ASP.NET Core 3.0 re-platformed the WebHostBuilder on top of the generic IHost abstraction, so that Kestrel runs in an IHostedService. Any IHostedService implementations you add to Startup.ConfigureServices() are started before the GenericWebHostService that runs Kestrel. But what if you need to start your IHostedService after the middleware pipeline has been created, and your application is handling requests?
In this post I show how to add an IHostedService to your application so that it runs after the GenericWebHostSevice. This only applies to ASP.NET Core 3.0+, which uses the generic web host, not to ASP.NET Core 2.x and below.
tl;dr; As described in the documentation, you can ensure your
IHostedServiceruns after theGenericWebHostSeviceby adding an additionalConfigureServices()to theIHostBuilderin Program.cs, afterConfigureWebHostDefaults().
The generic IHost starts your IHostedServices first
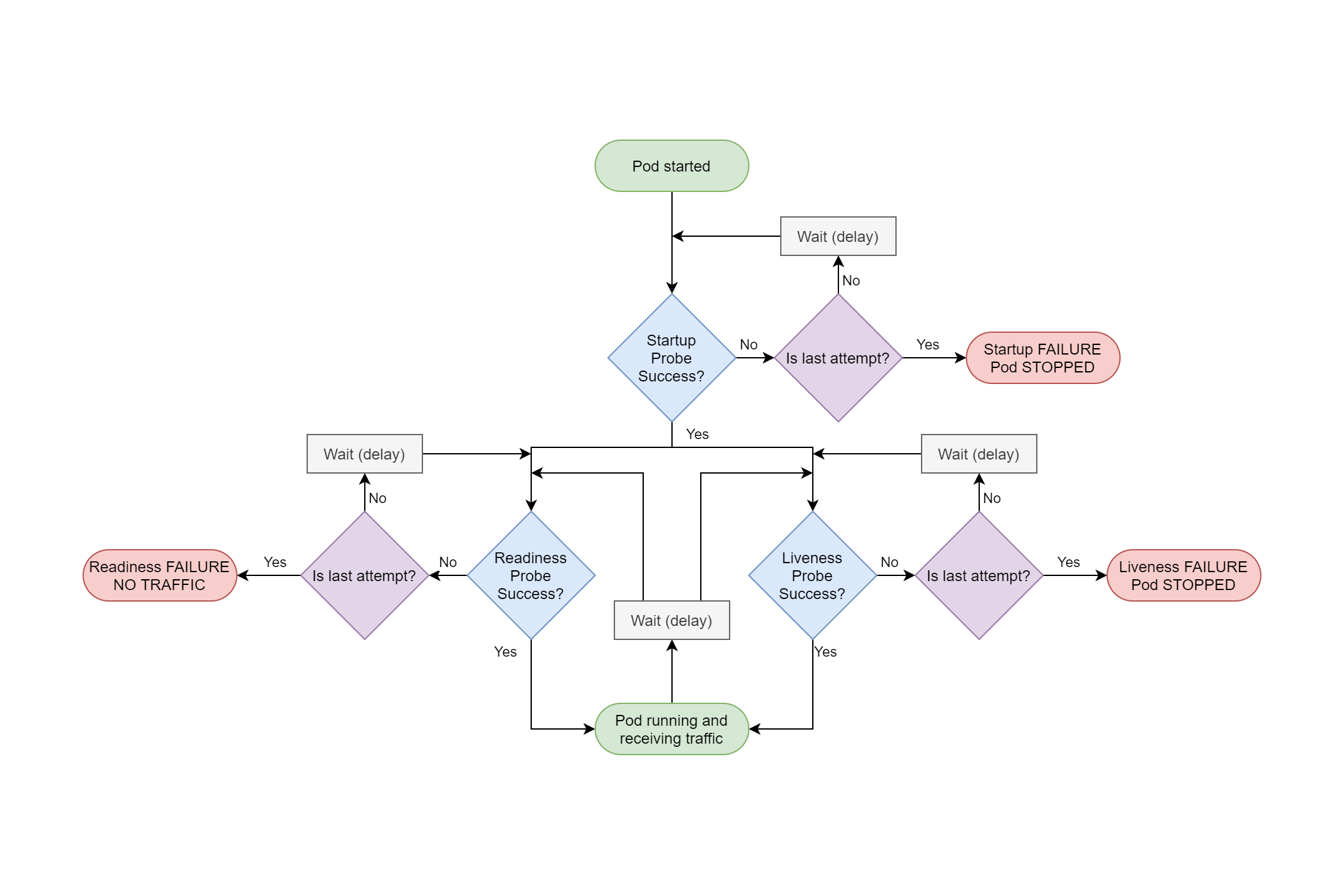
I've discussed the ASP.NET Core 3.x startup process in detail in a previous post, so I won't cover it again here other than to repeat the following image:

This shows the startup sequence when you call RunAsync() on IHost (which in turn calls StartAsync()). The important parts for our purposes are the IHostedServices that are started As you can see from the above diagram, your custom IHostedServices are started before the GenericWebHostSevice that starts the IServer (Kestrel) and starts handling requests.
You can see an example of this by creating a very basic IHostedServer implementation:
public class StartupHostedService : IHostedService
{
private readonly ILogger _logger;
public StartupHostedService(ILogger<StartupHostedService> logger)
{
_logger = logger;
}
public Task StartAsync(CancellationToken cancellationToken)
{
_logger.LogInformation("Starting IHostedService registered in Startup");
return Task.CompletedTask;
}
public Task StopAsync(CancellationToken cancellationToken)
{
_logger.LogInformation("StoppingIHostedService registered in Startup");
return Task.CompletedTask;
}
}
And add it to Startup.cs:
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddHostedService<StartupHostedService>();
}
}
When you run your application, you'll see your IHostedService write its logs before Kestrel runs it's configuration, and logs the ports it's listening on:
info: HostedServiceOrder.StartupHostedService[0] # Our IHostedService
Starting IHostedService registered in Startup
info: Microsoft.Hosting.Lifetime[0] # The GenericWebHostSevice
Now listening on: http://localhost:5000
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
As expected, our IHostedService executes first, followed by the GenericWebHostSevice. The ApplicationLifetime event fires after all the IHostedServices have executed. No matter where you register your IHostedService in Startup.ConfigureServices(), the GenericWebHostSevice will always fire last.
Why does GenericWebHostSevice execute last?
The order that IHostedServices are executed depends on the order that they're added to the DI container in Startup.ConfigureServices(). For example, if you register two services in Startup.cs, Service1 and Service2:
public class Startup
{
public void ConfigureServices(IServiceCollection services)
{
services.AddHostedService<Service1>();
services.AddHostedService<Service2>();
}
}
then they'll be executed in that order on startup:
info: HostedServiceOrder.Service1[0] # Registered first
Starting Service1
info: HostedServiceOrder.Service2[0] # Registered last
Starting Service2
info: Microsoft.Hosting.Lifetime[0] # The GenericWebHostSevice
Now listening on: http://localhost:5000
The GenericWebHostSevice is registered after the services in Startup.ConfigureServices(), when you call ConfigureWebHostDefaults() in Program.cs:
public class Program
{
public static void Main(string[] args)
=> CreateHostBuilder(args).Build().Run();
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder => // The GenericWebHostSevice is registered here
{
webBuilder.UseStartup<Startup>();
});
}
The ConfigureWebHostDefaults extension method calls the ConfigureWebHost method, which executes Startup.ConfigureServices() and then registers the GenericWebHostService.
public static IHostBuilder ConfigureWebHost(this IHostBuilder builder, Action<IWebHostBuilder> configure)
{
var webhostBuilder = new GenericWebHostBuilder(builder);
// This calls the lambda function in Program.cs, and registers your services using Startup.cs
configure(webhostBuilder);
// Adds the GenericWebHostService
builder.ConfigureServices((context, services) => services.AddHostedService<GenericWebHostService>());
return builder;
}
This approach was taken to ensure that the GenericWebHostService always runs last, to keep behaviour consistent between the generic Host implementation and the (now deprecated) WebHost implementation.
However, if you need to run an IHostedService after GenericWebHostService, there's a way!
Registering IHostedServices in Program.cs
In most cases, starting your IHostedServices before the GenericWebHostService is the behaviour you want. However, the GenericWebHostService is also responsible for building the middleware pipeline of your application. If your IHostedService relies on the middleware pipeline or routing, then you may need to delay it starting until after the GenericWebHostService.
A good example of this would be the "duplicate route detector" I described in a previous post. This relies on the routing tables that are constructed when the middleware pipeline is built.
The only way to have your IHostedService executed after the GenericWebHostService is to add it to the DI container after the GenericWebHostService. That means you have to step outside the familiar Startup.ConfigureServices(), and instead call ConfigureServices() directly on the IHostBuilder, after the call to ConfigureWebHostDefaults:
public class Program
{
public static void Main(string[] args)
=> CreateHostBuilder(args).Build().Run();
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder => // The GenericWebHostSevice is registered here
{
webBuilder.UseStartup<Startup>();
})
// Register your HostedService AFTER ConfigureWebHostDefaults
.ConfigureServices(
services => services.AddHostedService<ProgramHostedService>());
}
There's nothing special about the
ConfigureServices()methods onIHostBuilder, so you could do all your DI configuration in these extensions if you wanted - that's how worker services do it after all!
Now if you run your application, you'll see that the "startup" IHostedService runs first, followed by the GenericWebHostSevice, and finally the "program" IHostedService:
info: HostedServiceOrder.StartupHostedService[0] # Registered in Startup.cs
Starting IHostedService registered in Startup
info: Microsoft.Hosting.Lifetime[0] # Registered by ConfigureWebHostDefaults
Now listening on: http://localhost:5000
info: HostedServiceOrder.ProgramHostedService[0] # Registered in Program.cs
Starting IHostedService registered in Program.cs
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
When you shut down your application, the IHostedServices are stopped in reverse, so the "program" IHostedService stops first, followed by the GenericWebHostSevice, and finally the "startup" IHostedService:
info: Microsoft.Hosting.Lifetime[0]
Application is shutting down...
info: HostedServiceOrder.ProgramHostedService[0]
StoppingIHostedService registered in Program.cs
# The GenericWebHostSevice doesn't write any logs when shutting down...
info: HostedServiceOrder.StartupHostedService[0]
StoppingIHostedService registered in Startup
That's all there is to it!
Summary
IHostedServices are executed in the same order as they're added to the DI container in Startup.ConfigureServices(). The GenericWebHostSevice which runs the Kestrel server that listens for HTTP requests always runs after any IHostedServices you register here.
To start an IHostedService after the GenericWebHostSevice, use the ConfigureServices() extension methods on IHostBuilder in Program.cs. Ensure you add the ConfigureServices() call after the call to ConfigureWebHostDefaults(), so that your IHostedService is added to the DI container after the GenericWebHostSevice.