![Creating an incremental generator]()
This post is my contribution to the .NET Advent calendar be sure to check there for other great posts!
In this post I describe how to create an incremental source generator. As a case study, I describe a source generator for generating an extension method for enums called ToStringFast(). This method is much faster than the built-in ToString() equivalent, and using a source generator means it's just as easy to use!
This is based on a source generator I created recently called NetEscapades.EnumGenerators. You can find it on GitHub or on NuGet.
I start by providing a small amount of background on source generators, and the problem with calling ToString() on an enum. For the remainder of the post, I walk step by step through creating an incremental generator. The final result is a working source generator, though with limitations, as I describe at the end of the post.
- Creating the Source generator project
- Collecting details about enums
- Adding a marker attribute
- Creating the incremental source generator
- Building the incremental generator pipeline
- Implementing the pipeline stages
- Parsing the EnumDeclarationSyntax to create an EnumToGenerate
- Generating the source code
- Limitations
Background: source generators
Source generators were added as a built-in feature in .NET 5. They perform code generation at compile time, providing the ability to add source code to your project automatically. This opens up a vast realm of possibilities, but the ability to use source generators to replace things that would otherwise need to be done using reflection is a firm favourite.
I've written many posts about source generators already, for example:
If you're completely new to source generators, I recommend this intro to source generators talk by Jason Bock given at .NET Conf. It's only half an hour (he has a longer version of the talk too) and it will get you up and running quickly.
In .NET 6, a new API was introduced for creating "incremental generators". These have broadly the same functionality as the source generators in .NET 5, but they are designed to take advantage of caching to significantly improve performance, so that your IDE doesn't slow down! The main downside to incremental generators is that they are only supported in the .NET 6 SDK (and so only in VS 2022).
The domain: enums and ToString()
The simple enum in c# is a handy little think for representing a choice of options. Under the hood, it's represented by a numeric value (typically an int), but instead of having to remember in your code that 0 represents "Red" and 1 represents "Blue", you can use an enum that holds that information for you:
public enum Colour
{
Red = 0,
Blue = 1,
}
In your code, you pass instances of the enum Colour around, but behind the scenes the runtime really just uses an int. The trouble is, sometimes you want to get the name of the colour. The built-in way to do that is to call ToString()
public void PrintColour(Colour colour)
{
Console.Writeline("You chose "+ colour.ToString());
}
That probably is all well known to anyone reading this post. But it's maybe less common knowledge that this is sloooow. We'll look at how slow shortly, but first we'll look at a fast implementation, using modern C#:
public static class EnumExtensions
{
public string ToStringFast(this Colour colour)
=> colour switch
{
Colour.Red => nameof(Colour.Red),
Colour.Blue => nameof(Colour.Blue),
_ => colour.ToString(),
}
}
}
This simple switch statement checks for each of the known values of Colour and uses nameof to return the textual representation of the enum. If it's an unknown value, then the underlying value is returned as a string.
You always have to be careful about these unknown values: for example this is valid C# PrintColour((Colour)123)
If we compare this simple switch statement to the default ToString() implementation using BenchmarkDotNet for a known colour, you can see how much faster our implementation is:
BenchmarkDotNet=v0.13.1, OS=Windows 10.0.19042.1348 (20H2/October2020Update)
Intel Core i7-7500U CPU 2.70GHz (Kaby Lake), 1 CPU, 4 logical and 2 physical cores
DefaultJob : .NET Framework 4.8 (4.8.4420.0), X64 RyuJIT
.NET SDK=6.0.100
DefaultJob : .NET 6.0.0 (6.0.21.52210), X64 RyuJIT
| Method |
FX |
Mean |
Error |
StdDev |
Ratio |
Gen 0 |
Allocated |
| EnumToString |
net48 |
578.276 ns |
3.3109 ns |
3.0970 ns |
1.000 |
0.0458 |
96 B |
| ToStringFast |
net48 |
3.091 ns |
0.0567 ns |
0.0443 ns |
0.005 |
- |
- |
| EnumToString |
net6.0 |
17.9850 ns |
0.1230 ns |
0.1151 ns |
1.000 |
0.0115 |
24 B |
| ToStringFast |
net6.0 |
0.1212 ns |
0.0225 ns |
0.0199 ns |
0.007 |
- |
- |
First off, it's worth pointing out that ToString() in .NET 6 is over 30× faster and allocates only a quarter of the bytes than the method in .NET Framework! Compare that to the "fast" version though, and it's still super slow!
As fast as it is, creating the ToStringFast() method is a bit of a pain, as you have to make sure to keep it up to date as your enum changes. Luckily, that's a perfect usecase for a source generator!
I'm aware of a couple of enum generators from the community, namely this one and this one, but neither of them did quite I wanted, so I made my own!
In this post, we'll walk through creating a source generator to generate the ToStringFast() method, using the new incremental source generators supported in the .NET 6 SDK.
1. Creating the Source generator project
To get started we need to create a C# project. Source generators must target netstandard2.0, and you'll need to add some standard packages to get access to the source generator types.
Start by creating a class library. The following uses the sdk to create a solution and a project in the current folder:
dotnet new sln -n NetEscapades.EnumGenerators
dotnet new classlib -o ./src/NetEscapades.EnumGenerators
dotnet sln add ./src/NetEscapades.EnumGenerators
Replace the contents of NetEscapades.EnumGenerators.csproj with the following. I've described what each of the properties do in comments:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<IncludeBuildOutput>false</IncludeBuildOutput>
<Nullable>enable</Nullable>
<ImplicitUsings>true</ImplicitUsings>
<LangVersion>Latest</LangVersion>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.Analyzers" Version="3.3.2" PrivateAssets="all" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.0.1" PrivateAssets="all" />
</ItemGroup>
<ItemGroup>
<None Include="$(OutputPath)\$(AssemblyName).dll" Pack="true"
PackagePath="analyzers/dotnet/cs" Visible="false" />
</ItemGroup>
</Project>
This is pretty much just all boilerplate for now, so lets get onto the code.
2. Collecting details about enums
Before we build the generator itself, lets consider the extension method we're trying to create. At a minimum, we need to know:
- The full
Type name of the enum
- The name of all the values
And that's pretty much it. There's lots of more information we could collect for a better user experience, but for now, we'll stick with that, to get something working. Given that, we can create a simple type to hold the details about the enums we discover:
public readonly struct EnumToGenerate
{
public readonly string Name;
public readonly List<string> Values;
public EnumToGenerate(string name, List<string> values)
{
Name = name;
Values = values;
}
}
3. Adding a marker attribute
We also need to think about how we are going to choose which enums to generate the extension methods for. We could do it for every enum in the project, but that seems a bit overkill. Instead, we could use a "marker attribute". A marker attribute is a simple attribute that doesn't have any functionality, and only exists so that something else (in this case, our source generator) can locate the type. Users would decorate their enum with the attribute, so we know to generate the extension method for it:
[EnumExtensions]
public enum Colour
{
Red = 0,
Blue = 1,
}
We'll create a simple marker attribute as shown below, but we're not going to define this attribute in code directly. Rather, we're creating a string containing c# code for the [EnumExtensions] marker attribute. We'll make the source generator automatically add this to the compilation of consuming projects at runtime so the attribute is available.
public static class SourceGenerationHelper
{
public const string Attribute = @"
namespace NetEscapades.EnumGenerators
{
[System.AttributeUsage(System.AttributeTargets.Enum)]
public class EnumExtensionsAttribute : System.Attribute
{
}
}";
}
We'll be adding more to this SourceGenerationHelper class later, but for now it's time to create the actual generator itself.
4. Creating the incremental source generator
To create an incremental source generator, you need to do 3 things:
- Include the Microsoft.CodeAnalysis.CSharp package in your project. Note that incremental generators were introduced in version 4.0.0, and are only supported in .NET 6/VS 2022.
- Create a class that implements
IIncrementalGenerator
- Decorate the class with the
[Generator] attribute
We've already done the first step, so let's create our EnumGenerator implementation:
namespace NetEscapades.EnumGenerators;
[Generator]
public class EnumGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(ctx => ctx.AddSource(
"EnumExtensionsAttribute.g.cs",
SourceText.From(SourceGenerationHelper.Attribute, Encoding.UTF8)));
}
}
IIncrementalGenerator only requires you implement a single method, Initialize(). In this method you can register your "static" source code (like the marker attributes), as well as build a pipeline for identifying syntax of interest, and transforming that syntax into source code.
In the implementation above, I've already added the code that registers our marker attribute to the compilation. In the next section we'll build up the code to identify enums that have been decorated with the marker attribute.
5. Building the incremental generator pipeline
One of the key things to remember when building source generators, is that there are a lot of changes happening when you're writing source code. Every change the user makes could trigger the source generator to run again, so you have to be efficient, otherwise you're going to kill the user's IDE experience
This isn't just anecdotal, the preview versions of the [LoggerMessage] generator ran into exactly this problem.
The design of incremental generators is to create a "pipeline" of transforms and filters, memoizing the results at each layer to avoid re-doing work if there are no changes. It's important that the stage of the pipeline is very efficient, as this will be called a lot, ostensibly for every source code change. Later layers need to remain efficient, but there's more leeway there. If you've designed your pipeline well, later layers will only be called when users are editing code that matters to you.
I wrote about this design in a recent blog post.
With that in mind (and taking inspiration from the [LoggerMessage] generator) we'll create a simple generator pipeline that does the following:
- Filter syntax to only
enums which have one or more attributes. This should be very fast, and will contain all the enums we're interested in.
- Filter syntax to only
enums which have the [EnumExtensions] attribute. This is slightly more costly than the first stage, as it uses the semantic model (not just syntax), but is still not very expensive.
- Extract all the information we need using the
Compilation. This is the most expensive step, and it combines the Compilation for the project with the previously-selected enum syntax. This is where we can create our collection of EnumToGenerate, generate the source, and register it as a source generator output.
In code, the pipeline is shown below. The three steps above correspond to the IsSyntaxTargetForGeneration(), GetSemanticTargetForGeneration() and Execute() methods respectively, which we'll show in the next section.
namespace NetEscapades.EnumGenerators;
[Generator]
public class EnumGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(ctx => ctx.AddSource(
"EnumExtensionsAttribute.g.cs",
SourceText.From(SourceGenerationHelper.Attribute, Encoding.UTF8)));
IncrementalValuesProvider<EnumDeclarationSyntax> enumDeclarations = context.SyntaxProvider
.CreateSyntaxProvider(
predicate: static (s, _) => IsSyntaxTargetForGeneration(s),
transform: static (ctx, _) => GetSemanticTargetForGeneration(ctx))
.Where(static m => m is not null)!;
IncrementalValueProvider<(Compilation, ImmutableArray<EnumDeclarationSyntax>)> compilationAndEnums
= context.CompilationProvider.Combine(enumDeclarations.Collect());
context.RegisterSourceOutput(compilationAndEnums,
static (spc, source) => Execute(source.Item1, source.Item2, spc));
}
}
The first stage of the pipeline uses CreateSyntaxProvider() to filter the incoming list of syntax tokens. The predicate, IsSyntaxTargetForGeneration(), provides a first layer of filtering. The transform, GetSemanticTargetForGeneration(), can be used to transform the syntax tokens, but in this case we only use it to provide additional filtering after the predicate. The subsequent Where() clause looks like LINQ, but it's actually a method on IncrementalValuesProvider which does that second layer of filtering for us.
The next stage of the pipeline simply combines our collection of EnumDeclarationSyntax emitted from the first stage, with the current Compilation.
Finally, we use the combined tuple of (Compilation, ImmutableArray<EnumDeclarationSyntax>) to actually generate the source code for the EnumExtensions class, using the Execute() method.
Now let's take a look at each of those methods.
6. Implementing the pipeline stages
The first stage of the pipeline needs to be very fast, so we operate solely on the SyntaxNode passed in, filtering down to select only EnumDeclarationSyntax nodes, which have at least one attribute:
static bool IsSyntaxTargetForGeneration(SyntaxNode node)
=> node is EnumDeclarationSyntax m && m.AttributeLists.Count > 0;
As you can see, this is a very efficient predicate. It's using a simple pattern match to check the type of the node, and checking the properties.
In C# 10 you could also write that as node is EnumDeclarationSyntax { AttributeLists.Count: > 0 }, but personally I prefer the former.
After this efficient filtering has run, we can be a bit more critical. We don't want any attribute, we only want our specific marker attribute. In GetSemanticTargetForGeneration() we loop through each of the nodes that passed the previous test, and look for our marker attribute. If the node has the attribute, we return the node so it can take part in further generation. If the enum doesn't have the marker attribute, we return null, and filter it out in the next stage.
private const string EnumExtensionsAttribute = "NetEscapades.EnumGenerators.EnumExtensionsAttribute";
static EnumDeclarationSyntax? GetSemanticTargetForGeneration(GeneratorSyntaxContext context)
{
var enumDeclarationSyntax = (EnumDeclarationSyntax)context.Node;
foreach (AttributeListSyntax attributeListSyntax in enumDeclarationSyntax.AttributeLists)
{
foreach (AttributeSyntax attributeSyntax in attributeListSyntax.Attributes)
{
if (context.SemanticModel.GetSymbolInfo(attributeSyntax).Symbol is not IMethodSymbol attributeSymbol)
{
continue;
}
INamedTypeSymbol attributeContainingTypeSymbol = attributeSymbol.ContainingType;
string fullName = attributeContainingTypeSymbol.ToDisplayString();
if (fullName == "NetEscapades.EnumGenerators.EnumExtensionsAttribute")
{
return enumDeclarationSyntax;
}
}
}
return null;
}
Note that we're still trying to be efficient where we can, so we're using foreach loops, rather than LINQ.
After we've run this stage of the pipeline, we will have a collection of EnumDeclarationSyntax that we know have the [EnumExtensions] attribute. In the Execute method, we create an EnumToGenerate to hold the details we need from each enum, pass that to our SourceGenerationHelper class to generate the source code, and add it to the compilation output
static void Execute(Compilation compilation, ImmutableArray<EnumDeclarationSyntax> enums, SourceProductionContext context)
{
if (enums.IsDefaultOrEmpty)
{
return;
}
IEnumerable<EnumDeclarationSyntax> distinctEnums = enums.Distinct();
List<EnumToGenerate> enumsToGenerate = GetTypesToGenerate(compilation, distinctEnums, context.CancellationToken);
if (enumsToGenerate.Count > 0)
{
string result = SourceGenerationHelper.GenerateExtensionClass(enumsToGenerate);
context.AddSource("EnumExtensions.g.cs", SourceText.From(result, Encoding.UTF8));
}
}
We're getting close now, we just have two more methods to fill in:GetTypesToGenerate(), and SourceGenerationHelper.GenerateExtensionClass().
7. Parsing the EnumDeclarationSyntax to create an EnumToGenerate
The GetTypesToGenerate() method is where most of the typical work associated with working with Roslyn happens. We need to use the combination of the syntax tree and the semantic Compilation to get the details we need, namely:
- The full type name of the
enum
- The name of all the values in the
enum
The following code loops through each of the EnumDeclarationSyntax and gathers that data.
static List<EnumToGenerate> GetTypesToGenerate(Compilation compilation, IEnumerable<EnumDeclarationSyntax> enums, CancellationToken ct)
{
var enumsToGenerate = new List<EnumToGenerate>();
INamedTypeSymbol? enumAttribute = compilation.GetTypeByMetadataName("NetEscapades.EnumGenerators.EnumExtensionsAttribute");
if (enumAttribute == null)
{
return enumsToGenerate;
}
foreach (EnumDeclarationSyntax enumDeclarationSyntax in enums)
{
ct.ThrowIfCancellationRequested();
SemanticModel semanticModel = compilation.GetSemanticModel(enumDeclarationSyntax.SyntaxTree);
if (semanticModel.GetDeclaredSymbol(enumDeclarationSyntax) is not INamedTypeSymbol enumSymbol)
{
continue;
}
string enumName = enumSymbol.ToString();
ImmutableArray<ISymbol> enumMembers = enumSymbol.GetMembers();
var members = new List<string>(enumMembers.Length);
foreach (ISymbol member in enumMembers)
{
if (member is IFieldSymbol field && field.ConstantValue is not null)
{
members.Add(member.Name);
}
}
enumsToGenerate.Add(new EnumToGenerate(enumName, members));
}
return enumsToGenerate;
}
The only thing remaining is to actually generate the source code from our List<EnumToGenerate>!
8. Generating the source code
The final method SourceGenerationHelper.GenerateExtensionClass() shows how we take our list of EnumToGenerate, and generate the EnumExtensions class. This one is relatively simple conceptually (though a little hard to visualise!), as it's just building up a string:
public static string GenerateExtensionClass(List<EnumToGenerate> enumsToGenerate)
{
var sb = new StringBuilder();
sb.Append(@"
namespace NetEscapades.EnumGenerators
{
public static partial class EnumExtensions
{");
foreach(var enumToGenerate in enumsToGenerate)
{
sb.Append(@"
public static string ToStringFast(this ").Append(enumToGenerate.Name).Append(@" value)
=> value switch
{");
foreach (var member in enumToGenerate.Values)
{
sb.Append(@"
").Append(enumToGenerate.Name).Append('.').Append(member)
.Append(" => nameof(")
.Append(enumToGenerate.Name).Append('.').Append(member).Append("),");
}
sb.Append(@"
_ => value.ToString(),
};
");
}
sb.Append(@"
}
}");
return sb.ToString();
}
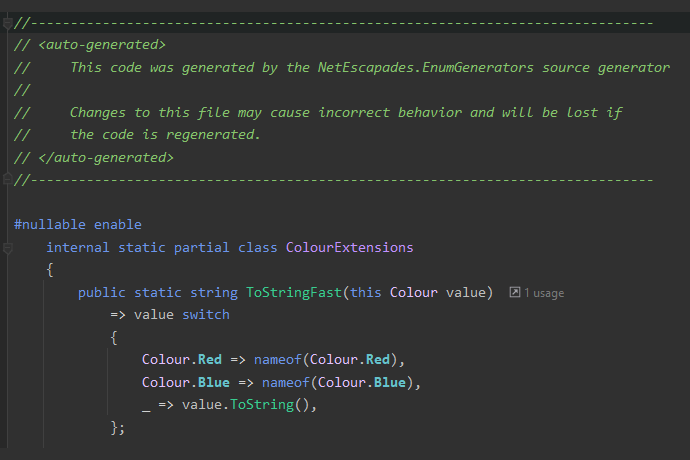
And we're done! We now have a fully functioning source generator. Adding the source generator to a project containing the Colour enum from the start of the post will create an extension method like the following:
public static class EnumExtensions
{
public string ToStringFast(this Colour colour)
=> colour switch
{
Colour.Red => nameof(Colour.Red),
Colour.Blue => nameof(Colour.Blue),
_ => colour.ToString(),
}
}
}
Limitations
With your source generator complete, you can package it up by running dotnet pack -c Release, and upload to NuGet!
Hold on, don't actually do that.
There's a whole load of limitations to this code, not least the fact we haven't actually tested it yet. Off the top of my head:
- The
EnumExtensions class is always called the same thing, and is always in the same namespace. It would be nice for the user to be able to control that
- We haven't considered the visibility of the
enum. If the enum is internal, the generated code won't compile, as it's a public extension method
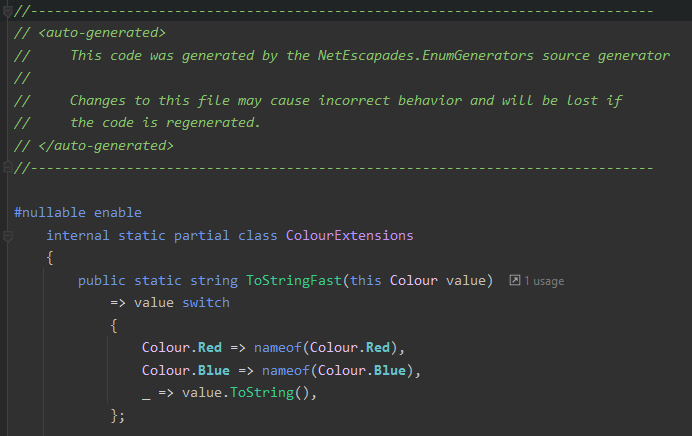
- We should mark the code as autogenerated and with
#nullable enable as the code formatting might not match the project conventions
- We haven't tested it, so we don't know if it actually works!
- Adding marker attributes directly to the compilation can sometimes be an issue, more about this one in a later post.
That said, this has hopefully still been useful. I will address many of the above issues in future posts, but the code in this post should provide a good framework if you're looking to create your own incremental generator.
Summary
In this post I described all the steps required to create an incremental generator. I showed how to create the project file, how to add a marker attribute to the compilation, how to implement IIncrementalGenerator, and how to keep performance in mind to ensure consumers of your generator don't experience lag in their IDE. The resulting implementation has many limitations, but it shows the basic process. In future posts in this series, we'll address many of these limitations.
You can find my NetEscapades.EnumGenerators project on GitHub, and the source code for the basic stripped down version of it used in this post in my blog samples.