In this post I deal with a classic thorny issue that quickly arises when you deploy to a highly-replicated production environment: database migrations.
I discuss various possible solutions to the problem, including simple options as well as more complex approaches. Finally I discuss the approach that I've settled on in production: using Kubernetes Jobs and init containers. With the proposed solution (and careful database schema design!) you can perform rolling updates of your application that includes database migrations.
The classic problem: an evolving database
The problem is very common—the new version of your app uses a slightly different database schema to the previous version. When you deploy your app, you need to also update the database. Theses are commonly called database migrations, and are a reality for any evolving application.
There are many different approaches to creating those database migrations. EF Core, for example, automatically generates migrations to evolve your database. Alternatively, there are libraries you can use such as DbUp or FluentMigrator that allow you to define your migrations in code or as SQL scripts, and apply changes to your database automatically.
All these solutions keep track of which migrations have already been run against your database and which are new migrations that need to be run, as well as actually executing the migrations against your database. What these tools don't control is when they run the migrations.
A trivial migration strategy
The question of when to run database migrations might seem to have an obvious answer: before the new application that runs them starts. But there's some nuance to that answer, which becomes especially hard in a web-farm scenario, where you have multiple instances of your application.
One of the simplest options would be:
- Divert traffic to a "holding" website
- Stop your application
- Run the database migrations
- Start the new version of your application
- Divert traffic to the new version
Clearly this isn't an acceptable approach in the current always-on world most businesses work in, but for your simple, low-traffic, side-project, it'll probably do the job. This just skirts around the problem rather than solving it though, so I won't be discussing this solution further.
The discussions and options I'm describing here generally apply in any web-farm scenario, but I'm going to use Kubernetes terminology and examples seeing as this is a series about Kubernetes!
If you're not going to use this approach, and instead want to do zero-downtime migrations, then you have to accept the fact that during those migration periods, code is always going to run against multiple versions of the database.
Making database migrations safe
Let's use a concrete example. Imagine you are running a blogging platform, and you want to add a new feature to your BlogPost entity: Category. Each blog post can be assigned to a single top-level category, so you add a categories table containing the list of categories, and a category_id column to your blog_posts table, referencing the categories table.
Now lets think about how we deploy this. We have two "states" for the code:
- Before the code for working with
Categorywas added - After the code for working with
Categorywas added.
There's also two possible states for the database:
- The database without the
categoriestable andcategory_idcolumn - The database with the
categoriestable andcategory_idcolumn
In terms of the migration, you have two options:
Deploy the new code first, and then run the database migrations. In which case, the before code only has to work with the database without the categories table, but the after code has to work with both database schemas.
Run the database migrations first, before you deploy the new code. This means the before code must work with both database schemas, but the after code can assume that the tables have already been added.

You can use either approach for your migrations, but I prefer the latter. Database migrations are typically the most risky part of deployment, so I like to do them first—if there's a problem, the deployment will fail, and the new code will never be deployed.
In practical terms, the fact that your new database schema needs to be compatible with the previous version of the software generally means you can't introduce NOT NULL columns to existing tables, as code that doesn't know about the columns will fail to insert. Your main options are either make the column nullable (and potentially make it required in a subsequent deploy) or configure a default in the database, so that the column is never null.
Generally, as long as you keep this rule in mind, database migrations shouldn't cause you too much trouble. When writing your migration just think: "if I only run the database migration, will the existing code keep break?" If the answer is "no", then you should be fine.
Choosing when to run migrations
We've established that we want to run database migrations before our new code starts running, but that still gives a fair bit of leeway. I see three main approaches
- Running migrations on application startup
- Running migrations as part of the deployment process script
- Running migrations using Kubernetes Jobs and init containers
Each of these approaches has benefits and trade-offs, so I'll discuss each of them in turn.
So we have something concrete to work with, lets imagine that your blogging application is deployed to Kubernetes. You have an ingress, a service, and a deployment, as I've discussed previously in this series. The deployment ensures you keep 3 replicas of your application running at any one time to handle web traffic

You need to run database migrations when you deploy a new version of your app. Lets walk through the various options available.
Running migrations on application startup
The first, and most obvious, option is to run your database migrations when your application starts up. You can do this with EF Core by calling DbContext.Database.Migrate():
public static void Main(string[] args)
{
var host = CreateHostBuilder(args).Build();
using (var scope = host.Services.CreateScope())
{
var db = scope.ServiceProvider.GetRequiredService<ApplicationDbContext>();
db.Database.Migrate(); // apply the migrations
}
host.Run(); // start handling requests
}
Despite being the most obvious option, this has some important problems:
- Every instance of the application will attempt to migrate the database
- The application has permissions to perform destructive updates to the database
The first point is the most obvious issue: if we have 3 replicas, and we try and perform a rolling update then we may end up with multiple applications trying to migrate the database at the same time. This is unsupported in every migration tool I know of, and carries the risk of data corruption.
There are ways you could try and ensure only one new instance of the app runs the migrations, but I'm not convinced by any of them, and I'd rather not take the chance of screwing up my database!
The second point is security related. Migrations are, by necessity, dangerous, as they have the potential for data loss and corruption. A good practice is to use a different database account for running migrations than you use in the normal running of your application. That reduces the risk of accidental (or malicious) data loss when your app is executing—if the application doesn't have permission to DROP tables, then there's no risk of that accidentally happening.
If your app is responsible for both running migrations and running your code, then by necessity, it must have access to privileged credentials. You can ensure that only the migrations use the privileged account, but a more foolproof approach is to not allow access to those credentials at all.
Running migrations as part of the deployment process script
Another common approach is to run migrations as part of the deployment process, such as an Octopus Deploy deployment plan. This solves both of the issues I described in the previous section—you can ensure that Octopus won't run migrations concurrently, and once the database migrations are complete, it will deploy your application code. Similarly, as the migration are separate from your code, it's easier to use a different set of credentials.
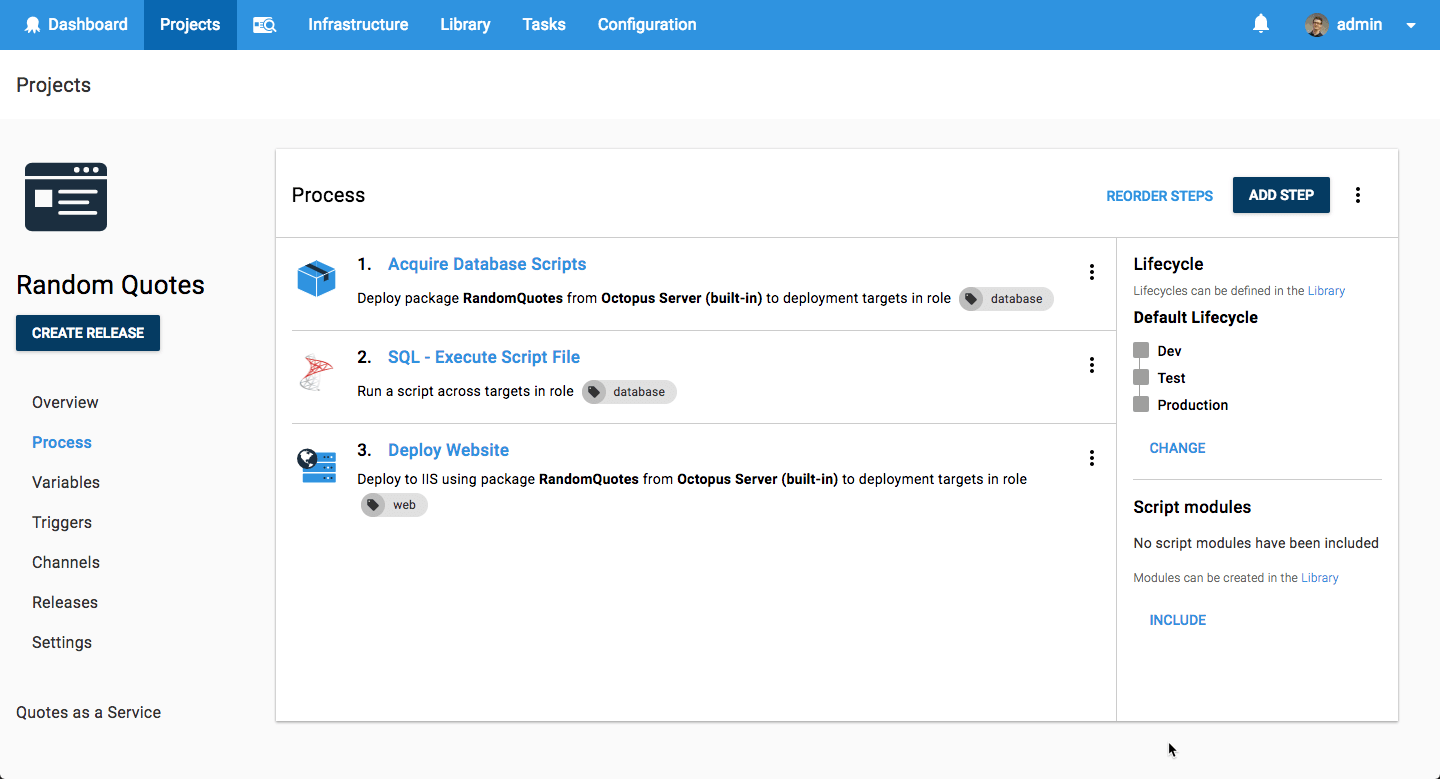
This leaves the question of how to run the migrations, and what does it actually mean for Octopus to run the migrations? In the example above, Octopus acquires migration scripts and applies them to the database directly. On the plus side, this makes it easy to get started, and removes the need to handle running migrations directly in your application code. However, it couples you very strongly to Octopus. That may or may not be a trade-off you're happy with.
Instead, my go-to approach is to use a simple .NET Core CLI application as a "database runner". In fact, I typically make this a "general purpose" command runner, for example using Jeremy D Miller's Oakton project, so I can use it for running one-off ad-hoc commands too.
This post is long enough, so I'm not going to show how to write a CLI tool like that here. That said, it's a straight forward .NET Core command line project, so there shouldn't be any gotchas.
If you use this approach then the question remains: where do you run the CLI tool? Your CLI project has to actually run on a machine somewhere, so you'll need to take that into account. Serverless is probably no good either, as your migrations will likely be too long-running.
Octopus can certainly handle all this for you, and if you're already using it, this is probably the most obvious solution.
There is an entirely Kubernetes-based solution though, which is the approach I've settled on.
Using Kubernetes Jobs and init containers
My preferred solution uses two Kubernetes-native constructs: Jobs and init containers.
Jobs
A Kubernetes job executes one or more pods to completion, optionally retrying if the pod indicates it failed, and then completes when the pod exits gracefully.
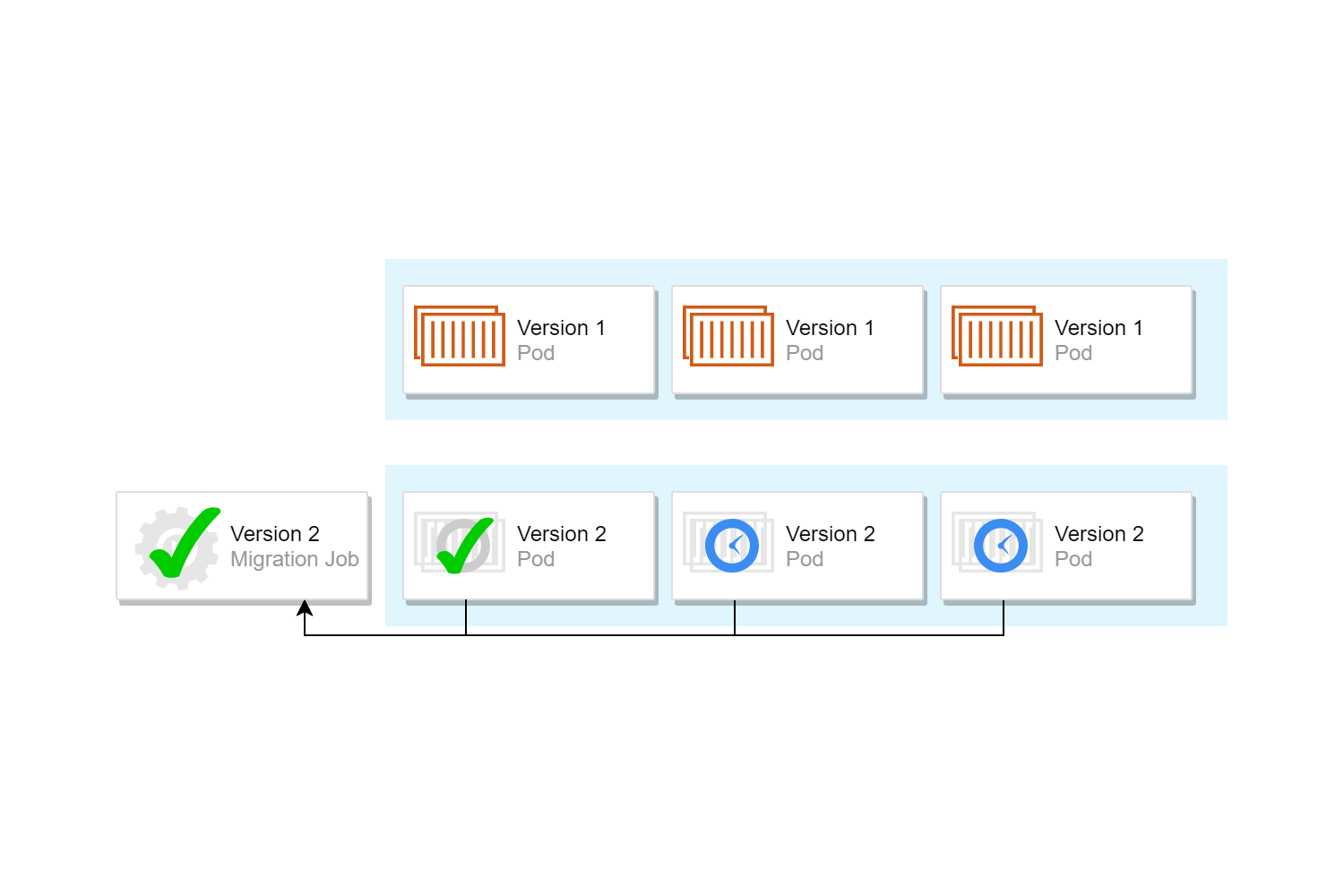
This is exactly what we want for database migrations—we can create a job that executes the database migration CLI tool, optionally retrying to handle transient network issues. As it's a "native" Kubernetes concept, we can also template it with Helm charts, including it in our application's helm chart. In the image below I've extended the test-app helm chart from a previous post by adding a CLI tool project with a job.yaml chart (I'll show the chart in detail in the next post in the series).

The difficulty is ensuring that the Job executes and completes before your other applications start. The approach I've settled on uses init Containers, another Kubernetes concept.
Init Containers
If you remember back to the first post in this series, I said that a Pod is the smallest unit of deployment in Kubernetes, and can contain one or more containers. In most cases a Pod will contain a single "main" container that provides the pod's functionality, and optionally one or more "sidecar" containers that provide additional capability to the main container, such as metrics or service-mesh capability.
You can also include init containers in a pod. When Kubernetes deploys a pod, it executes all the init containers first. Only once all of those containers have exited gracefully (i.e. not crashed) will the main container be executed. They're often used for downloading or configuring pre-requisites required by the main container. That keeps your container application focused on it's one job, instead of having to configure its environment too.
Combining jobs and init containers to handle migrations
Initially, when first exploring init containers, I tried using init containers as the mechanism for running database migrations directly, but this suffers from the same concurrency issues as running on app-startup: when you have multiple pods, every pod tries to run migrations at the same time. Instead, we switched to a two step approach: we use init containers to delay our main application from starting until a Kubernetes Job has finished executing the migrations.
The process (also shown in the image below) looks something like this:
- The Helm chart for the application consists of one or more "application" deployments, and a "migration" Job.
- Each application pod contains an init container that sleeps until the associated Job is complete. When the init container detects the Job is complete, it exits, and the main application containers start.
- As part of a rolling update, the migration job is deployed, and immediately starts executing. Instances of the new application are created, but as the migration Job is running, the init containers are sleeping, and the new application containers are not run. The old-version instances of the application are unaffected, and continue to handle traffic.
- The migration job migrates the database to the latest version, and exits.
- The init containers see that the job has succeeded, and exit. This allows the application containers to startup, and start handling traffic.
- The remaining old-version pods are removed using a rolling update strategy.

As I say, this approach is one that I've been using successfully for several years now, so I think it does the job. In the next post I'll go into the details of actually implementing this approach.
Before we finish, I'll discuss one final approach: using Helm Chart Hooks.
Helm Chart Hooks
On paper, Helm Chart Hooks appear to do exactly what we're looking for: they allow you to run a Job as part of installing/upgrading a chart, before the main deployment happens.
In my first attempts at handling database migrations, this was exactly the approach I took. You can convert a standard Kubernetes Job into a Helm Hook by adding an annotation, to the job's YAML for example:
apiVersion: batch/v1
kind: Job
metadata:
name: "{{ .Release.Name }}"
annotations:
# This is what defines this resource as a hook
"helm.sh/hook": pre-install
...
Simply adding that line ensures that Helm doesn't deploy the resource as part of the normal chart install/upgrade process. Instead, it deploys the job before the main chart, and waits for the job to finish. Once the job completes successfully, the chart is installed, performing a rolling update of your application. If the job fails, the chart install fails, and your existing deployment is unaffected.
My initial testing of this approach generally worked well, with one exception. If a database migration took a long time, Helm would timeout waiting for the job to complete, and would fail the install. In reality, the job may or may not succeed in the cluster.
This was a deal breaker for us. Random timeouts, and the reality that production environments (with the larger quantity of data and higher database loads) were likely to be slower for migrations made us look elsewhere. Ultimately we settled on the init container approach I described in the previous section.
I haven't looked at Helm Chart Hooks again in a while, so it's possible that this is no longer an issue, but I don't see anything addressing it in the documentation.
Summary
In this post I described the general approaches to running database migrations when deploying to Kubernetes. I discussed the need to write your database migrations to be compatible with multiple versions of your application code and described several approaches you could take.
My preferred approach is to build a CLI tool that is responsible for executing the application's database migrations, and to deploy this as a Kubernetes job. In addition, I include an init container inside each application's pod, which delays the start of the application container until after the job completes successfully.
In this post I just discussed the concepts—in the next post in this series I describe the implementation. I will show how to implement a Kubernetes Job as a Helm Chart and how to use init containers to control your application container startup process