor Class Library that meant you could benefit from the same UI, without having dozens of Razor Pages in your application to maintain. If a bug is found in the UI, the NuGet package can be updated, and you seamlessly get the bug fix, and all is great.
Customising the default UI
Of course, using the default UI means: you have to use the default UI. I think it's generally unlikely that users will want to use the default UI in its entirety, unless you're building internal apps only, or creating a "throwaway" app. For a start, the login and register pages include references to developer documentation that most people will want to remove:
Even though the UI is contained in a Razor Class Library, you can "overwrite" individual pages, by placing your own Razor Pages in a "magic" location in your project. For example, to override the register page, you can create a Razor Page at Areas/Identity/Pages/Register.cshtml:
A valid concern would be "how do I know which pages I can override?". Luckily there's a .NET Core tool you can use to scaffold pages from Identity in the correct locations, along with supporting files.
Scaffolding Identity files with the .NET CLI
The documentation for scaffolding Identity pages is excellent, so I'll just run through the basics with the .NET CLI here. You can also use Visual Studio, but be sure to follow steps 1-3 below, otherwise you get weird random errors when running the scaffolder.
Add all the required packages to your application. If you're already using EF Core in your app, then you may already have some of these, but make sure they're all there, as missing packages can cause frustrating errors locally
Also make sure that the installed package versions match your project version, for example .NET Core 3.1 projects should use packages starting 3.1.x.
Confirm your project builds without errors. If it doesn't you'll get errors when scaffolding files.
Install the code generator tool globally using dotnet tool install -g dotnet-aspnet-codegenerator. Alternatively, you could install it as a local tool instead.
Run dotnet aspnet-codegenerator identity -lf from the project folder (not the solution folder), to see the list of files you can scaffold:
> dotnet aspnet-codegenerator identity -lf
Building project ...
Finding the generator 'identity'...
Running the generator 'identity'...
File List:
Account._StatusMessage
Account.AccessDenied
Account.ConfirmEmail
Account.ConfirmEmailChange
Account.ExternalLogin
Account.ForgotPassword
Account.ForgotPasswordConfirmation
Account.Lockout
... 25 more not shown!
In this case, I'm going to scaffold the Account.Register page, and remove the external login provider section completely.
You can create a Razor Pages app using the default UI by running dotnet new webapp -au Individual -uld
If you're scaffolding into a project that's configured to use the default UI, you will already have an EF Core IdentityDbContext in your application. Pass the fully namespaced name of the context in the following command, using the -dc switch, when scaffolding your files:
After running this command, you'll find a bunch more files in the Areas/Identity folder:
The generated pages override the equivalents in the default UI package, so any changes you make to Register.cshtml will be reflected in your app. For example, I can delete the external login provider section entirely:
The downside is that I'm now maintaining the code-behind file Register.cshtml.cs. That's 100 lines of code I'd rather not be maintaining, as I haven't changed it from the default…
Remove your liabilities - deleting the scaffolded PageModel
I don't want that code, so I'm just going to delete it! As I'm only going to make changes to the Razor views, I can delete the following files:
Areas/Identity/Pages/Account/Register.cshtml.cs — this is the PageModel implementation I don't want to have to maintain
Areas/Identity/Pages/Account/ViewImports.cshtml — No longer necessary, as there's nothing in the namespace it specifies now
Areas/Identity/Pages/_ValidationScriptsPartial.cshtml — A duplicate of the version included in the default UI. No need to override it
Areas/Identity/Pages/IdentityHostingStartup.cs — Doesn't actually configure anything, so can be deleted
Additionally, you can update Areas/Identity/Pages/ViewImports.cshtml to remove the project-specific namespaces, to leave just the following:
At this point, your app won't compile. The Register.cshtml page will complain that you've specified a now non-existent RegisterModel as the PageModel for the Razor Page:
The final step is to update the @page directive to point to the originalRegisterModel that's included with the default Identity UI, referenced in full in the example below:
This is the magic step. Your application will now compile, use your custom Razor views, but use the original Razor Pages PageModels that are part of the default UI! That's much less code to maintain, and less chance to screw something up in your Identity pages
What are the downsides?
So what are the downsides of this approach? The only one I can really think of is that you're very tightly tied to the PageModels in the original Identity UI, so you have to be sure that any updates that are made to the Identity UI are reflected in your Razor Page templates as appropriate. The big advantage is that if the default UI package is updated and it doesn't make any breaking changes to the Razor templates, then you get the updates with no friction at all.
Another danger is that the inability to customise the PageModelmay encourage you to do slightly janky things like @inject-ing services into the Razor views that shouldn't be there, and adding additional logic into the Razor views. I'm not suggesting you should do this. If you _do_ need to change the behaviour of the page handlers, then you should just go ahead and take ownership of that code. The point is that this technique is useful when you don't need to change the page handler logic.
Summary
In this post I gave some background on ASP.NET Core Identity and the default UI Razor Class Library that provides over 30 Razor Pages "for free". I then showed how you could use the scaffolder tool to override one of these pages when you want to change the Razor template.
The downside of this default approach is that you now have to maintain the page handlers for the scaffolded pages. That's 100s of lines of code per page that you must keep up to date when a new package version is released.
I showed how you can avoid that burden by deleting the scaffolded PageModel file, and point your Razor template to the originalPageModel that comes as part of the default UI. This lets you update your Razor templates without having to take ownership of the page handler logic, potentially giving you the best of both worlds.
ASP.NET Core has an extensive authorization system that you can use to create complex authorization policies. In this post, I look at the various ways you can apply these policies to large sections of your application.
We'll start by configuring a global AuthorizeFilter and see why that's no longer the recommended approach in ASP.NET Core 3.0+. We'll then look at the alternative, using endpoint routing, as well as using Razor Page conventions to apply different authorization policies to different parts of your app. We'll also compare the DefaultPolicy to the FallbackPolicy see when each of them are applied, and how you can update them.
For the purposes of this post, I'll assume you have a standard Razor Pages application, with a Startup.cs something like the following. The details of this aren't very important, I just assume you have already configured authentication and a UI system for your application.
publicclassStartup{publicIConfiguration Configuration {get;}publicStartup(IConfiguration configuration){
Configuration = configuration;}publicvoidConfigureServices(IServiceCollection services){// Configure ASP.NET Core Identity + EF Core
services.AddDbContext<AppDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
services.AddDefaultIdentity<IdentityUser>().AddEntityFrameworkStores<AppDbContext>();// Add Razor Pages services
services.AddRazorPages();// Add base authorization services
services.AddAuthorization();}publicvoidConfigure(IApplicationBuilder app){
app.UseStaticFiles();// Ensure the following middleware are in the order shown
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{// Add Razor Pages to the application
endpoints.MapRazorPages();});}}
At this point, you have authentication, and you want to start protecting your application. You could apply [Authorize] attributes to every Razor Page, but you want to be a bit safer, and apply authorization globally, to all the pages in your application. For the rest of this post, we look at the various options available.
Globally applying an AuthorizeFilter
The first option is to apply an AuthorizeFilter globally to all your MVC actions and Razor Pages. This is the approach traditionally used in earlier versions of ASP.NET Core.
For example, you can add an AuthorizeFilter to all your Razor Page actions when configuring your Razor Pages in ConfigureServices (you can configure MVC controllers in a similar way):
publicvoidConfigureServices(IServiceCollection services){// ...other config as before// Add a default AuthorizeFilter to all endpoints
services.AddRazorPages().AddMvcOptions(options => options.Filters.Add(newAuthorizeFilter()));}
This is equivalent to decorating all your Razor Pages with an [Authorize] attribute, so users are authorized using the DefaultPolicy (more on that shortly!), which by default just requires an authenticated user. If you're not authenticated, you'll be redirected to the login page for Razor Pages apps (you'll receive a 401 response for APIs).
If you want to apply a different policy, you can specify one in the constructor of the AuthorizeFilter:
publicvoidConfigureServices(IServiceCollection services){// ...other config as before// Pass a policy in the constructor of the Authorization filter
services.AddRazorPages().AddMvcOptions(options => options.Filters.Add(newAuthorizeFilter("MyCustomPolicy")));// Configure the custom policy
services.AddAuthorization(options =>{
options.AddPolicy("MyCustomPolicy",
policyBuilder => policyBuilder.RequireClaim("SomeClaim"));});}
The authorization filter is still applied globally, so users will always be required to login, but now they must also satisfy the "MyCustomPolicy" policy. If they don't, they'll be redirected to an access denied page for Razor Pages apps (or receive a 403 for APIs).
Remember, this policy applies globally so you need to ensure your "Login" and "AccessDenied" pages are decorated with [AllowAnonymous], otherwise you'll end up with endless redirects.
Applying AuthorizeFilters like this was the standard approach for early versions of ASP.NET Core, but ASP.NET Core 3.0 introduced endpoint routing. Endpoint routing allows moving some previously-MVC-only features to being first-class citizens. Authorization is one of those features!
Using RequireAuthorization on endpoint definitions
The big problem with the AuthorizeFilter approach is that it's an MVC-only feature. ASP.NET Core 3.0+ provides a different mechanism for setting authorization on endpoints—the RequireAuthorization() extension method on IEndpointConventionBuilder.
Instead of configuring a global AuthorizeFilter, call RequireAuthorization() when configuring the endpoints of your application, in Configure():
publicvoidConfigureServices(IServiceCollection services){// ...other config as before// No need to add extra filters
services.AddRazorPages();// Default authorization services
services.AddAuthorization();}publicvoidConfigure(IApplicationBuilder app){
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{// Require Authorization for all your Razor Pages
endpoints.MapRazorPages().RequireAuthorization();});}
The net effect of this is the same as applying a global AuthorizeFilter. So why use this approach? One big advantage is the ability to add authorization for other endpoints, that aren't MVC or Razor Pages. For example, you could require authenticated requests for your health check endpoints:
app.UseEndpoints(endpoints =>{// Require Authorization for all your Razor Pages
endpoints.MapRazorPages().RequireAuthorization();// Also require authorization for your health check endpoints
endpoints.MapHealthChecks("/healthz").RequireAuthorization();});
As before, you can specify a different policy to apply in the call to RequireAuthorization(). You could also provide different policies to apply for different endpoints. In the example below I'm applying the "MyCustomPolicy" policy to the Razor Pages endpoints, and two policies, "OtherPolicy" and "MainPolicy" to the health check endpoints:
app.UseEndpoints(endpoints =>{// Require Authorization for all your Razor Pages
endpoints.MapRazorPages().RequireAuthorization("MyCustomPolicy");// Also require authorization for your health check endpoints
endpoints.MapHealthChecks("/healthz").RequireAuthorization("OtherPolicy","MainPolicy");});
As always, ensure you've registered the policies in the call to AddAuthorization(), and ensure your added [AllowAnonymous] to your Login Access Denied pages.
If you don't provide a policy name in the RequireAuthorization() call, then the DefaultPolicy is applied. This is the same behaviour as using an [Authorize] filter without a policy name.
Changing the DefaultPolicy for an application
The DefaultPolicy is the policy that is applied when:
You specify that authorization is required, either using RequireAuthorization(), by applying an AuthorizeFilter, or by using the [Authorize] attribute on your actions/Razor Pages.
You don't specify which policy to use.
Out-of-the-box, the DefaultPolicy is configured as the following:
That means if you're authenticated, then you're authorized. This provides the default behaviour that you're likely familiar with, of redirecting unauthenticated users to the login page, but allowing any authenticated user access to the page.
You can change the DefaultPolicy so that an empty [Authorize] attribute applies a different policy in UseAuthorization(). For example, the following sets the DefaultPolicy to a policy that requires users have the Claim "SomeClaim".
publicvoidConfigureServices(IServiceCollection services){// ...other config as before
services.AddRazorPages();
services.AddAuthorization(options =>{// Configure the default policy
options.DefaultPolicy =newAuthorizationPolicyBuilder().RequireClaim("SomeClaim").Build();// ...other policy configuration});}publicvoidConfigure(IApplicationBuilder app){
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{// The default policy applies here, as no other policy set
endpoints.MapRazorPages().RequireAuthorization();// DefaultPolicy not used, as OtherPolicy is provided
endpoints.MapHealthChecks("/healthz").RequireAuthorization("OtherPolicy");// DefaultPolicy not applied, as authorization not required
endpoints.MapHealthChecks("/ready");});}
The example above shows when the DefaultPolicy is applied, and when it isn't. The DefaultPolicy only applies when you've request authorization and you haven't specified a different policy. So it only applies to the Razor Pages endpoints in the example above.
Applying a default policy like this can be very useful, but sometimes you want to have slightly more granular control over when to apply policies. In Razor Pages applications for example, you might want to apply a given policy to one folder, and a different policy to another folder or area. You can achieve that using Razor Pages conventions.
Applying authorization policies using conventions with Razor Pages
The Razor Pages framework is designed around a whole set of conventions that are designed to make it easy to quickly build applications. However, you can customise virtually all of those conventions when your app starts, and authorization is no different.
The Razor Page conventions allow you to set authorization requirements based on a folder, area, or page. They also allow you to mark sections and pages with AllowAnonymous in situations where you need to "punch a hole" through the default authorization policy. The documentation on this feature is excellent, so I've just provided a brief example below:
publicvoidConfigureServices(IServiceCollection services){// ...other config as before// Applying multiple conventions
services.AddRazorPages(options =>{// These apply authorization policies to various folders and pages
options.Conventions.AuthorizeAreaFolder("Users","/Accounts");
options.Conventions.AuthorizePage("/ChangePassword");// You can provide the policy as an optional parameter, otherwise the DefaultPolicy is used
options.Conventions.AuthorizeFolder("/Management","MyCustomPolicy");// You can also configure [AllowAnonymous] for pages/folders/areas
options.Conventions.AllowAnonymousToAreaPage("Identity","/Account/AccessDenied");});
services.AddAuthorization(options =>{// ...other policy configuration});}
These conventions can be useful for broadly applying authorization policies to whole sections of your application. But what if you just want to apply authorization everywhere? That's where the FallbackPolicy comes in.
Using the FallbackPolicy to authorize everything
The FallbackPolicy is applied when the following is true:
The endpoint does not have any authorisation applied. No [Authorize] attribute, no RequireAuthorization, nothing.
The endpoint does not have an [AllowAnonymous] applied, either explicitly or using conventions.
So the FallbackPolicy only applies if you don't apply any other sort of authorization policy, including the DefaultPolicy, When that's true, the FallbackPolicy is used.
By default, the FallbackPolicy is a no-op; it allows all requests without authorization. You can change the FallbackPolicy in the same way as the DefaultPolicy, in UseAuthorization:
publicvoidConfigureServices(IServiceCollection services){// ...other config as before
services.AddRazorPages();
services.AddAuthorization(options =>{// Configure the default policy
options.FallbackPolicy =newAuthorizationPolicyBuilder().RequireClaim("SomeClaim").Build();// ...other policy configuration});}publicvoidConfigure(IApplicationBuilder app){
app.UseStaticFiles();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{// The FallbackPolicy applies here, as no other policy set
endpoints.MapRazorPages()// FallbackPolicy not used, as authorization applied
endpoints.MapHealthChecks("/healthz").RequireAuthorization("OtherPolicy");// FallbackPolicy not used, as DefaultPolicy applied
endpoints.MapHealthChecks("/ready").RequireAuthorization();});}
In the example above, the FallbackPolicy is set to a custom policy. It only applies to the Razor Pages endpoints, as the health check endpoints have specified authorization requirements of "OtherPolicy" and the DefaultPolicy.
With the combination of the DefaultPolicy, FallbackPolicy, Razor Page conventions, and the RequireAuthorization() extension method, you have multiple ways to apply authorization "globally" in your application. Remember that you can always override the DefaultPolicy and FallbackPolicy to achieve a more specific behaviour by applying an [Authorize] or [AllowAnonymous] attribute directly to a Razor Page or action method.
Summary
In this post I described the various options available for setting global authorization policies:
Apply an AuthorizeFilter globally. This is no longer the recommended approach, as it is limited to MVC/Razor Pages endpoints.
Call RequireAuthorization() when configuring an endpoint in UseEndpoints(). You can specify a policy to apply, or leave blank to apply the DefaultPolicy.
Apply authorization to Razor Pages using conventions when you call AddRazorPages(). You can apply authorization policies and[AllowAnonymous] using these conventions.
The DefaultPolicy is applied when you specify that authorization is required, but don't specify a policy to apply. By default, the DefaultPolicy authorizes all authenticated users.
The FallbackPolicy is applied when no authorization requirements are specified, including the [Authorize] attribute or equivalent. By default, the FallbackPolicy does not apply any authorization.
Host filtering, restricting the hostnames that your app responds to, is recommended whenever you're running in production for security reasons. In this post, I describe how to add host filtering to an ASP.NET Core application.
What is host filtering?
When you run an ASP.NET Core application using Kestrel, you can choose the ports it binds to, as I described in a previous post. You have a few options:
Bind to a port on the loopback (localhost) address
Bind to a port on a specific IP address
Bind to a port on any IP address on the machine.
Note that we didn't mention a hostname (e.g. example.org) at any point here - and that's because Kestrel doesn't bind to a specific host name, it just listens on a given port.
DNS is used to convert the hostname you type in your address bar to an IP address, and typically port 80, or (443 for HTTPS). You can simulate configuring DNS with a provider locally be editing the hosts file on your local machine, as I'll show in the remainder of this section
On Linux, you can run sudo nano /etc/hosts to edit the hosts file. On Windows, open an administrative command prompt, and run notepad C:\Windows\System32\drivers\etc\hosts. At the bottom of the file, add entries for site-a.local and site-b.local that point to your local machine:
# Other existing configuration# For example:## 102.54.94.97 rhino.acme.com # source server# 38.25.63.10 x.acme.com # x client host
127.0.0.1 site-a.local
127.0.0.1 site-b.local
Now create a simple ASP.NET Core app, for example using dotnet new webapi. By default, if you run dotnet run, your application will listen on ports 5000 (HTTP) and 5001 (HTTPS), on all IP addresses. If you navigate to https://localhost:5001/weatherforecast, you'll see the results from the standard default WeatherForecastController.
Thanks to your additions to the hosts file, you can now also access the site at site-a.local and site-b.local, for example, https://site-a.local:5001/weatherforecast:
You'll need to click through some SSL warnings to view the example above, as the development SSL is only valid for localhost, not our custom domain.
By default, there's no host filtering, so you can access the ASP.NET Core app via localhost, or any other hostname that maps to your IP address, such as our custom site-a.local domain. But why does that matter?
Why should you use host filtering?
The Microsoft documentation points out that you should use host filtering for a couple of reasons:
The latter two attacks essentially rely on an application "echoing" the hostname used to access the website when generating URLs.
You can easily see this vulnerability in an ASP.NET Core app if you generate an absolute URL, for use in a password reset email for example. As a simple example, consider the controller below: this generates an absolute link to the WeatherForecast action (shown in the previous image):
Specifying the protocol means an absolute URL is generated instead of a relative link. There are various other methods that generate absolute links, as well as others on the LinkGenerator.
Depending on the hostname you access the site with, a different link is generated. By leveraging "forgot your password" functionality, an attacker could send an email from your system to any of your users with a link to a malicious domain under the attacker's control!
Hopefully we can all agree that's bad… luckily the fix isn't hard.
Enabling host filtering for Kestrel
Host filtering is added by default in the ConfigureWebHostDefaults() method, but it's disabled by default. If you're using this method, you can enable the middleware by setting the "AllowedHosts" value in the app's IConfiguration.
In the default templates, this value is set to * in appsettings.json, which disables the middleware. To add host filtering, add a semicolon delimited list of hostnames:
{"AllowedHosts":"site-a.local;localhost"}
You can set the configuration value using any enabled configuration provider, for example using an environment variable.
With this value set, you can still access the allowed host names, but all other requests to other hosts will return a 400 response, stating the hostname is invalid:
If you're not using the ConfigureWebHostDefaults() method, you need to configure the HostFilteringOptions yourself, and add the HostFilteringMiddleware manually to your middleware pipeline. You can configure these in Startup.ConfigureServices(). For example, the following uses the "AllowedHosts" configuration setting, in a similar way to the defaults:
publicclassStartup{publicStartup(IConfiguration configuration){
Configuration = configuration;}publicvoidConfigureServices(IServiceCollection services){// ..other config// "AllowedHosts": "localhost;127.0.0.1;[::1]"var hosts = Configuration["AllowedHosts"]?.Split(new[]{';'}, StringSplitOptions.RemoveEmptyEntries);if(hosts?.Length >0){
services.Configure<HostFilteringOptions>(
options => options.AllowedHosts = hosts;}}publicvoidConfigure(IApplicationBuilder app){// Should be first in the pipeline
app.UseHostFiltering();// .. other config}}
This is very similar to the default configuration used by ConfigureWebHostDefaults(), though it doesn't allow changing the configured hosts at runtime. See the default implementation if that's something you need.
The default configuration uses an IStartupFilter, HostFilteringStartupFilter, to add the hosting middleware, but it's internal, so you'll have to make do with the approach above.
Host filtering is especially important when you're running Kestrel on the edge, without a reverse proxy, as in most cases a reverse proxy will manage the host filtering for you. Depending on the reverse proxy you use, you may need to set the ForwardedHeadersOptions.AllowedHosts value, to restrict the allowed values of the X-Forwarded-Host header. You can read more about configuring the forwarded headers and a reverse proxy in the documentation.
Summary
In this post I described Kestrel's default behaviour, of binding to a port not a domain. I then showed how this behaviour can be used as an attack vector by generating malicious links, if you don't filter requests to only a limited number of hosts. Finally, I showed how to enable host filtering by setting the AllowedHosts value in configuration, or by manually adding the HostFilteringMiddleware.
The Manning Early Access Program (MEAP) has started for the second edition of my book ASP.NET Core in Action, Second Edition. This post gives you a sample of what you can find in the book. If you like what you see, please take a look - for now you can even get a 40% discount with the code bllock2. On top of that, you'll also get a copy of the first edition, free!
The Manning Early Access Program provides you full access to books as they are written, You get the chapters as they are produced, plus the finished eBook as soon as it’s ready, and the paper book long before it's in bookstores. You can also interact with the author (me!) on the forums to provide feedback as the book is being written.
When to choose ASP.NET Core
This article assumes that you have a general grasp of what ASP.NET Core is and how it was designed. You might be wondering: should you use it? Microsoft is recommending that all new .NET web development should use ASP.NET Core, but switching to or learning a new web stack is a big ask for any developer or company. In this article I cover:
What sort of applications you can build with ASP.NET Core
Some of the highlights of ASP.NET Core
Why you should consider using ASP.NET Core for new applications
Things to consider before converting existing ASP.NET applications to ASP.NET Core
What type of applications can you build?
ASP.NET Core provides a generalized web framework that can be used for a variety of applications. It can most obviously be used for building rich, dynamic websites, whether they’re e-commerce sites, content-based sites, or large n-tier applications—much the same as the previous version of ASP.NET.
When .NET Core was originally released, there were few third-party libraries available for building these types of complex applications. After several years of active development, that’s no longer the case. Many developers have updated their libraries to work with ASP.NET Core, and many other libraries have been created to target ASP.NET Core specifically. For example, the open source content management system (CMS), Orchard has been redeveloped as Orchard Core to run on ASP.NET Core. In contrast, the cloudscribe CMS project (figure 1) was written specifically for ASP.NET Core from its inception.
Figure 1. The .NET Foundation website (https://dotnetfoundation.org/) is build using the cloudscribe CMS and ASP.NET Core
Traditional, page-based server-side-rendered web applications are the bread and butter of ASP.NET development, both with the previous version of ASP.NET and with ASP.NET Core. Additionally, single-page applications (SPAs), which use a client-side framework that commonly talks to a REST server, are easy to create with ASP.NET Core. Whether you’re using Angular, Vue, React, or some other client-side framework, it’s easy to create an ASP.NET Core application to act as the server-side API.
DEFINITION REST stands for Representational State Transfer. RESTful applications typically use lightweight and stateless HTTP calls to read, post (create/update), and delete data.
ASP.NET Core isn’t restricted to creating RESTful services. It’s easy to create a web service or remote procedure call (RPC)-style service for your application, depending on your requirements, as shown in figure 2. In the simplest case, your application might expose only a single endpoint, narrowing its scope to become a microservice. ASP.NET Core is perfectly designed for building simple services thanks to its cross-platform support and lightweight design.
Figure 2. ASP.NET Core can act as the server-side application for a variety of different clients: it can serve HTML pages for traditional web applications, it can act as a REST API for client-side SPA applications, or it can act as an ad-hoc RPC service for client applications.
You should consider multiple factors when choosing a platform, not all of which are technical. One such factor is the level of support you can expect to receive from its creators. For some organizations, this can be one of the main obstacles to adopting open source software. Luckily, Microsoft has pledged to provide full support for Long Term Support (LTS) versions of .NET Core and ASP.NET Core for at least three years from the time of their release. And as all development takes place in the open, you can sometimes get answers to your questions from the general community, as well as from Microsoft directly.
When deciding whether to use ASP.NET Core, you have two primary dimensions to consider: whether you’re already a .NET developer, and whether you’re creating a new application or looking to convert an existing one.
If you’re new to .NET development
If you’re new to .NET development and are considering ASP.NET Core, then welcome! Microsoft is pushing ASP.NET Core as an attractive option for web development beginners, but taking .NET cross-platform means it’s competing with many other frameworks on their own turf. ASP.NET Core has many selling points when compared to other cross-platform web frameworks:
It’s a modern, high-performance, open source web framework.
It uses familiar design patterns and paradigms.
C# is a great language (or you can use VB.NET or F# if you prefer).
You can build and run on any platform.
ASP.NET Core is a re-imagining of the ASP.NET framework, built with modern software design principles on top of the new .NET Core platform. Although new in one sense, .NET Core has several years of widespread production use, and has drawn significantly from the mature, stable, and reliable .NET Framework, which has been used for nearly two decades. You can rest easy knowing that by choosing ASP.NET Core and .NET Core, you’ll be getting a dependable platform as well as a fully-featured web framework.
Many of the web frameworks available today use similar, well-established design patterns, and ASP.NET Core is no different. For example, Ruby on Rails is known for its use of the Model-View-Controller (MVC) pattern; Node.js is known for the way it processes requests using small discrete modules (called a pipeline); and dependency injection is found in a wide variety of frameworks. If these techniques are familiar to you, you should find it easy to transfer them across to ASP.NET Core; if they’re new to you, then you can look forward to using industry best practices!
The primary language of .NET development, and ASP.NET Core in particular, is C#. This language has a huge following, and for good reason! As an object-oriented C-based language, it provides a sense of familiarity to those used to C, Java, and many other languages. In addition, it has many powerful features, such as Language Integrated Query (LINQ), closures, and asynchronous programming constructs. The C# language is also designed in the open on GitHub, as is Microsoft’s C# compiler, codenamed Roslyn.
The primary language of .NET development and ASP.NET Core is C#. This language has a huge following, and for good reason! As an object-oriented C-based language it provides a sense of familiarity to those familiar with C, Java, and many other languages. In addition, it has many powerful features, such as Language Integrated Query (LINQ), closures, and asynchronous programming constructs. The C# language is also designed in the open on GitHub, as is Microsoft’s C# compiler, code-named Roslyn [^1].
One of the major selling points of ASP.NET Core and .NET Core is the ability to develop and run on any platform. Whether you’re using a Mac, Windows, or Linux, you can run the same ASP.NET Core apps and develop across multiple environments. As a Linux user, a wide range of distributions are supported (RHEL, Ubuntu, Debian, Cent-OS, Fedora, and openSUSE, to name a few), so you can be confident your operating system of choice will be a viable option. ASP.NET Core even runs on the tiny Alpine distribution, for truly compact deployments to containers.
Built with containers in mind
Traditionally, web applications were deployed directly to a server, or more recently, to a virtual machine. Virtual machines allow operating systems to be installed in a layer of virtual hardware, abstracting away the underlying hardware. This has several advantages over direct installation, such as easy maintenance, deployment, and recovery. Unfortunately, they’re also heavy both in terms of file size and resource use.
This is where containers come in. Containers are far more lightweight and don’t have the overhead of virtual machines. They’re built in a series of layers and don’t require you to boot a new operating system when starting a new one. That means they’re quick to start and are great for quick provisioning. Containers, and Docker in particular, are quickly becoming the go-to platform for building large, scalable systems.
Containers have never been a particularly attractive option for ASP.NET applications, but with ASP.NET Core, .NET Core, and Docker for Windows, that’s all changing. A lightweight ASP.NET Core application running on the cross-platform .NET Core framework is perfect for thin container deployments. You can learn more about your deployment options in chapter 16.
As well as running on each platform, one of the selling points of .NET is the ability to write and compile only once. Your application is compiled to Intermediate Language (IL) code, which is a platform-independent format. If a target system has the .NET Core platform installed, then you can run compiled IL from any platform. That means you can, for example, develop on a Mac or a Windows machine and deploy the exact same files to your production Linux machines. This compile-once, run-anywhere promise has finally been realized with ASP.NET Core and .NET Core.
If you’re a .NET Framework developer creating a new application
If you’re a .NET developer, then the choice of whether to invest in ASP.NET Core for new applications has largely been a question of timing. Early versions of .NET Core were lacking in some features that made it hard to adopt. With the release of .NET Core 3.1 and .NET 5, that is no longer a problem; Microsoft now explicitly advises that all new .NET applications should use .NET Core. Microsoft has pledged to provide bug and security fixes for the older ASP.NET framework, but it won’t receive any more feature updates. .NET Framework isn’t being removed, so your old applications will continue to work, but you shouldn’t use it for new development.
The main benefits of ASP.NET Core over the previous ASP.NET framework are:
Cross-platform development and deployment
A focus on performance as a feature
A simplified hosting model
Regular releases with a shorter release cycle
Open source
Modular features
As a .NET developer, if you aren’t using any Windows-specific constructs, such as the Registry, then the ability to build and deploy applications cross-platform opens the door to a whole new avenue of applications: take advantage of cheaper Linux VM hosting in the cloud, use Docker containers for repeatable continuous integration, or write .NET code on your Mac without needing to run a Windows virtual machine. ASP.NET Core, in combination with .NET Core, makes all this possible.
.NET Core is inherently cross-platform, but you can still use platform-specific features if you need to. For example, Windows-specific features like the Registry or Directory Services can be enabled with a compatibility pack[^2] that makes these APIs available in .NET Core. They’re only available when running .NET Core on Windows, not on Linux or macOS, so you need to take care that such applications only run in a Windows environment, or account for the potential missing APIs.
The hosting model for the previous ASP.NET framework was a relatively complex one, relying on Windows IIS to provide the web server hosting. In a cross-platform environment, this kind of symbiotic relationship isn’t possible, so an alternative hosting model has been adopted, one which separates web applications from the underlying host. This opportunity has led to the development of Kestrel: a fast, cross-platform HTTP server on which ASP.NET Core can run.
Instead of the previous design, whereby IIS calls into specific points of your application, ASP.NET Core applications are console applications that self-host a web server and handle requests directly, as shown in figure 3. This hosting model is conceptually much simpler and allows you to test and debug your applications from the command line, though it doesn’t remove the need to run IIS (or equivalent) in production.
Figure 3. The difference between hosting models in ASP.NET (top) and ASP.NET Core (bottom). With the previous version of ASP.NET, IIS is tightly coupled with the application. The hosting model in ASP.NET Core is simpler; IIS hands off the request to a self-hosted web server in the ASP.NET Core application and receives the response, but has no deeper knowledge of the application.
Changing the hosting model to use a built-in HTTP web server has created another opportunity. Performance has been somewhat of a sore point for ASP.NET applications in the past. It’s certainly possible to build high-performing applications—Stack Overflow (https://stackoverflow.com) is testament to that—but the web framework itself isn’t designed with performance as a priority, so it can end up being somewhat of an obstacle.
To be competitive cross-platform, the ASP.NET team have focused on making the Kestrel HTTP server as fast as possible. TechEmpower (www.techempower.com/benchmarks) has been running benchmarks on a whole range of web frameworks from various languages for several years now. In Round 19 of the plain text benchmarks, TechEmpower announced that ASP.NET Core with Kestrel was the fastest of over 400 frameworks tested[^3]!
Web servers – naming things is hard
One of the difficult aspects of programming for the web is the confusing array of often conflicting terminology. For example, if you’ve used IIS in the past, you may have described it as a web server, or possibly a web host. Conversely, if you’ve ever built an application using Node.js, you may have also referred to that application as a web server. Alternatively, you may have called the physical machine on which your application runs a web server!
Similarly, you may have built an application for the internet and called it a website or a web application, probably somewhat arbitrarily based on the level of dynamism it displayed.
When I say “web server” in the context of ASP.NET Core, I am referring to the HTTP server that runs as part of your ASP.NET Core application. By default, this is the Kestrel web server, but that’s not a requirement. It would be possible to write a replacement web server and substitute it for Kestrel if you desired.
The web server is responsible for receiving HTTP requests and generating responses. In the previous version of ASP.NET, IIS took this role, but in ASP.NET Core, Kestrel is the web server.
I will only use the term web application to describe ASP.NET Core applications, regardless of whether they contain only static content or are completely dynamic. Either way, they’re applications that are accessed via the web, so that name seems the most appropriate!
Many of the performance improvements made to Kestrel did not come from the ASP.NET team themselves, but from contributors to the open source project on GitHub. Developing in the open means you typically see fixes and features make their way to production faster than you would for the previous version of ASP.NET, which was dependent on .NET Framework and Windows and, as such, had long release cycles.
In contrast, .NET Core, and hence ASP.NET Core, is designed to be released in small increments. Major versions will be released on a predictable cadence, with a new version every year, and a new Long Term Support (LTS) version released every two years. In addition, bug fixes and minor updates can be released as and when they’re needed. Additional functionality is provided as NuGet packages, independent of the underlying .NET Core platform.
NOTE NuGet is a package manager for .NET that enables importing libraries into your projects. It’s equivalent to Ruby Gems, npm for JavaScript, or Maven for Java.
To enable this, ASP.NET Core is highly modular, with as little coupling to other features as possible. This modularity lends itself to a pay-for-play approach to dependencies, where you start from a bare-bones application and only add the additional libraries you require, as opposed to the kitchen-sink approach of previous ASP.NET applications. Even MVC is an optional package! But don’t worry, this approach doesn’t mean that ASP.NET Core is lacking in features; it means you need to opt in to them. Some of the key infrastructure improvements include:
Middleware “pipeline” for defining your application’s behavior
Built-in support for dependency injection
Combined UI (MVC) and API (Web API) infrastructure
Highly extensible configuration system
Scalable for cloud platforms by default using asynchronous programming
Each of these features was possible in the previous version of ASP.NET but required a fair amount of additional work to set up. With ASP.NET Core, they’re all there, ready, and waiting to be connected!
Microsoft fully supports ASP.NET Core, so if you have a new system you want to build, then there’s no significant reason not to. The largest obstacle you’re likely to come across is when you want to use programming models that are no longer supported in ASP.NET Core, such as Web Forms or WCF server (more about that in the next section).
Hopefully, this section has whetted your appetite with some of the many reasons to use ASP.NET Core for building new applications. But if you’re an existing ASP.NET developer considering whether to convert an existing ASP.NET application to ASP.NET Core, that’s another question entirely.
Converting an existing ASP.NET application to ASP.NET Core
In contrast with new applications, an existing application is presumably already providing value, so there should always be a tangible benefit to performing what may amount to a significant rewrite in converting from ASP.NET to ASP.NET Core. The advantages of adopting ASP.NET Core are much the same as for new applications: cross-platform deployment, modular features, and a focus on performance. Determining whether the benefits are sufficient will depend largely on the particulars of your application, but there are some characteristics that are clear indicators against conversion:
Your application uses ASP.NET Web Forms
Your application is built using WCF
Your application is large, with many “advanced” MVC features
If you have an ASP.NET Web Forms application, then attempting to convert it to ASP.NET Core isn’t advisable. Web Forms is inextricably tied to System.Web.dll, and as such will likely never be available in ASP.NET Core. Converting an application to ASP.NET Core would effectively involve rewriting the application from scratch, not only shifting frameworks but also shifting design paradigms. A better approach would be to slowly introduce Web API concepts and try to reduce the reliance on legacy Web Forms constructs such as ViewData. You can find many resources online to help you with this approach, in particular, the https://www.asp.net/web-api website.
Windows Communication Foundation (WCF) is only partially supported in ASP.NET Core[^4]. It’s possible to consume some WCF services, but support is spotty at best. There’s no supported way to host a WCF service from an ASP.NET Core application, so if you absolutely must support WCF, then ASP.NET Core may be best avoided for now.
TIP If you like WCFs RPC-style of programming, but don’t have a hard requirement on WCF itself, then consider using gRPC instead. gRPC is a modern RPC framework with many similar concepts as WCF and is supported by ASP.NET Core out-of-the-box. You can find an eBook from Microsoft on gRPC for WCF developers at https://docs.microsoft.com/en-us/dotnet/architecture/grpc-for-wcf-developers/
If your existing application is complex and makes extensive use of the previous MVC or Web API extensibility points or message handlers, then porting your application to ASP.NET Core may be more difficult. ASP.NET Core is built with many similar features to the previous version of ASP.NET MVC, but the underlying architecture is different. Several of the previous features don’t have direct replacements, and so will require rethinking.
The larger the application, the greater the difficulty you’re likely to have converting your application to ASP.NET Core. Microsoft itself suggests that porting an application from ASP.NET MVC to ASP.NET Core is at least as big a rewrite as porting from ASP.NET Web Forms to ASP.NET MVC. If that doesn’t scare you, then nothing will!
If an application is rarely used, isn’t part of your core business, or won’t need significant development in the near term, then I strongly suggest you don’t try to convert it to ASP.NET Core. Microsoft will support .NET Framework for the foreseeable future (Windows itself depends on it!) and the payoff in converting these “fringe” applications is unlikely to be worth the effort.
So, when should you port an application to ASP.NET Core? As I’ve already mentioned, the best opportunity for getting started is on small, green-field, new projects instead of existing applications. That said, if the existing application in question is small, or will need significant future development, then porting may be a good option. It is always best to work in small iterations where possible, rather than attempting to convert the entire application at once. But if your application consists primarily of MVC or Web API controllers and associated Razor views, then moving to ASP.NET Core may well be a good choice.
Summary
That’s all for this article. If you want to see more of the book’s contents, you can preview them on our browser-based liveBook platform here. Don’t forget to save 40% with code bllock2 at manning.com.
[^1]: The C# language and .NET Compiler Platform GitHub source code repository can be found at https://github.com/dotnet/roslyn.
[^2]: The Windows Compatibility Pack is designed to help port code from .NET Framework to .NET Core. See http://mng.bz/50hu.
[^3]: As always in web development, technology is in a constant state of flux, so these benchmarks will evolve over time. Although ASP.NET Core may not maintain its top ten slot, you can be sure that performance is one of the key focal points of the ASP.NET Core team.
[^4]: You can find the client libraries for using WCF with .NET Core at https://github.com/dotnet/wcf.
In this post I show how the endpoint routes in an ASP.NET Core 3.0 application can be visualized using the GraphvizOnline service. That lets you create diagrams like the following, which describe all the endpoints in your application:
Drawing graphs with GraphvizOnline and the DOT language
GraphvizOnline is a GitHub project that provides an online vizualizer for viewing graphs specified in the DOT graph description language. This is a simple language that lets you define various types of graph, which connects nodes with edges.
For example, a basic undirected graph could be defined as
graph MyGraph {
a -- b -- c;
b -- d;}
which describes the following graph:
Each node has a name (a, b, c, d), and -- defines the edges between the nodes. The edges define connections between nodes, but they don't have a direction (hence the name, undirected).
You can also define a directed graph, in which the edges do have a direction. For a directed edge use -> instead of --. For example:
digraph MyGraph {
a -> b -> c;
d -> b;}
which describes the following graph:
You can customise the way the nodes and edges are displayed in multiple ways. For example, you can label the nodes and edges:
digraph MySimpleGraph {// The label attribute can be used to change the label of a node...
a [label="Foo"];
b [label="Bar"];// ... or an edge
a -> b [label="Baz"];}
Visualizing ASP.NET Core endpoints as a directed graph
The endpoint routing system in ASP.NET Core effectively works by creating a directed graph of the endpoint URL segments. Incoming requests are then matched, a segment at a time, to the graph to determine the endpoint to execute.
For example, the following simple directed graph represents the endpoints in the default ASP.NET Core 3.0 Razor Pages application template (dotnet new webapp), which contains three Razor Pages: Index.cshtml, Error.cshtml and Privacy.cshtml:
In the DOT file above, the nodes are given sequential integer names, 1, 2, 3 etc and are labelled using the endpoint name. This is the format ASP.NET Core uses for representing the endpoint graph.
For Razor Pages, the routing is very simple, so the graph is pretty obvious. A more interesting graph is produced by an API application. For example, the ValuesController implementation shown below is similar to the version included in the ASP.NET Core 2.0 templates. It uses multiple HTTP verbs, as well as a slightly more complex URL structure:
[Route("api/[controller]")][ApiController]publicclassValuesController:ControllerBase{// GET api/values[HttpGet]public ActionResult<IEnumerable<string>>Get()=>newstring[]{"value1","value2"};// GET api/values/5[HttpGet("{id}")]public ActionResult<string>Get(int id)=>"value";// POST api/values[HttpPost]publicvoidPost([FromBody]stringvalue){}// PUT api/values/5[HttpPut("{id}")]publicvoidPut(int id,[FromBody]stringvalue){}// DELETE api/values/5[HttpDelete("{id}")]publicvoidDelete(int id){}}
For good measure, I also added a basic health check endpoint to UseEndpoints():
There's a lot more going on in this graph, as we now have variable route parameter values ({id} in the route templates, shown as {...} in the graph) and HTTP verb constraints (GET/PUT/POST etc).
When I first saw this graph, I struggled to understand it. Is every node an endpoint? Surely not, as /api/ shouldn't generate a response. And what about the HTTP: * endpoints, do they generate a response?
To understand further, I went spelunking into the ASP.NET Core code that can generate these graphs, but it's a bit involved, and unfortunately not overly amenable to experimentation, due to extensive use of internal classes. I explore this code in a later post.
To better grasp the endpoint graph, we need to understand that not all the nodes are the same. In the next section we'll dig into the different types of node in even this simple graph, and then look at a better graphical representation (in my opinion at least!)
Understanding the different types of node.
Each node in the graph is associated with a given "depth". This is the number of URL segments that should already be matched. For example, the /api/Values/ node has a depth of 2—it requires the empty segment / and the /api segment to already be matched.
When a request reaches the EndpointRoutingMiddleware (added by UseRouting()), the incoming request URL is compared against this graph. A path is attempted to be found through the graph, starting with the root node at the top of the tree. URL segments are incrementally matched to edges in the graph, and a path is traversed through the graph until the whole request URL is matched.
Each node (represented by the DfaNode in ASP.NET Core internally) has several properties . The properties we're interested in for now are:
Matches: This is the Endpoint(s) associated with the node. If this node is matched via routing, then this is the Endpoint that will be selected for execution.
Literals: These are the edges that connect nodes. If a DfaNode has any Literals, it has literal segments that can be further traversed to reached other nodes. For example, the /api/ node contains a single Literal with value /Values, pointing to the /api/Values node.
PolicyEdges: These are edges that match based on a constraint other than the URL. For example, the verb-based edges in the graph, such as HTTP: GET, are policy edges, that point to a different DfaNode.
Parameters: If the node has an edge that supports route parameters (e.g. {id}), Parameters points to the node that handles matching the parameters. This is represented in the graph by the edge /*.
There is an additional property, CatchAll, which is relevant in some graphs, but I'll ignore it for now, as it's not required for our API graph.
Based on these properties, we can add some additional richness to our graph, by making use of some of the other features in the DOT language, such as shapes, colours, line type and arrowheads:
This graph makes the following additions:
Nodes which don't have any associated Endpoint are shown in the default style, black bubbles.
Nodes with Matches are shown as filled, brown, boxes. These are nodes with an Endpoint, that can generate a response. For the API example above, this applies to the nodes where a verb has been selected, as well as the health check endpoint.
Literal segment edges are shown as default black edges, with a filled arrowhead.
Parameters edges (/*) are shown in blue, using a diamond arrowhead.
PolicyEdges are shown in red, with a dashed line, and an empty triangle arrowhead.
Now, I freely admit my design skills suck, but nevertheless I think you can agree that this graph shows way more information than the default! 🙂 This is the definition that generated the graph above, remember you can visualise and play with the display yourself using an online editor.
Note the "HTTP: *" nodes are associated with an endpoint, even though you might not expect it, because they return a 405 Method Not Allowed.
In the next post, I'll show how you can generate endpoint graphs for your own ASP.NET Core applications.
Summary
In this post I provided an introduction to the DOT language for describing graphs, and showed how you can use online editors to create images from the graphs. I then showed how routing for endpoints in an ASP.NET Core 3.x application can be represented as a directed graph. I described the differences between various nodes and edges in the endpoint graph, and tweaked the graph's display to better represent these differences. In later posts I'll show how you can generate your own endpoint graphs for your application, how to customise the display, and how to do more than just view the graphs.
In this post I show how to visualize the endpoint routes in your ASP.NET Core 3.0 application using the DfaGraphWriter service. I show how to generate a directed graph (as shown in my previous post) which can be visualized using GraphVizOnline. Finally, I describe the points in your application's lifetime where you can retrieve the graph data.
In this post I only show how to create the "default" style of graph. In my next post I create a custom writer for generating the customised graphs like the one in my previous post.
This class has a single method, Write. The EndpointDataSource contains the collection of Endpoints describing your application, and the TextWriter is used to write the DOT language graph (as you saw in my previous post).
For now we'll create a middleware that uses the DfaGraphWriter to write the graph as an HTTP response. You can inject both the DfaGraphWriter and the EndpointDataSource it uses into the constructor using DI:
publicclassGraphEndpointMiddleware{// inject required services using DIprivatereadonlyDfaGraphWriter _graphWriter;privatereadonlyEndpointDataSource _endpointData;publicGraphEndpointMiddleware(RequestDelegate next,DfaGraphWriter graphWriter,EndpointDataSource endpointData){
_graphWriter = graphWriter;
_endpointData = endpointData;}publicasyncTaskInvoke(HttpContext context){// set the response
context.Response.StatusCode =200;
context.Response.ContentType ="text/plain";// Write the response into memoryawaitusing(var sw =newStringWriter()){// Write the graph
_graphWriter.Write(_endpointData, sw);var graph = sw.ToString();// Write the graph to the responseawait context.Response.WriteAsync(graph);}}}
This middleware is pretty simple—we inject the necessary services into the middleware using dependency injection. Writing the graph to the response is a bit more convoluted: you have to write the response in-memory to a StringWriter, convert it to a string, and then write it to the graph.
This is all necessary because the DfaGraphWriter writes to the TextWriter using synchronousStream API calls, like Write, instead of WriteAsync. Ideally, we would be able to do something like this:
// Create a stream writer that wraps the bodyawaitusing(var sw =newStreamWriter(context.Response.Body)){// write asynchronously to the streamawait _graphWriter.WriteAsync(_endpointData, sw);}
If DfaGraphWriter used asynchronous APIs, then you could write directly to Response.Body as shown above and avoid the in-memory string. Unfortunately, it's synchronous, and you shouldn't write to Response.Body using synchronous calls for performance reasons. If you try to use pattern above then you may get an InvalidOperationException like the following, depending on the size of the graph being written:
System.InvalidOperationException: Synchronous operations are disallowed. Call WriteAsync or set AllowSynchronousIO to true instead.
You might not get this exception if the graph is small, but you can see it if you try and map a medium-side application, such as the default Razor Pages app with Identity.
Let's get back on track—we now have a graph-generating middleware, so lets add it to the pipeline. There's two options here:
Add it as an endpoint using endpoint routing.
Add it as a simple "branch" from your middleware pipeline.
The former approach is the generally recommended method for adding endpoints to ASP.NET Core 3.0 apps, so lets start there.
Adding the graph visualizer as an endpoint
To simplify the endpoint registration code, I'll create a simple extension method for adding the GraphEndpointMiddleware as an endpoint:
We can then add the graph endpoint to our ASP.NET Core application by calling MapGraphVisualisation("/graph") in the UseEndpoints() method in Startup.Configure():
That's all we need to do. The DfaGraphWriter is already available in DI, so there's no additional configuration required there. Navigating to http://localhost:5000/graph (for example) generates the graph of our endpoints as plain text (shown here for the app from ](/visualizing-asp-net-core-endpoints-using-graphvizonline-and-the-dot-language/):
Exposing the graph as an endpoint in the endpoint routing system has both pros and cons:
You can easily add authorization to the endpoint. You probably don't want just anyone to be able to view this data!
The graph endpoint shows up as an endpoint in the system. That's obviously correct, but could be annoying.
If that final point is a deal breaker for you, you could use the old-school way of creating endpoints, using branching middleware.
Adding the graph visualizer as a middleware branch
Adding branches to your middleware pipeline was one of the easiest way to create "endpoints" before we had endpoint routing. It's still available in ASP.NET Core 3.0, it's just far more basic than the endpoint routing system, and doesn't provide the ability to easily add authorization or advanced routing.
To create a middleware branch, use the Map() command. For example, you could add a branch using the following:
publicvoidConfigure(IApplicationBuilder app,IWebHostEnvironment env){// add the graph endpoint as a branch of the pipeline
app.Map("/graph", branch =>
branch.UseMiddleware<GraphEndpointMiddleware>());
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>{
endpoints.MapHealthChecks("/healthz");
endpoints.MapControllers();});}
The pros and cons of using this approach are essentially the opposite of the endpoint-routing version: there's no /graph endpoint in your graph, but you can't easily apply authorization to the endpoint!
For me, it doesn't make a lot of sense to expose the graph of your application like this. In the next section, I show how you can generate the graph from a small integration test instead.
Generating an endpoint graph from an integration test
As well as the traditional "end-to-end" integration tests that you can use to confirm the overall correct operation of your app, I sometimes like to write "sanity-check" tests, that confirm that an application is configured correctly. You can achieve this by using the WebApplicationFactory<> facility, in Microsoft.AspNetCore.Mvc.Testing which exposes the underlying DI container. This allows you to run code in the DI context of the application, but from a unit test.
To try it out
Create a new xUnit project (my testing framework of choice) using VS or by running dotnet new xunit
Install Microsoft.AspNetCore.Mvc.Testing by running dotnet add package Microsoft.AspNetCore.Mvc.Testing
Update the <Project> element of the test project to <Project Sdk="Microsoft.NET.Sdk.Web">
Reference your ASP.NET Core project from the test project
We can now create a simple test that generates the endpoint graph, and writes it to the test output. In the example below, I'm using the default WebApplicationFactory<> as a class fixture; if you need to customise the factory, see the docs or my previous post for details.
In addition to WebApplicationFactory<>, I'm also injecting ITestOutputHelper. You need to use this class to record test output with xUnit. Writing directly to Console won't work..
publicclassGenerateGraphTest:IClassFixture<WebApplicationFactory<ApiRoutes.Startup>>{// Inject the factory and the output helperprivatereadonly WebApplicationFactory<ApiRoutes.Startup> _factory;privatereadonlyITestOutputHelper _output;publicGenerateGraphTest(
WebApplicationFactory<Startup> factory,ITestOutputHelper output){
_factory = factory;
_output = output;}[Fact]publicvoidGenerateGraph(){// fetch the required services from the root container of the appvar graphWriter = _factory.Services.GetRequiredService<DfaGraphWriter>();var endpointData = _factory.Services.GetRequiredService<EndpointDataSource>();// build the graph as beforeusing(var sw =newStringWriter()){
graphWriter.Write(endpointData, sw);var graph = sw.ToString();// write the graph to the test output
_output.WriteLine(graph);}}}
The bulk of the test is the same as for the middleware, but instead of writing to the response, we write to xUnit's ITestOutputHelper. This records the output against the test. In Visual Studio, you can view this output by opening Test Explorer, navigating to the GenerateGraph test, and clicking "Open additional output for this result", which opens the result as a tab:
I find a simple test like this is often sufficient for my purposes. There's lots of advantages in my eyes:
It doesn't expose this data as an endpoint
Has no impact on your application
Can be easily generated
Nevertheless, maybe you want to generate this graph from your application, but you don't want to include it using either of the middleware approaches shown so far. If so, just be careful exactly where you do it.
You can't generate the graph in an IHostedService
Generally speaking, you can access the DfaGraphWriter and EndpointDataSource services from anywhere in your app that uses dependency injection, or that has access to an IServiceProvider instance. That means generating the graph in the context of a request, for example from an MVC controller or Razor Page is easy, and identical to the approach you've seen so far.
Where you must be careful is if you're trying to generate the graph early in your application's lifecycle. This applies particularly to IHostedServices.
In ASP.NET Core 3.0, the web infrastructure was rebuilt on top of the generic host, which means your server (Kestrel) runs as an IHostedService in your application. In most cases, this shouldn't have a big impact, but it changes the order that your application is built, compared to ASP.NET Core 2.x.
In ASP.NET Core 2.x, the following things would happen:
The middleware pipeline is built.
The server (Kestrel) starts listening for requests.
The IHostedService implementations are started.
Instead, on ASP.NET Core 3.x, you have the following:
The IHostedService implementations are started.
The GenericWebHostService is started:
The middleware pipeline is built
The server (Kestrel) starts listening for requests.
The important thing to note is that the middleware pipeline isn't built until after your IHostedServices are executed. As UseEndpoints() has not yet been called, EndpointDataSource won't contain any data!
The EndpointDataSource will be empty if you try and generate your graph using DfaGraphWriter from an IHostedService.
The same goes if you try and use another standard mechanisms for injecting early behaviour, like IStartupFilter—these execute beforeStartup.Configure() is called, so the EndpointDataSource will be empty.
Similarly, you can't just build a Host by calling IHostBuilder.Build() in Program.Main, and access the services using IHost.Services: until you call IHost.Run, and the server has started, your endpoint list will be empty!
These limitations may or may not be an issue depending on what you're trying to achieve. For me, the unit test approach solves most of my issues.
Whichever approach you use, you're stuck only being able to generate the "default" endpoint graphs shown in this post. As I mentioned in my previous post, this hides a lot of really useful information, like which nodes generate an endpoint. In the next post, I show how to create a custom graph writer, so you can generate your own graphs.
Summary
In this post I showed how to use the DfaGraphWriter and EndpointDataSource to create a graph of all the endpoints in your application. I showed how to create a middleware endpoint to expose this data, and how to use this middleware both with a branching middleware strategy and as an endpoint route.
I also showed how to use a simple integration test to generate the graph data without having to run your application. This avoids exposing (the potentially sensitive) endpoint graph publicly, while still allowing easy access to the data.
Finally, I discussed when you can generate the graph in your application's lifecycle. The EndpointDataSource is not populated until after the Server (Kestrel) has started, so you're primarily limited to accessing the data in a Request context. IHostedService and IStartupFilter execute too early to access the data, and IHostBuilder.Build() only builds the DI container, not the middleware pipeline.
In this post I lay the groundwork for creating a custom implementation of DfaGraphWriter. DfaGraphWriter is public, so you can use it in your application as I showed in my previous post, but all the classes it uses are marked internal. That makes creating your own version problematic. To work around that, I use an open source reflection library, ImpromptuInterface, to make creating a custom DfaGraphWriter implementation easier.
We'll start by looking at the existing DfaGraphWriter, to understand the internal classes it uses and the issues that causes us. Then we'll look at using some custom interfaces and the ImpromptuInterface library to allow us to call those classes. In the next post, we'll look at how to use our custom interfaces to create a custom version of the DfaGraphWriter.
publicclassDfaGraphWriter{privatereadonlyIServiceProvider _services;publicDfaGraphWriter(IServiceProvider services){
_services = services;}publicvoidWrite(EndpointDataSource dataSource,TextWriter writer){// retrieve the required DfaMatcherBuildervar builder = _services.GetRequiredService<DfaMatcherBuilder>();// loop through the endpoints in the dataSource, and add them to the buildervar endpoints = dataSource.Endpoints;for(var i =0; i < endpoints.Count; i++){if(endpoints[i]isRouteEndpoint endpoint &&(endpoint.Metadata.GetMetadata<ISuppressMatchingMetadata>()?.SuppressMatching ??false)==false){
builder.AddEndpoint(endpoint);}}// Build the DfaTree. // This is what we use to create the endpoint graphvar tree = builder.BuildDfaTree(includeLabel:true);// Add the header
writer.WriteLine("digraph DFA {");// Visit each node in the graph to create the output
tree.Visit(WriteNode);//Close the graph
writer.WriteLine("}");// Recursively walks the tree, writing it to the TextWritervoidWriteNode(DfaNode node){// Removed for brevity - we'll explore it in the next post}}}
The code above shows everything the graph writer's Write method does, but in summary:
Fetches a DfaMatcherBuilder
Writes all of the endpoints in the EndpointDataSource to the DfaMatcherBuilder.
Calls BuildDfaTree on the DfaMatcherBuilder. This creates a graph of DfaNodes.
Visit each DfaNode in the tree, and write it to the TextWriter output. We'll explore this method in the next post.
The goal of creating our own custom writer is to customise that last step, by controlling how different nodes are written to the output, so we can create more descriptive graphs, as I showed previously:
Our problem is that two key classes, DfaMatcherBuilder and DfaNode, are internal so we can't easily instantiate them, or write methods that use them. That gives one of two options:
Reimplement the internal classes, including any further internal classes they depend on.
Use reflection to create and invoke methods on the existing classes.
Neither of those are great options, but given that the endpoint graph isn't a performance-critical thing, I decided using reflection would be the easiest. To make things even easier, I used the open source library, ImpromptuInterface.
Making reflection easier with ImpromptuInterface
ImpromptuInterface is a library that makes it easier to call dynamic objects, or to invoke methods on the underlying object stored in an object reference. It essentially adds easy duck/structural typing, by allowing you to use a stronlgy-typed interface for the object. It achieves that using the Dynamic Language Runtime and Reflection.Emit.
For example, lets take the existing DfaMatcherBuilder class that we want to use. Even though we can't reference it directly, we can still get an instance of this class from the DI container as shown below:
// get the DfaMatcherBuilder type - internal, so needs reflection :(Type matcherBuilder =typeof(IEndpointSelectorPolicy).Assembly
.GetType("Microsoft.AspNetCore.Routing.Matching.DfaMatcherBuilder");object rawBuilder = _services.GetRequiredService(matcherBuilder);
The rawBuilder is an object reference, but it contains an instance of the DfaMatcherBuilder. We can't directly call methods on it, but we can invoke them using reflection by building MethodInfo and calling Invoke directly.
ImpromptuInterface makes that process a bit easier, by providing a static interface that you can directly call methods on. For example, for the DfaMatcherBuilder, we only need to call two methods, AddEndpoint and BuildDfaTree. The original class looks something like this:
internalclassDfaMatcherBuilder:MatcherBuilder{publicoverridevoidAddEndpoint(RouteEndpoint endpoint){/* body */}publicDfaNodeBuildDfaTree(bool includeLabel =false)}
We can create an interface that exposes these methods:
We can then use the ImpromptuInterfaceActLike<> method to create a proxy object that implements the IDfaMatcherBuilder. This proxy wraps the rawbuilder object, so that when you invoke a method on the interface, it calls the equivalent method on the underlying DfaMatcherBuilder:
In code, that looks like:
// An instance of DfaMatcherBuilder in an object referenceobject rawBuilder = _services.GetRequiredService(matcherBuilder);// wrap the instance in the ImpromptuInterface interfaceIDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// we can now call methods on the builder directly, e.g. object rawTree = builder.BuildDfaTree();
There's an important difference between the original DfaMatcherBuilder.BuildDfaTree() method and the interface version: the original returns a DfaNode, but that's another internal class, so we can't reference it in our interface.
Instead we create another ImpromptuInterface for the DfaNode class, and expose the properties we're going to need (you'll see why we need them in the next post):
publicinterfaceIDfaNode{publicstring Label {get;set;}public List<Endpoint> Matches {get;}publicIDictionary Literals {get;}// actually a Dictionary<string, DfaNode>publicobject Parameters {get;}// actually a DfaNodepublicobject CatchAll {get;}// actually a DfaNodepublicIDictionary PolicyEdges {get;}// actually a Dictionary<object, DfaNode>}
We'll use these properties in the WriteNode method in the next post, but there's some complexities. In the original DfaNode class, the Parameters and CatchAll properties return DfaNode objects. In our IDfaNode version of the properties we have to return object instead. We can't reference a DfaNode (because it's internal) and we can't return an IDfaNode, because DfaNodedoesn't implement IDfaNode, so you can't you can't implicitly cast the object reference to an IDfaNode. You have to use ImpromptuInterface to explicitly add a proxy that implements the interface.
For example:
// Wrap the instance in the ImpromptuInterface interfaceIDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// We can now call methods on the builder directly, e.g. object rawTree = builder.BuildDfaTree();// Use ImpromptuInterface to add an IDfaNode wrapperIDfaNode tree = rawTree.ActLike<IDfaNode>();// We can now call methods and properties on the node...object rawParameters = tree.Parameters;// ...but they need to be wrapped using ImpromptuInterface tooIDfaNode parameters = rawParameters.ActLike<IDfaNode>();
We have another problem with the properties that return Dictionary types: Literals and PolicyEdges. The actual types returned are Dictionary<string, DfaNode> and Dictionary<object, DfaNode> respectively, but we need to use a type that doesn't contain the DfaNode type. Unfortunately, that means we have to fall back to the .NET 1.1 IDictionary interface!
IDictionary is a non-generic interface, so the key and value are only exposed as objects. For the string key you can cast directly, and for the DfaNode we can use ImpromptuInterface to create the proxy wrapper for us:
// Enumerate the key-value pairs as DictinoaryEntrysforeach(DictionaryEntry dictEntry in node.Literals){// Cast the key value to a string directlyvar key =(string)dictEntry.Key;// Use ImpromptuInterface to add a wrapperIDfaNodevalue= dictEntry.Value.ActLike<IDfaNode>();}
We now have everything we need to create a custom DfaWriter implementation by implementing WriteNode, but this post is already a bit long, so we'll explore how to do that in the next post!
Summary
In this post I explored the DfaWriter implementation in ASP.NET Core, and the two internal classes it uses: DfaMatcherBuilder and DfaNode. The fact these class are internal makes it tricky to create our own implementation of the DfaWriter. To implement it cleanly we would have to reimplement both of these types and all the classes they depend on.
Instead, I used the ImpromptuInterface library to create a wrapper proxy that implements similar methods to the object being wrapped. This uses reflection to invoke methods on the wrapped property, but allows us to work with a strongly typed interface. In the next post I'll show how to use these wrappers to create a custom DfaWriter for customising your endpoint graphs.
In this post I lay the groundwork for creating a custom implementation of DfaGraphWriter. DfaGraphWriter is public, so you can use it in your application as I showed in my previous post, but all the classes it uses are marked internal. That makes creating your own version problematic. To work around that, I use an open source reflection library, ImpromptuInterface, to make creating a custom DfaGraphWriter implementation easier.
We'll start by looking at the existing DfaGraphWriter, to understand the internal classes it uses and the issues that causes us. Then we'll look at using some custom interfaces and the ImpromptuInterface library to allow us to call those classes. In the next post, we'll look at how to use our custom interfaces to create a custom version of the DfaGraphWriter.
publicclassDfaGraphWriter{privatereadonlyIServiceProvider _services;publicDfaGraphWriter(IServiceProvider services){
_services = services;}publicvoidWrite(EndpointDataSource dataSource,TextWriter writer){// retrieve the required DfaMatcherBuildervar builder = _services.GetRequiredService<DfaMatcherBuilder>();// loop through the endpoints in the dataSource, and add them to the buildervar endpoints = dataSource.Endpoints;for(var i =0; i < endpoints.Count; i++){if(endpoints[i]isRouteEndpoint endpoint &&(endpoint.Metadata.GetMetadata<ISuppressMatchingMetadata>()?.SuppressMatching ??false)==false){
builder.AddEndpoint(endpoint);}}// Build the DfaTree. // This is what we use to create the endpoint graphvar tree = builder.BuildDfaTree(includeLabel:true);// Add the header
writer.WriteLine("digraph DFA {");// Visit each node in the graph to create the output
tree.Visit(WriteNode);//Close the graph
writer.WriteLine("}");// Recursively walks the tree, writing it to the TextWritervoidWriteNode(DfaNode node){// Removed for brevity - we'll explore it in the next post}}}
The code above shows everything the graph writer's Write method does, but in summary:
Fetches a DfaMatcherBuilder
Writes all of the endpoints in the EndpointDataSource to the DfaMatcherBuilder.
Calls BuildDfaTree on the DfaMatcherBuilder. This creates a graph of DfaNodes.
Visit each DfaNode in the tree, and write it to the TextWriter output. We'll explore this method in the next post.
The goal of creating our own custom writer is to customise that last step, by controlling how different nodes are written to the output, so we can create more descriptive graphs, as I showed previously:
Our problem is that two key classes, DfaMatcherBuilder and DfaNode, are internal so we can't easily instantiate them, or write methods that use them. That gives one of two options:
Reimplement the internal classes, including any further internal classes they depend on.
Use reflection to create and invoke methods on the existing classes.
Neither of those are great options, but given that the endpoint graph isn't a performance-critical thing, I decided using reflection would be the easiest. To make things even easier, I used the open source library, ImpromptuInterface.
Making reflection easier with ImpromptuInterface
ImpromptuInterface is a library that makes it easier to call dynamic objects, or to invoke methods on the underlying object stored in an object reference. It essentially adds easy duck/structural typing, by allowing you to use a stronlgy-typed interface for the object. It achieves that using the Dynamic Language Runtime and Reflection.Emit.
For example, lets take the existing DfaMatcherBuilder class that we want to use. Even though we can't reference it directly, we can still get an instance of this class from the DI container as shown below:
// get the DfaMatcherBuilder type - internal, so needs reflection :(Type matcherBuilder =typeof(IEndpointSelectorPolicy).Assembly
.GetType("Microsoft.AspNetCore.Routing.Matching.DfaMatcherBuilder");object rawBuilder = _services.GetRequiredService(matcherBuilder);
The rawBuilder is an object reference, but it contains an instance of the DfaMatcherBuilder. We can't directly call methods on it, but we can invoke them using reflection by building MethodInfo and calling Invoke directly.
ImpromptuInterface makes that process a bit easier, by providing a static interface that you can directly call methods on. For example, for the DfaMatcherBuilder, we only need to call two methods, AddEndpoint and BuildDfaTree. The original class looks something like this:
internalclassDfaMatcherBuilder:MatcherBuilder{publicoverridevoidAddEndpoint(RouteEndpoint endpoint){/* body */}publicDfaNodeBuildDfaTree(bool includeLabel =false)}
We can create an interface that exposes these methods:
We can then use the ImpromptuInterfaceActLike<> method to create a proxy object that implements the IDfaMatcherBuilder. This proxy wraps the rawbuilder object, so that when you invoke a method on the interface, it calls the equivalent method on the underlying DfaMatcherBuilder:
In code, that looks like:
// An instance of DfaMatcherBuilder in an object referenceobject rawBuilder = _services.GetRequiredService(matcherBuilder);// wrap the instance in the ImpromptuInterface interfaceIDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// we can now call methods on the builder directly, e.g. object rawTree = builder.BuildDfaTree();
There's an important difference between the original DfaMatcherBuilder.BuildDfaTree() method and the interface version: the original returns a DfaNode, but that's another internal class, so we can't reference it in our interface.
Instead we create another ImpromptuInterface for the DfaNode class, and expose the properties we're going to need (you'll see why we need them in the next post):
publicinterfaceIDfaNode{publicstring Label {get;set;}public List<Endpoint> Matches {get;}publicIDictionary Literals {get;}// actually a Dictionary<string, DfaNode>publicobject Parameters {get;}// actually a DfaNodepublicobject CatchAll {get;}// actually a DfaNodepublicIDictionary PolicyEdges {get;}// actually a Dictionary<object, DfaNode>}
We'll use these properties in the WriteNode method in the next post, but there's some complexities. In the original DfaNode class, the Parameters and CatchAll properties return DfaNode objects. In our IDfaNode version of the properties we have to return object instead. We can't reference a DfaNode (because it's internal) and we can't return an IDfaNode, because DfaNodedoesn't implement IDfaNode, so you can't you can't implicitly cast the object reference to an IDfaNode. You have to use ImpromptuInterface to explicitly add a proxy that implements the interface.
For example:
// Wrap the instance in the ImpromptuInterface interfaceIDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// We can now call methods on the builder directly, e.g. object rawTree = builder.BuildDfaTree();// Use ImpromptuInterface to add an IDfaNode wrapperIDfaNode tree = rawTree.ActLike<IDfaNode>();// We can now call methods and properties on the node...object rawParameters = tree.Parameters;// ...but they need to be wrapped using ImpromptuInterface tooIDfaNode parameters = rawParameters.ActLike<IDfaNode>();
We have another problem with the properties that return Dictionary types: Literals and PolicyEdges. The actual types returned are Dictionary<string, DfaNode> and Dictionary<object, DfaNode> respectively, but we need to use a type that doesn't contain the DfaNode type. Unfortunately, that means we have to fall back to the .NET 1.1 IDictionary interface!
IDictionary is a non-generic interface, so the key and value are only exposed as objects. For the string key you can cast directly, and for the DfaNode we can use ImpromptuInterface to create the proxy wrapper for us:
// Enumerate the key-value pairs as DictinoaryEntrysforeach(DictionaryEntry dictEntry in node.Literals){// Cast the key value to a string directlyvar key =(string)dictEntry.Key;// Use ImpromptuInterface to add a wrapperIDfaNodevalue= dictEntry.Value.ActLike<IDfaNode>();}
We now have everything we need to create a custom DfaWriter implementation by implementing WriteNode, but this post is already a bit long, so we'll explore how to do that in the next post!
Summary
In this post I explored the DfaWriter implementation in ASP.NET Core, and the two internal classes it uses: DfaMatcherBuilder and DfaNode. The fact these class are internal makes it tricky to create our own implementation of the DfaWriter. To implement it cleanly we would have to reimplement both of these types and all the classes they depend on.
Instead, I used the ImpromptuInterface library to create a wrapper proxy that implements similar methods to the object being wrapped. This uses reflection to invoke methods on the wrapped property, but allows us to work with a strongly typed interface. In the next post I'll show how to use these wrappers to create a custom DfaWriter for customising your endpoint graphs.
In this series, I've been laying the groundwork for building a custom endpoint visualization graph, as I showed in my first post. This graph shows the different parts of the endpoint routes: literal values, parameters, verb constraints, and endpoints that generate a result:
In this post I show how you can create an endpoint graph like this for your own application, by creating a custom DfaGraphWriter.
This post uses techniques and classes from the previous posts in the series, so I strongly suggest reading those before continuing.
Adding configuration for the endpoint graph
The first thing we'll look at is how to configure what the final endpoint graph will look like. We'll add configuration for two types of node and four types of edge. The edges are:
Literal edges: Literal matches for route sections, such as api and values in the route api/values/{id}.
Parameters edges: Parameterised sections for routes, such as {id} in the route api/values/{id}.
Catch all edges: Edges that correspond to the catch-all route parameter, such as {**slug}.
Policy edges: Edges that correspond to a constraint other than the URL. For example, the HTTP verb-based edges in the graph, such as HTTP: GET.
and the nodes are:
Matching node: A node that is associated with an endpoint match, so will generate a response.
Default node: A node that is not associated with an endpoint match.
Each of these nodes and edges can have any number of Graphviz attributes to control their display. The GraphDisplayOptions below show the default values I used to generate the graph at the start of this post:
publicclassGraphDisplayOptions{/// <summary>/// Additional display options for literal edges/// </summary>publicstring LiteralEdge {get;set;}=string.Empty;/// <summary>/// Additional display options for parameter edges/// </summary>publicstring ParametersEdge {get;set;}="arrowhead=diamond color=\"blue\"";/// <summary>/// Additional display options for catchall parameter edges/// </summary>publicstring CatchAllEdge {get;set;}="arrowhead=odot color=\"green\"";/// <summary>/// Additional display options for policy edges/// </summary>publicstring PolicyEdge {get;set;}="color=\"red\" style=dashed arrowhead=open";/// <summary>/// Additional display options for node which contains a match/// </summary>publicstring MatchingNode {get;set;}="shape=box style=filled color=\"brown\" fontcolor=\"white\"";/// <summary>/// Additional display options for node without matches/// </summary>publicstring DefaultNode {get;set;}=string.Empty;}
We can now create our custom graph writer using this object to control the display, and using the ImpromptuInterface "proxy" technique shown in the previous post.
Creating a custom DfaGraphWriter
Our custom graph writer (cunningly called CustomDfaGraphWriter) is heavily based on the DfaGraphWriter included in ASP.NET Core. The bulk of this class is the same as the original, with the following changes:
Inject the GraphDisplayOptions into the class to customise the display.
Use the ImpromptuInterface library to work with the internal DfaMatcherBuilder and DfaNode classes, as shown in the previous post.
Customise the WriteNode function to use our custom styles.
Add a Visit function to work with the IDfaNode interface, instead of using the Visit() method on the internal DfaNode class.
The whole CustomDfaGraphWriter is shown below, focusing on the main Write() function. I've kept the implementation almost identical to the original, only updating the parts we have to.
publicclassCustomDfaGraphWriter{// Inject the GraphDisplayOptions privatereadonlyIServiceProvider _services;privatereadonlyGraphDisplayOptions _options;publicCustomDfaGraphWriter(IServiceProvider services,GraphDisplayOptions options){
_services = services;
_options = options;}publicvoidWrite(EndpointDataSource dataSource,TextWriter writer){// Use ImpromptuInterface to create the required dependencies as shown in previous postType matcherBuilder =typeof(IEndpointSelectorPolicy).Assembly
.GetType("Microsoft.AspNetCore.Routing.Matching.DfaMatcherBuilder");// Build the list of endpoints used to build the graphvar rawBuilder = _services.GetRequiredService(matcherBuilder);IDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// This is the same logic as the original graph writervar endpoints = dataSource.Endpoints;for(var i =0; i < endpoints.Count; i++){if(endpoints[i]isRouteEndpoint endpoint &&(endpoint.Metadata.GetMetadata<ISuppressMatchingMetadata>()?.SuppressMatching ??false)==false){
builder.AddEndpoint(endpoint);}}// Build the raw tree from the registered routesvar rawTree = builder.BuildDfaTree(includeLabel:true);IDfaNode tree = rawTree.ActLike<IDfaNode>();// Store a list of nodes that have already been visited var visited =newDictionary<IDfaNode,int>();// Build the graph by visiting each node, and calling WriteNode on each
writer.WriteLine("digraph DFA {");Visit(tree, WriteNode);
writer.WriteLine("}");voidWriteNode(IDfaNode node){/* Write the node to the TextWriter *//* Details shown later in this post*/}}staticvoidVisit(IDfaNode node, Action<IDfaNode> visitor){/* Recursively visit each node in the tree. *//* Details shown later in this post*/}}
I've elided the Visit and WriteNode functions here for brevity, but we'll look into them soon. We'll start with the Visit function, as that flies closest to the original.
Updating the Visit function to work with IDfaNode
As I discussed in my previous post, one of the biggest problems creating a custom DfaGraphWriter is its use of internal classes. To work around that I used ImpromptuInterface to create proxy objects that wrap the original:
The original Visit() method is a method on the DfaNode class. It recursively visits every node in the endpoint tree, calling a provided Action<> function for each node.
As DfaNode is internal, I implemented the Visit function as a static method on CustomDfaGraphWriter instead.
Our custom implementation is broadly the same as the original, but we have to do some somewhat arduous conversions between the "raw" DfaNodes and our IDfaNode proxies. The updated method is shown below. The method takes two parameters—the node being checked, and an Action<> to run on each.
staticvoidVisit(IDfaNode node, Action<IDfaNode> visitor){// Does the node of interest have any nodes connected by literal edges?if(node.Literals?.Values !=null){// node.Literals is actually a Dictionary<string, DfaNode>foreach(var dictValue in node.Literals.Values){// Create a proxy for the child DfaNode node and visit itIDfaNodevalue= dictValue.ActLike<IDfaNode>();Visit(value, visitor);}}// Does the node have a node connected by a parameter edge?// The reference check breaks any cycles in the graphif(node.Parameters !=null&&!ReferenceEquals(node, node.Parameters)){// Create a proxy for the DfaNode node and visit itIDfaNode parameters = node.Parameters.ActLike<IDfaNode>();Visit(parameters, visitor);}// Does the node have a node connected by a catch-all edge?// The refernece check breaks any cycles in the graphif(node.CatchAll !=null&&!ReferenceEquals(node, node.CatchAll)){// Create a proxy for the DfaNode node and visit itIDfaNode catchAll = node.CatchAll.ActLike<IDfaNode>();Visit(catchAll, visitor);}// Does the node have a node connected by a policy edges?if(node.PolicyEdges?.Values !=null){// node.PolicyEdges is actually a Dictionary<object, DfaNode>foreach(var dictValue in node.PolicyEdges.Values){IDfaNodevalue= dictValue.ActLike<IDfaNode>();Visit(value, visitor);}}// Write the node using the provided Action<>visitor(node);}
The Visit function uses a post-order traversal, so it traverses "deep" into a node's child nodes first before writing the node using the visitor function. This is the same as the original DfaNode.Visit() function.
We're almost there now. We have a class that builds the endpoint node tree, traverses all the nodes in the tree, and runs a function for each. All that remains is to define the visitor function, WriteNode().
Defining a custom WriteNode function
We've finally got to the meaty part, controlling how the endpoint graph is displayed. All of the customisation and effort so far has been to enable us to customise the WriteNode function.
Our custom WriteNode() function is, again, almost the same as the original. There are two main differences:
The original graph writer works with DfaNodes, we have to convert to using the IDfaNode proxy.
The original graph writer uses the same styling for all nodes and edges. We customise the display of nodes and edges based on the configured GraphDisplayOptions.
As WriteNode is a local function, it can access variables from the enclosing function. This includes the writer parameter, used to write the graph to output and the visited dictionary of previously written nodes.
The following shows our (heavily commented) custom version of the WriteNode() method.
voidWriteNode(IDfaNode node){// add the node to the visited node dictionary if it isn't already// generate a zero-based integer label for the nodeif(!visited.TryGetValue(node,outvar label)){
label = visited.Count;
visited.Add(node, label);}// We can safely index into visited because this is a post-order traversal,// all of the children of this node are already in the dictionary.// If this node is linked to any nodes by a literal edgeif(node.Literals !=null){foreach(DictionaryEntry dictEntry in node.Literals){// Foreach linked node, get the label for the edge and the linked nodevar edgeLabel =(string)dictEntry.Key;IDfaNodevalue= dictEntry.Value.ActLike<IDfaNode>();int nodeLabel = visited[value];// Write an edge, including our custom styling for literal edges
writer.WriteLine($"{label} -> {nodeLabel} [label=\"/{edgeLabel}\" {_options.LiteralEdge}]");}}// If this node is linked to a nodes by a parameter edgeif(node.Parameters !=null){IDfaNode parameters = node.Parameters.ActLike<IDfaNode>();int nodeLabel = visited[catchAll];// Write an edge labelled as /* using our custom styling for parameter edges
writer.WriteLine($"{label} -> {nodeLabel} [label=\"/**\" {_options.CatchAllEdge}]");}// If this node is linked to a catch-all edgeif(node.CatchAll !=null&& node.Parameters != node.CatchAll){IDfaNode catchAll = node.CatchAll.ActLike<IDfaNode>();int nodeLabel = visited[catchAll];// Write an edge labelled as /** using our custom styling for catch-all edges
writer.WriteLine($"{label} -> {nodelLabel} [label=\"/**\" {_options.CatchAllEdge}]");}// If this node is linked to any Policy Edgesif(node.PolicyEdges !=null){foreach(DictionaryEntry dictEntry in node.PolicyEdges){// Foreach linked node, get the label for the edge and the linked nodevar edgeLabel =(object)dictEntry.Key;IDfaNodevalue= dictEntry.Value.ActLike<IDfaNode>();int nodeLabel = visited[value];// Write an edge, including our custom styling for policy edges
writer.WriteLine($"{label} -> {nodeLabel} [label=\"{key}\" {_options.PolicyEdge}]");}}// Does this node have any associated matches, indicating it generates a response?var matchCount = node?.Matches?.Count ??0;var extras = matchCount >0? _options.MatchingNode // If we have matches, use the styling for response-generating nodes...: _options.DefaultNode;// ...otherwise use the default style// Write the node to the graph output
writer.WriteLine($"{label} [label=\"{node.Label}\" {extras}]");}
Tracing the flow of these interactions can be a little confusing, because of the way we write the nodes from the "leaf" nodes back to the root of the tree. For example if we look at the output for the basic app shown at the start of this post, you can see the "leaf" endpoints are all written first: the healthz health check endpoint and the terminal match generating endpoints with the longest route:
Even though the leaf nodes are written to the graph output first, the Graphviz visualizer will generally draw the graph with the leaf nodes at the bottom, and the edges pointing down. You can visualize the graph online at https://dreampuf.github.io/GraphvizOnline/:
If you want to change how the graph is rendered you can customize the GraphDisplayOptions. If you use the "test" approach I described in a previous post, you can pass these options in directly when generating the graph. If you're using the "middleware" approach, you can register the GraphDisplayOptions using the IOptions<> system instead, and control the display using the configuration system.
Summary
In this post I showed how to create a custom DfaGraphWriter to control how an application's endpoint graph is generated. To interoperate with the internal classes we used ImpromptuInterface, as described in the previous post, to create proxies we can interact with. We then had to write a custom Visit() function to work with the IDfaNode proxies. Finally, we created a custom WriteNode function that uses custom settings defined in a GraphDisplayOptions object to display each type of node and edge differently.
In this series, I have shown how to view all the routes in your application using an endpoint graph. In this post I show how to do something more useful—detecting duplicate routes that would throw an exception at runtime. I show how to use the same DfaGraphWriter primitives as in previous posts to create a unit test that fails if you have any duplicate routes in your application that would cause a failure at runtime.
Duplicate routes and runtime exceptions
ASP.NET Core 3.x uses endpoint routing for all your MVC/API controllers and Razor Pages, as well as dedicated endpoints like a health check endpoint. As you've already seen in this series, those endpoints are built into a directed graph, which is used to route incoming requests to a handler:
Unfortunately, it's perfectly possible to structure your controllers/Razor Pages in such as way as to have multiple endpoints be a match for a given route. For example, imagine you have a "values" controller in your project:
As routing is only handled at runtime, everything will appear to be fine when you build and deploy your application. Health checks will pass, and all other routes will behave normally. But when someone hits the URL /api/values, you'll get this beauty:
The good thing here at least is that the error message tells you where the problem is. But wouldn't it be nice to know that before you've deployed to production?
Trying to detect this error ahead of time was what started me down the graph-drawing rabbit-hole of this series. My goal was to create a simple unit test that can run as part of the build, to identify errors like these.
Creating a duplicate endpoint detector
If you've read the rest of this series, then you may have already figured out how this is going to work. The DfaGraphWriter that is built-in to the framework, which can be used to visualize the endpoint graph, knows how to visit each node (route) in the graph. We'll adapt this somewhat: instead of outputting a graph, we'll return a list of routes which match multiple endpoints.
The bulk of the DuplicateEndpointDetector is identical to the CustomDfaGraphWriterfrom my previous post. The only difference is that we a GetDuplicateEndpoints() method instead of a Write() method. We also don't use a TextWriter (as we're not trying to build a graph for display) and we return a dictionary of duplicated endpoints (keyed on the route).
I've shown almost the complete code below, with the exception of the LogDuplicates method which we'll get to shortly.
publicclassDuplicateEndpointDetector{privatereadonlyIServiceProvider _services;publicDuplicateEndpointDetector(IServiceProvider services){
_services = services;}public Dictionary<string, List<string>>GetDuplicateEndpoints(EndpointDataSource dataSource){// Use ImpromptuInterface to create the required dependencies as shown in previous postType matcherBuilder =typeof(IEndpointSelectorPolicy).Assembly
.GetType("Microsoft.AspNetCore.Routing.Matching.DfaMatcherBuilder");// Build the list of endpoints used to build the graphvar rawBuilder = _services.GetRequiredService(matcherBuilder);IDfaMatcherBuilder builder = rawBuilder.ActLike<IDfaMatcherBuilder>();// This is the same logic as the original graph writervar endpoints = dataSource.Endpoints;for(var i =0; i < endpoints.Count; i++){if(endpoints[i]isRouteEndpoint endpoint &&(endpoint.Metadata.GetMetadata<ISuppressMatchingMetadata>()?.SuppressMatching ??false)==false){
builder.AddEndpoint(endpoint);}}// Build the raw tree from the registered routesvar rawTree = builder.BuildDfaTree(includeLabel:true);IDfaNode tree = rawTree.ActLike<IDfaNode>();// Store a list of nodes that have already been visited var visited =newDictionary<IDfaNode,int>();// Store a dictionary of duplicatesvar duplicates =newDictionary<string, List<string>>();// Build the graph by visiting each node, and calling LogDuplicates on eachVisit(tree, LogDuplicates);// donereturn duplicates;voidLogDuplicates(IDfaNode node){/* Details shown later in this post*/}}// Identical to the version shown in the previous poststaticvoidVisit(IDfaNode node, Action<IDfaNode> visitor){if(node.Literals?.Values !=null){foreach(var dictValue in node.Literals.Values){IDfaNodevalue= dictValue.ActLike<IDfaNode>();Visit(value, visitor);}}// Break cyclesif(node.Parameters !=null&&!ReferenceEquals(node, node.Parameters)){IDfaNode parameters = node.Parameters.ActLike<IDfaNode>();Visit(parameters, visitor);}// Break cyclesif(node.CatchAll !=null&&!ReferenceEquals(node, node.CatchAll)){IDfaNode catchAll = node.CatchAll.ActLike<IDfaNode>();Visit(catchAll, visitor);}if(node.PolicyEdges?.Values !=null){foreach(var dictValue in node.PolicyEdges.Values){IDfaNodevalue= dictValue.ActLike<IDfaNode>();Visit(value, visitor);}}visitor(node);}}
This class follows the same approach as the graph writer. It uses ImpromptuInterface to create an IDfaMatcherBuilder proxy, which it uses to build a graph of all the endpoints in the system. It then visits each of the IDfaNodes in the graph and calls the LogDuplicates() method, passing in each node in turn.
LogDuplicates() is a lot simpler than the WriteNode() implementation from the previous post. All we're concerned about here is whether a node has multiple entries in its Matches property. If it does, we have an ambiguous route, so we add it to the dictionary. I'm using the DisplayName to identify the ambiguous endpoints, just as the exception message shown earlier does.
// LogDuplicates is a local method. visited and duplicates are defined in the calling functionvar visited =newDictionary<IDfaNode,int>();var duplicates =newDictionary<string, List<string>>();voidLogDuplicates(IDfaNode node){// Add the node to the visited node dictionary if it isn't already// Generate a zero-based integer label for the nodeif(!visited.TryGetValue(node,outvar label)){
label = visited.Count;
visited.Add(node, label);}// We can safely index into visited because this is a post-order traversal,// all of the children of this node are already in the dictionary.// Does this node have multiple matches?var matchCount = node?.Matches?.Count ??0;if(matchCount >1){// Add the node to the dictionary!
duplicates[node.Label]= node.Matches.Select(x => x.DisplayName).ToList();}}
After executing GetDuplicateEndpoints() you'll have a dictionary containing all the duplicate routes in your application. The final thing to do is create a unit test, so that we can fail the build if we detect a problem.
Creating a unit test to detect duplicate endpoints
I like to put this check in a unit test, because performance is much less of an issue. You could check for duplicate routes on app startup or using a health check But given that we use reflection heavily this will add to startup time, and also given that the routes are fixed once you deploy your application, a unit test seems like the best place for it.
Create a new xUnit project using VS or by running dotnet new xunit.
Install Microsoft.AspNetCore.Mvc.Testing by running dotnet add package Microsoft.AspNetCore.Mvc.Testing
Update the <Project> element of your test project to <Project Sdk="Microsoft.NET.Sdk.Web">
Reference your ASP.NET Core project from the test project
You can now create a simple integration test using the WebApplicationFactory<> as a class fixture. I also inject ITestOutputHelper so that we can list out the duplicate endpoints for the test:
publicclassDuplicateDetectorTest:IClassFixture<WebApplicationFactory<ApiRoutes.Startup>>{// Inject the factory and the output helperprivatereadonly WebApplicationFactory<ApiRoutes.Startup> _factory;privatereadonlyITestOutputHelper _output;publicDuplicateDetectorTest(WebApplicationFactory<Startup> factory,ITestOutputHelper output){
_factory = factory;
_output = output;}[Fact]publicvoidShouldNotHaveDuplicateEndpoints(){// Create an instance of the detector using the IServiceProvider from the app// and get an instance of the endpoint datavar detector =newDuplicateEndpointDetector(_factory.Services);var endpointData = _factory.Services.GetRequiredService<EndpointDataSource>();// Find all the duplicatesvar duplicates = detector.GetDuplicateEndpoints(endpointData);// Print the duplicates to the outputforeach(var keyValuePair in duplicates){var allMatches =string.Join(", ", keyValuePair.Value);
_output.WriteLine($"Duplicate route: '{keyValuePair.Key}'. Matches: {allMatches}");}// If we have some duplicates, then fail the CI build!
Assert.Empty(duplicates);}}
When you run the test, the assertion will fail, and if you view the output, you'll see a list of the routes with issues, as well as the endpoints that caused the problem:
If you're running your unit tests as part of your CI build, then you'll catch the issue before it gets to production. Pretty handy!
Summary
In this post I show how you can build a duplicate endpoint detector using the endpoint graph building facilities included in ASP.NET Core. The end result requires quite a few tricks, as I've shown in the previous posts of this series, such as using ImpromptuInterface to create proxies for interacting with internal types.
The end result is that you can detect when multiple endpoints (e.g. API controllers) are using the same route in your application. Given that those throw routes would throw an AmbiguousMatchException at runtime, being able to detect issues using a unit test is pretty handy!
In this post I take a look at the code in the default implementation of IHttpClientFactory in ASP.NET Core—DefaultHttpClientFactory. We'll see how it ensures that HttpClient instances created with the factory prevent socket exhaustion, while also ensuring that DNS changes are respected.
I've taken a couple of liberties with the code by removing null checks, in-lining some trivial methods, and removing some code that's tangential to this discussion. For the original code, see GitHub.
A brief overview of IHttpClientFactory
IHttpClientFactory allows you to create HttpClient instances for interacting with HTTP APIs, using best practices to avoid common issues. Before IHttpClientFactory, it was common to fall into one of two traps when creating HttpClient instances:
Create and dispose of new HttpClient instances as required. This can lead to socket exhaustion due to the TIME_WAIT period required after closing a connection.
IHttpClientFactory was added in .NET Core 2.1, and solves this issue by separating the management of HttpClient, from the the HttpMessageHandler chain that is used to send the message. In reality, it is the lifetime of the HttpClientHandler at the end of the pipeline that is the important thing to manage, as this is the handler that actually makes the connection
In addition to simply managing the handler lifetimes, IHttpClientFactory also makes it easy to customise the generated HttpClient and message handler pipeline using an IHttpClientBuilder. This allows you to "pre-configure" a named of typed HttpClient that is created using the factory, for example to set the base address or add default headers:
publicvoidConfigureServices(IServiceCollection services){
services.AddHttpClient("github", c =>{
c.BaseAddress =newUri("https://api.github.com/");}).ConfigureHttpClient(c =>{
c.DefaultRequestHeaders.Add("Accept","application/vnd.github.v3+json");
c.DefaultRequestHeaders.Add("User-Agent","HttpClientFactory-Sample");});}
You can add multiple configuration functions at the HttpClient level, but you can also add additional HttpMessageHandlers to the pipeline. Steve shows how you can create your own handlers in in his series. To add message handlers to a named client, use IHttpClientBuilder.AddHttpMessageHandler<>, and register the handler with the DI container:
publicvoidConfigureServices(IServiceCollection services){
services.AddHttpClient("github", c =>{
c.BaseAddress =newUri("https://api.github.com/");}).AddHttpMessageHandler<TimingHandler>()// This handler is on the outside and executes first on the way out and last on the way in..AddHttpMessageHandler<ValidateHeaderHandler>();// This handler is on the inside, closest to the request.// Add the handlers to the service collection
services.AddTransient<TimingHandler>();
services.AddTransient<ValidateHeaderHandler>();}
When you call ConfigureHttpClient() or AddHttpMessageHandler() to configure your HttpClient, you're actually adding configuration messages to a named IOptions instance, HttpClientFactoryOptions. You can read more about named options here, but the details aren't too important for this post.
That handles configuring the IHttpClientFactory. To use the factory, and create an HttpClient, you first obtain an instance of the singleton IHttpClientFactory, and then you call CreateClient(name), providing the name of the client to create.
If you don't provide a name to CreateClient(), the factory will use the default name, "" (the empty string).
publicclassMyService{// IHttpClientFactory is a singleton, so can be injected everywhereprivatereadonlyIHttpClientFactory _factory;publicMyService(IHttpClientFactory factory){
_factory = factory;}publicasyncTaskDoSomething(){// Get an instance of the typed clientHttpClient client = _factory.CreateClient("github");// Use the client...}}
The remainder of this post focus on what happens behind the scenes when you call CreateClient().
Creating an HttpClient and HttpMessageHandler
The CreateClient() method, shown below, is how you typically interact with the IHttpClientFactory. I discuss this method below.
// Injected in constructorprivatereadonly IOptionsMonitor<HttpClientFactoryOptions> _optionsMonitor
publicHttpClientCreateClient(string name){HttpMessageHandler handler =CreateHandler(name);var client =newHttpClient(handler, disposeHandler:false);HttpClientFactoryOptions options = _optionsMonitor.Get(name);for(int i =0; i < options.HttpClientActions.Count; i++){
options.HttpClientActions[i](client);}return client;}
This is a relatively simple method on the face of it. We start by creating the HttpMessageHandler pipeline by calling CreateHandler(name), and passing in the name of the client to create. We'll look into that method shortly, as it's where most of the magic happens around handler pooling and lifetimes.
Once you have a handler, a new instance of HttpClient is created and passed to the handler. The important thing to note is the disposeHandler: false argument. This ensures that disposing the HttpClientdoesn't dispose the handler pipeline, as the IHttpClientFactory will handle that itself.
Finally, the latest HttpClientFactoryOptions for the named client are fetched from the IOptionsMonitor instance. This contains the configuration functions for the HttpClient that were added in Startup.ConfigureServices(), and sets things like the BaseAddress and default headers.
I discussed using IOptionsMonitor in a previous post. It is useful when you want to load named options in a singleton context, where you can't use the simpler IOptionsSnapshot interface. It also has other change-detection capabilities that aren't used in this case.
Finally, the HttpClient is returned to the caller. Let's look at the CreateHandler() method now and see how the HttpMessageHandler pipeline is created. There's quite a few layers to get through, so we'll walk through it step-by-step.
// Created in the constructorreadonly ConcurrentDictionary<string, Lazy<ActiveHandlerTrackingEntry>> _activeHandlers;;readonly Func<string, Lazy<ActiveHandlerTrackingEntry>> _entryFactory =(name)=>{returnnewLazy<ActiveHandlerTrackingEntry>(()=>{returnCreateHandlerEntry(name);}, LazyThreadSafetyMode.ExecutionAndPublication);};publicHttpMessageHandlerCreateHandler(string name){ActiveHandlerTrackingEntry entry = _activeHandlers.GetOrAdd(name, _entryFactory).Value;
entry.StartExpiryTimer(_expiryCallback);return entry.Handler;}
The CreateHandler() method does two things:
It gets or creates an ActiveHandlerTrackingEntry
It stars a timer on the entry
The _activeHandlers field is a ConcurrentDictionary<>, keyed on the name of the client (e.g. "gitHub"). The dictionary values are Lazy<ActiveHandlerTrackingEntry>. Using Lazy<> here is a neat trick I've blogged about previously to make the GetOrAdd function thread safe. The job of actually creating the handler occurs in CreateHandlerEntry (which we'll see shortly) which creates an ActiveHandlerTrackingEntry.
The ActiveHandlerTrackingEntry is mostly an immutable object containing an HttpMessageHandler and a DI IServiceScope. In reality it also contains an internal timer that is used with the StartExpiryTimer() method to call the provided callback when the timer of length Lifetime expires.
internalclassActiveHandlerTrackingEntry{publicLifetimeTrackingHttpMessageHandler Handler {get;privateset;}publicTimeSpan Lifetime {get;}publicstring Name {get;}publicIServiceScope Scope {get;}publicvoidStartExpiryTimer(TimerCallback callback){// Starts the internal timer// Executes the callback after Lifetime has expired.// If the timer has already started, is noop}}
So the CreateHandler method either creates a new ActiveHandlerTrackingEntry, or retrieves the entry from the dictionary, and starts the timer. In the next section we'll look at how the CreateHandlerEntry() method creates the ActiveHandlerTrackingEntry instances:
Creating and tracking HttpMessageHandlers in CreateHandlerEntry
The CreateHandlerEntry method is where the HttpClient handler pipelines are created. It's a somewhat complex method, so I'll show it first, and then talk through it afterwards. The version shown below is somewhat simplified compared to the real version, but it maintains all the salient points.
// The root service provider, injected into the constructor using DIprivatereadonlyIServiceProvider _services;// A collection of IHttpMessageHandler "configurers" that are added to every handler pipelineprivatereadonly IHttpMessageHandlerBuilderFilter[] _filters;privateActiveHandlerTrackingEntryCreateHandlerEntry(string name){IServiceScope scope = _services.CreateScope();IServiceProvider services = scope.ServiceProvider;HttpClientFactoryOptions options = _optionsMonitor.Get(name);HttpMessageHandlerBuilder builder = services.GetRequiredService<HttpMessageHandlerBuilder>();
builder.Name = name;// This is similar to the initialization pattern in:// https://github.com/aspnet/Hosting/blob/e892ed8bbdcd25a0dafc1850033398dc57f65fe1/src/Microsoft.AspNetCore.Hosting/Internal/WebHost.cs#L188
Action<HttpMessageHandlerBuilder> configure = Configure;for(int i = _filters.Length -1; i >=0; i--){
configure = _filters[i].Configure(configure);}configure(builder);// Wrap the handler so we can ensure the inner handler outlives the outer handler.var handler =newLifetimeTrackingHttpMessageHandler(builder.Build());returnnewActiveHandlerTrackingEntry(name, handler, scope, options.HandlerLifetime);voidConfigure(HttpMessageHandlerBuilder b){for(int i =0; i < options.HttpMessageHandlerBuilderActions.Count; i++){
options.HttpMessageHandlerBuilderActions[i](b);}}}
There's quite a lot to unpack here. The method starts by creating a new IServiceScope using the root DI container. This creates a DI scope, so that scoped services can be sourced from the associated IServiceProvider. We also retrieve the HttpClientFactoryOptions for the requested HttpClient name, which contains the specific handler configuration for this instance.
The next item retrieved from the container is an HttpMessageHandlerBuilder, which by default is a DefaultHttpMessageHandlerBuilder. This is used to build the handler pipeline, by creating a "primary" handler, which is the HttpClientHandler that is responsible for making the socket connection and sending the request. You can add additional DelegatingHandlers that wrap the primary server, creating a pipeline for requests and responses.
The DelegatingHandlers are added to the builder using a slightly complicated arrangement, that is very reminiscent of how the middleware pipeline in an ASP.NET Core app is built:
The Configure() local method builds a pipeline of DelegatingHandlers, based on the configuration you provided in Startup.ConfigureServices().
IHttpMessageHandlerBuilderFilter are filters that are injected into the IHttpClientFactory constructor. They are used to add additional handlers into the DelegatingHandler pipeline.
IHttpMessageHandlerBuilderFilter are directly analogous to the IStartupFilters used by the ASP.NET Core middleware pipeline, which I've talked about previously. A single IHttpMessageHandlerBuilderFilter is registered by default, the LoggingHttpMessageHandlerBuilderFilter. This filter adds two additional handlers to the DelegatingHandler pipeline:
LoggingScopeHttpMessageHandler at the start (outside) of the pipeline, which starts a new logging scope.
A LoggingHttpMessageHandler at the end (inside) of the pipeline, just before the request is sent to the primary HttpClientHandler, which records logs about the request and response.
The code (and probably my description) for CreateHandlerEntry is definitely somewhat hard to follow, but the end result for an HttpClient configured with two custom handlers (as demonstrated at the start of this post) is a handler pipeline that looks something like the following:
Once the handler pipeline is complete, it is saved in a new ActiveHandlerTrackingEntry instance, along with the DI IServiceScope used to create it, and given the lifetime defined in HttpClientFactoryOptions (two minutes by default).
This entry is returned to the caller (the CreateHandler() method), added to the ConcurrentDictionary<> of handlers, added to a new HttpClient instance (in the CreateClient() method), and returned to the original caller.
For the next two minutes, every time you call CreateClient(), you will get a new instance of HttpClient, but which has the same handler pipeline as was originally created.
Each named or typed client gets its own message handler pipeline. i.e. two instances of the "github" named client will have the same handler chain, but the "api" named client would have a different handler chain.
The next challenge is cleaning up and disposing the handler chain once the two minute timer has expired. This requires some careful handling, as you'll see in the next section.
Cleaning up expired handlers.
After two minutes, the timer stored in the ActiveHandlerTrackingEntry entry will expire, and fire the callback method passed into StartExpiryTimer(): ExpiryTimer_Tick().
ExpiryTimer_Tick is responsible for removing the active handler entry from the ConcurrentDictionary<> pool, and adding it to a queue of expired handlers:
// Created in the constructorreadonly ConcurrentQueue<ExpiredHandlerTrackingEntry> _expiredHandlers;// The Timer instance in ActiveHandlerTrackingEntry calls this when it expiresinternalvoidExpiryTimer_Tick(object state){var active =(ActiveHandlerTrackingEntry)state;
_activeHandlers.TryRemove(active.Name,out Lazy<ActiveHandlerTrackingEntry> found);var expired =newExpiredHandlerTrackingEntry(active);
_expiredHandlers.Enqueue(expired);StartCleanupTimer();}
Once the active handler is removed from the _activeHandlers collection, it will no longer be handed out with new HttpClients when your call CreateClient(). But there are potentially HttpClients out there which are still using the active handler. The IHttpClientFactory has to wait for all the HttpClient instances that reference this handler to be cleaned up before it can dispose the handler pipeline.
The problem is, how can IHttpClientFactory track that the handler is no longer referenced? The key is the use of the "noop" LifetimeTrackingHttpMessageHandler, and the ExpiredHandlerTrackingEntry.
The ExpiredHandlerTrackingEntry, shown below, creates a WeakReference to the LifetimeTrackingHttpMessageHandler. As I showed in the previous section, the LifetimeTrackingHttpMessageHandler is the "outermost" handler in the chain, so it is the handler that is directly referenced by the HttpClient.
internalclassExpiredHandlerTrackingEntry{privatereadonlyWeakReference _livenessTracker;// IMPORTANT: don't cache a reference to `other` or `other.Handler` here.// We need to allow it to be GC'ed.publicExpiredHandlerTrackingEntry(ActiveHandlerTrackingEntry other){
Name = other.Name;
Scope = other.Scope;
_livenessTracker =newWeakReference(other.Handler);
InnerHandler = other.Handler.InnerHandler;}publicbool CanDispose =>!_livenessTracker.IsAlive;publicHttpMessageHandler InnerHandler {get;}publicstring Name {get;}publicIServiceScope Scope {get;}}
Using WeakReference to the LifetimeTrackingHttpMessageHandler means that the only direct references to the outermost handler in the chain are in HttpClients. Once all these HttpClients have been collected by the garbage collector, the LifetimeTrackingHttpMessageHandler will have no references, and so will also be disposed. The ExpiredHandlerTrackingEntry can detect that via the WeakReference.IsAlive property.
Note that the ExpiredHandlerTrackingEntrydoes maintain a reference to the rest of the handler pipeline, so that it can properly dispose the inner handler chain, as well as the DI IServiceScope.
After an entry is added to the _expiredHandlers queue, a timer is started by StartCleanupTimer() which fires after 10 seconds. This calls the CleanupTimer_Tick() method, which checks to see whether all the references to the handler have expired. If so, the handler chain and IServiceScope are disposed. If not, they are added back onto the queue, and the clean-up timer is started again:
internalvoidCleanupTimer_Tick(){// Stop any pending timers, we'll restart the timer if there's anything left to process after cleanup.StopCleanupTimer();// Loop through all the timersint initialCount = _expiredHandlers.Count;for(int i =0; i < initialCount; i++){
_expiredHandlers.TryDequeue(outExpiredHandlerTrackingEntry entry);if(entry.CanDispose){// All references to the handler chain have been removedtry{
entry.InnerHandler.Dispose();
entry.Scope?.Dispose();}catch(Exception ex){// log the exception}}else{// If the entry is still live, put it back in the queue so we can process it// during the next cleanup cycle.
_expiredHandlers.Enqueue(entry);}}// We didn't totally empty the cleanup queue, try again later.if(_expiredHandlers.Count >0){StartCleanupTimer();}}
The method presented above is pretty simple - it loops through each of the ExpiredHandlerTrackingEntry entries in the queue, and checks if all references to the LifetimeTrackingHttpMessageHandler handlers have been removed. If they have, the handler chain (everything that was inside the lifetime tracking handler) is disposed, as is the DI IServiceScope.
If there are still live references to any of the LifetimeTrackingHttpMessageHandler handlers, the entries are put back in the queue, and the cleanup timer is started again. Every 10 seconds another cleanup sweep is run.
I simplified the CleanupTimer_Tick() method shown above compared to the original. The original adds additional logging, and uses locking to ensure only a single thread runs the cleanup at a time.
That brings us to the end of this deep dive in the internals of IHttpClientFactory! IHttpClientFactory shows the correct way to manage HttpClient and HttpMessageHandlers in your application. Having read through the code, it's understandable that noone got this completely right for so long - there's a lot of tricky gotchas there! If you've made it this far, I suggest going and looking through the original code, I highlighted (what I consider) the most important points in this post, but you can learn a lot from reading other people's code!
Summary
In this post I looked at the source code behind the default IHttpClientFactory implementation in .NET Core 3.1, DefaultHttpClientFactory. I showed how the factory stores an active HttpMessageHandler pipeline for each configured named or typed client, with each new HttpClient getting a reference to the same pipeline. I showed that the handler pipeline is built in a similar way to the ASP.NET Core middleware pipeline, using handlers. Finally, I showed how the factory tracks whether any HttpClients reference a pipeline instance by using a WeakReference to the handler.
In this post I discuss how dependency injection scopes work in the context of IHttpClientFactory. The title of this post reflects the fact that they don't work like I previously expected them to!
In this post I look at how dependency injection scopes work when you're using IHttpClientFactory, how they relate to the "typical" request-based DI scope used in ASP.NET Core, and the implications of that for custom message handler implementations.
We'll start with a very brief overview of IHttpClientFactory and DI scopes, and then look at how the two interact.
Why use IHttpClientFactory?
IHttpClientFactory allows you to create HttpClient instances for interacting with HTTP APIs, using best practices to avoid common issues related to socket exhaustion and not respecting DNS settings. It does this by managing the HttpMessageHandler chain separately from the HttpClient instances.
You can read about howIHttpClientFactory achieves this in my previous post but in brief:
IHttpClintFactory creates an HttpMessageHandler pipeline for each "named" client
After 2 minutes, the IHttpClientFactory creates a new HttpMessageHandler pipeline and uses that for new HttpClient instances.
Once the HttpClient instances referencing an "expired" handler pipeline have all been collected by the garbage collector, the pipeline is disposed.
IHttpClientFactory also makes it easy to add additional handlers to the handler pipeline.
That's obviously a very brief summary, but if you're not already familiar with IHttpClientFactory, I suggest reading Steve Gordon's series first.
To continue setting the scene, we'll take a brief look at dependency injection scopes.
Dependency Injection scopes and the request scope
In ASP.NET Core, services can be registered with the dependency injection (DI) container with one of three lifetimes:
Singleton: A single instance of the service is used throughout the lifetime of the application. All requests for the service return the same instance.
Scoped: Within a defined "scope", all requests for the service return the same instance. Requests from different scopes will return different instances.
Transient: A new instance of the service is created every time it is requested. Every request for the service returns a different instance.
Singleton and transient are the simplest, as they take the lifetime of a component to an extreme. Scoped is slightly more complex, as the behaviour varies depending on whether you are in the context of the same scope.
The pseudo code below demonstrates this - it won't compile, but hopefully you get the idea.
The main question is when are those scopes created?
In ASP.NET Core, a new scope is created for each request. So each request uses a different instance of a scoped service.
A common example of this is EF Core's DbContext - the same instance of this class is used throughout a request, but a different instance is used between requests.
This is by far the most common way to interact with scopes in ASP.NET Core. But there are special cases where you need to "manually" create scopes, when you are executing outside of the context of a request. For example:
It's generally pretty apparent when you're running into an issue like this, as you're trying to access scoped services from a singleton context.
Where things really get interesting is when you're consuming services from scopes with overlapping lifetimes. That sounds confusing, but it's something you'll need to get your head around if you create custom HttpMessageHandlers for IHttpClientFactory!
HttpMessageHandler lifetime in IHttpClientFactory
As we've already discussed, IHttpClientFactory manages the lifetime of your HttpMessageHandler pipeline separately from the HttpClient instances. HttpClient instances are created new every time, but for the 2 minutes before a handler expires, every HttpClient with a given name uses the same handler pipeline.
I've really emphasised that, as it's something I didn't understand from the documentation and previous posts on IHttpClientFactory. The documentation constantly talks about a "pool" of handlers, but that feels a bit misleading to me - there's only a single handler in the "pool" used to create new instances of HttpClient. That's not what I think of as a pool!
My assumption was that a "pool" of available handlers were maintained, and that IHttpClientFactory would hand out an unused handler from this pool to new instances of HttpClient.
That is not the case.
A single handler pipeline will be reused across multiple calls to CreateClient(). After 2 minutes, this handler is "expired", and so is no longer handed out to new HttpClients. At that point, you get a new active handler, that will be used for all subsequent CreateClient() calls. The expired handler is moved to a queue for clean up once it is no longer in use.
The fact that the handler pipeline is shared between multiple HttpClient instances isn't a problem in terms of thread safety—after all, the advice prior to IHttpClientFactory was to use a single HttpClient for your application. Where things get interesting is the impact this has on DI scopes, especially if you're writing your own custom HttpMessageHandlers.
Scope duration in IHttpClientFactory
This brings us to the crux of this post—the duration of a DI scope with IHttpClintFactory.
Remember, for 2 minutes, the same handler pipeline will be used for all calls to CreateClient() for a given named handler. That applies across all requests, even though each request uses it's own DI scope for the purpose of retrieving services. The DI scope for the handler pipeline is completely separate to the DI scope for the request.
This was something I hadn't given much though to, given my previous misconceptions of the "pool" of handler pipelines. The next question is: does this cause us any problems? The answer (of course) is "it depends".
Before we get to that, I'll provide a concrete example demonstrating the behaviour above.
An example of unexpected (for me) scoped service behaviour in IHttpClientFactory
Lets imagine you have some "scoped" service, that returns an ID. Each instance of the service should always return the same ID, but different instances should return different IDs. For example:
You also have a custom HttpMessageHandler. Steve discusses custom handlers in his series, so I'll just present a very basic handler below which uses the ScopedService defined above, and logs the InstanceId:
publicclassScopedMessageHander:DelegatingHandler{privatereadonly ILogger<ScopedMessageHander> _logger;privatereadonlyScopedService _service;publicScopedMessageHander(ILogger<ScopedMessageHander> logger,ScopedService service)){
_logger = logger;
_service = service;}protectedoverride Task<HttpResponseMessage>SendAsync(HttpRequestMessage request,CancellationToken cancellationToken){// Constant across instancesvar instanceId = scopedService.InstanceId;
_logger.LogInformation("Service ID in handler: {InstanceId}",);returnbase.SendAsync(request, cancellationToken);}}
Next, we'll add a namedHttpClient client in ConfigureServices(), and add our custom handler to its handler pipeline. You also have to register the ScopedMessageHandler as a service in the container explicitly, along with the ScopedService implementation:
publicvoidConfigureServices(IServiceCollection services){// Register the scoped services and add API controllers
services.AddControllers();
services.AddScoped<ScopedService>();// Add a typed client that fetches some dummy JSON
services.AddHttpClient("test", client =>{
client.BaseAddress =newUri("https://jsonplaceholder.typicode.com");})// Add our custom handler to the "test" handler pipeline.AddHttpMessageHandler<ScopedMessageHander>();// Register the message handler with the pipeline
services.AddTransient<ScopedMessageHander>();}
Finally, we have an API controller to test the behaviour. The controller below does two things:
Uses an injected ScopedService, and logs the instance's ID
Uses IHttpClientFactory to retrieve the named client"test", and sends a GET request. This executes the custom handler in the pipeline, logging its injected ScopedService instance ID.
[ApiController]publicclassValuesController:ControllerBase{privatereadonlyIHttpClientFactory _factory;privatereadonlyScopedService _service;privatereadonly ILogger<ValuesController> _logger;publicValuesController(IHttpClientFactory factory,ScopedService service, ILogger<ValuesController> logger){
_factory = factory;
_service = service;
_logger = logger;}[HttpGet("values")]publicasync Task<string>GetAsync(){// Get the scoped service's IDvar instanceId = _service.InstanceId
_logger.LogInformation("Service ID in controller {InstanceId}", instanceId);// Retrieve an instance of the test client, and send a requestvar client = _factory.CreateClient("test");var result =await client.GetAsync("posts");// Just return a response, we're not interested in this bit for now
result.EnsureSuccessStatusCode();returnawait result.Content.ReadAsStringAsync();}}
All this setup is designed to demonstrate the relationship between different ScopedServices. Lets take a look at the logs when we make two requests in quick succession
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
# Request 1
info: ScopedHandlers.Controllers.ValuesController[0]
Service ID in controller d553365d-2799-4618-ad3a-2a4b7dcbf15e
info: ScopedHandlers.ScopedMessageHander[0]
Service ID in handler: 5c6b1b75-7f86-4c4f-9c90-23c6df65d6c6
# Request 2
info: ScopedHandlers.Controllers.ValuesController[0]
Service ID in controller af64338f-8e50-4a1f-b751-9f0be0bbad39
info: ScopedHandlers.ScopedMessageHander[0]
Service ID in handler: 5c6b1b75-7f86-4c4f-9c90-23c6df65d6c6
As expected for a scoped service, the "Service ID in controller" log message changes with each request. The DI scope lasts for the length of the request: each request uses a different scope, so a new ScopedService is injected each request.
However, the ScopedService in the ScopedMessageHander is the same across both requests, and it's different to the ScopedService injected into the ValuesController. That's what we expect based on the discussion in the previous section, but it's not what I expected when I first started looking into this!
After two minutes, if we send another request, you'll see the "Service ID in handler" has changed. The handler pipeline from previous requests expired, and a new handler pipeline was created:
# Request 3
info: ScopedHandlers.Controllers.ValuesController[0]
Service ID in controller eaa8a393-e573-48c9-8b26-9b09b180a44b
info: ScopedHandlers.ScopedMessageHander[0]
Service ID in handler: 09ccb005-6434-4884-bc2d-6db7e0868d93
So, the question is: does it matter?
Does having mis-matched scopes matter?
The simple answer is: probably not.
If any of the following are true, then there's nothing to worry about:
No custom handlers. If you're not using custom HttpMessageHandlers, then there's nothing to worry about.
Stateless. If your custom handlers are stateless, as the vast majority of handlers will be, then the lifetime of the handler doesn't matter.
Static dependencies. Similarly, if the handler only depends on static (singleton) dependencies, then the lifetime of the handler doesn't matter here
Doesn't need to share state with request dependencies. Even if your handler requires non-singleton dependencies, as long as it doesn't need to share state with dependencies used in a request, you'll be fine.
The only situation I think you could run into issues is:
Requires sharing dependencies with request. If your handler requires using the same dependencies as the request in which it's invoked, then you could have problems.
The main example I can think of is EF Core.
A common pattern for EF Core is a "unit of work", that creates a new EF Core DbContext per request, does some work, and then persists those changes at the end of the request. If your custom handler needs to coordinate with the unit of work, then you could have problems unless you do extra work.
For example, imagine you have a custom handler that writes messages to an EF Core table. If you inject a DbContext into the custom handler, it will be a different instance of the DbContext than the one in your request. Additionally, this DbContext will last for the lifetime of the handler (2 minutes), not the short lifetime of a request.
So if you're in that situation, what should you do?
Accessing the Request scope from a custom HttpMessageHandler
Luckily, there is a solution. To demonstrate, I'll customise the ScopedMessageHander shown previously, so that the ScopedService it uses comes from the request's DI scope, instead of the DI scope used to create the custom handler. The key, is using IHttpContextAccessor.
Note that you have to add services.AddHttpContextAccessor() in your Startup.ConfigureServices() method to make IHttpContextAccessor available;
publicclassScopedMessageHander:DelegatingHandler{privatereadonly ILogger<ScopedMessageHander> _logger;privatereadonlyIHttpContextAccessor _accessor;publicScopedMessageHander(ILogger<ScopedMessageHander> logger,IHttpContextAccessor accessor){
_logger = logger;
_accessor = accessor;}protectedoverride Task<HttpResponseMessage>SendAsync(HttpRequestMessage request,CancellationToken cancellationToken){// The HttpContext will be null if used outside a request context, so check in practice!var httpConext = _accessor.HttpContext;// retrieve the service from the Request DI Scopevar service = _accessor.HttpContext.RequestServices.GetRequiredService<ScopedService>();// The same scoped instance used in the controllervar instanceId = service.InstanceId;
_logger.LogInformation("Service ID in handler: {InstanceId}",);returnbase.SendAsync(request, cancellationToken);}}
This approach uses the IHttpContextAccessor to retrieve the IServiceProvider that is scoped to the request. This allows you to retrieve the same instance that was injected into the ValuesController. Consequently, for every request, the logged values are the same in both the controller and the handler:
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
# Request 1
info: ScopedHandlers.Controllers.ValuesController[0]
Service ID in controller eaa8a393-e573-48c9-8b26-9b09b180a44b
info: ScopedHandlers.ScopedMessageHander[0]
Service ID in handler: eaa8a393-e573-48c9-8b26-9b09b180a44b
# Request 2
info: ScopedHandlers.Controllers.ValuesController[0]
Service ID in controller c5c3087b-938d-4e11-ae49-22072a56cef6
info: ScopedHandlers.ScopedMessageHander[0]
Service ID in handler: c5c3087b-938d-4e11-ae49-22072a56cef6
Even though the lifetime of the handler doesn't match the lifetime of the request, you can still execute the handler using services sourced from the same DI scope. This should allow you to work around any scoping issues you run into.
Summary
In this post I described how DI scopes with IHttpClientFactory. I showed that handlers are sourced from their own scope, which is separate from the request DI scope, which is typically where you consider scopes to be sourced from.
In most cases, this won't be a problem, but if an HttpMessageHandler requires using services from the "main" request then you can't use naïve constructor injection. Instead, you need to use IHttpContextAccessor to access the current request's HttpContext and IServiceProvider.

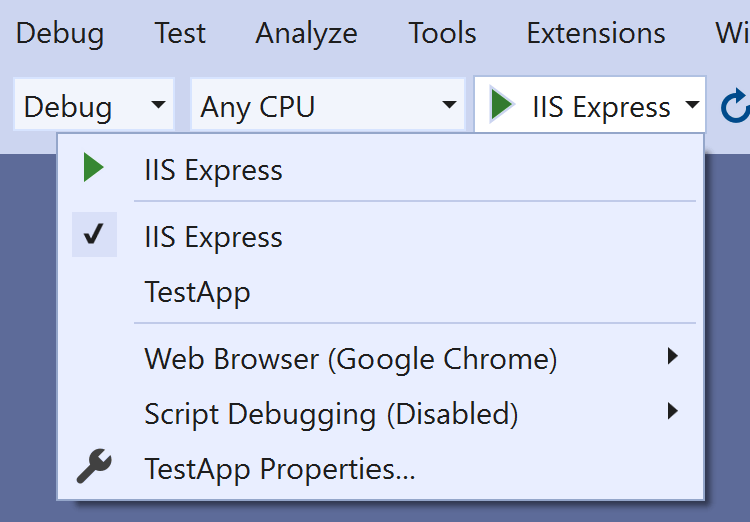













































 .
.